How to use parsers and other tools to analyze JavaScript
Over 20 years after its creation, JavaScript is the most used language in the world. It is the only language that runs on the most popular platform (the web), it is more frequently the technology behind native applications (Visual Studio Code, Discord, and Slack), and powers critical mobile apps (Facebook, Skype, Tesla). Do you know what?s also grown popular? Bug bounty programs and discovering vulnerabilities that result in cold hard cash.
Any stereotypical hacker scene shown in a movie or on TV will, 100% of the time, show someone sitting in front of a terminal typing out cryptic commands on a black screen (unless you?re using the 3d unix UI from Jurassic Park).

This is not too far from the truth. The terminal is critical in most developer and hacker workflows but it hasn?t scaled well to analyzing web apps. The core tools in every hacker?s toolbox are ill-suited or overly complex when it comes to analyzing, intercepting, and manipulating browser based applications. JavaScript and HTML themselves are complicated languages that you can?t parse and process with simple tools.
A great example of what doesn?t scale is using regular expressions to process JavaScript. This tweet made the rounds on hacker twitter in late June:
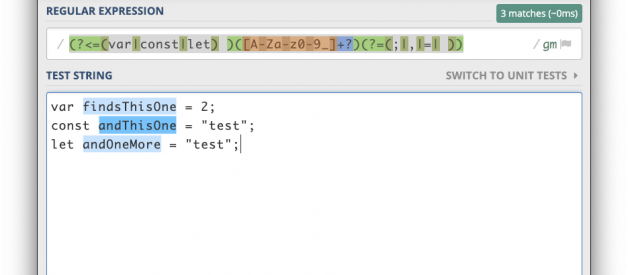
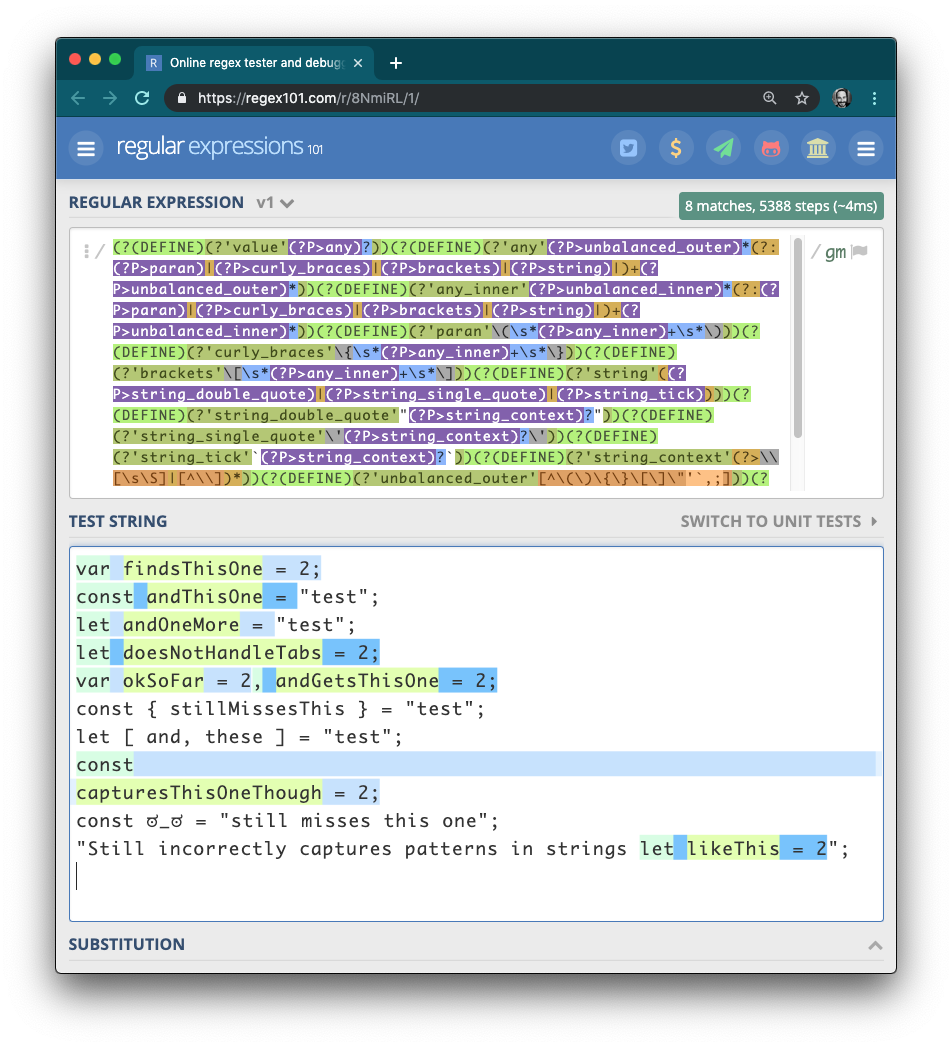
This regular expression attempts to capture all assigned variables in a JavaScript source file. Sweeping analysis like this is common to get a birds-eye view of an application and identify easy targets to focus effort. This regular expression is effective at catching common cases like below:
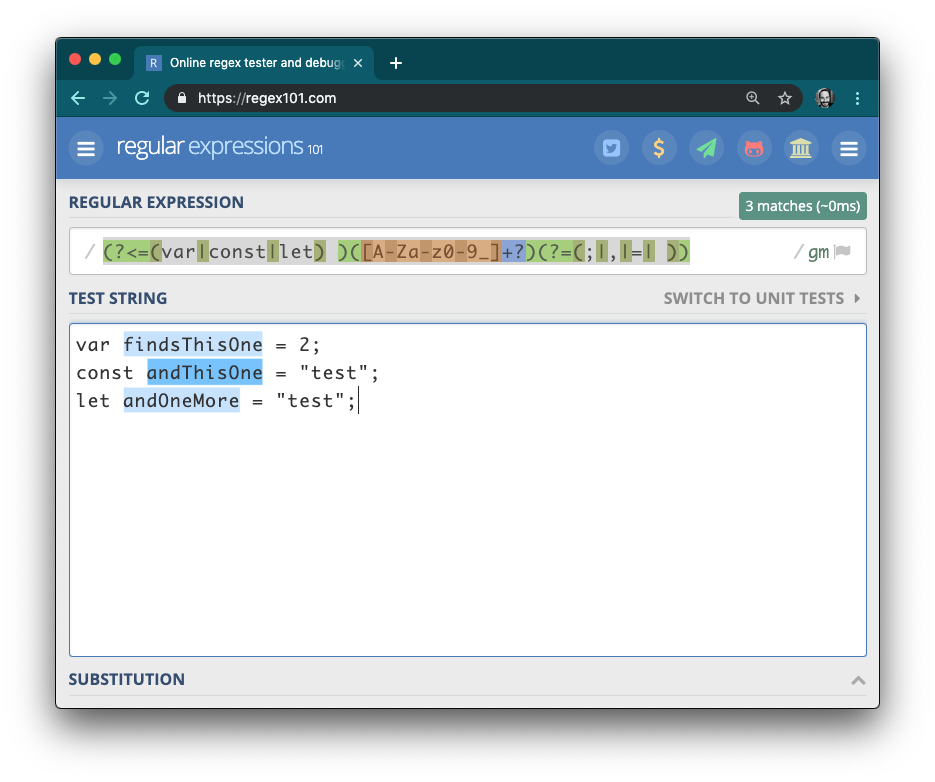
The regular expression breaks down with slightly more complex cases:
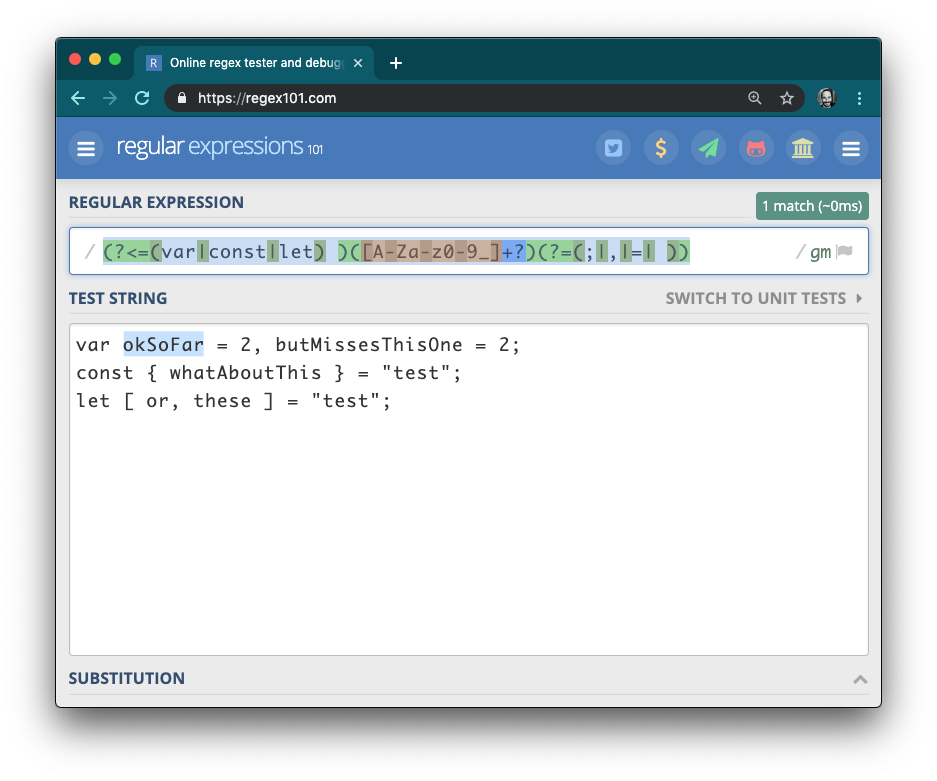
And it misses and incorrectly captures edge cases:
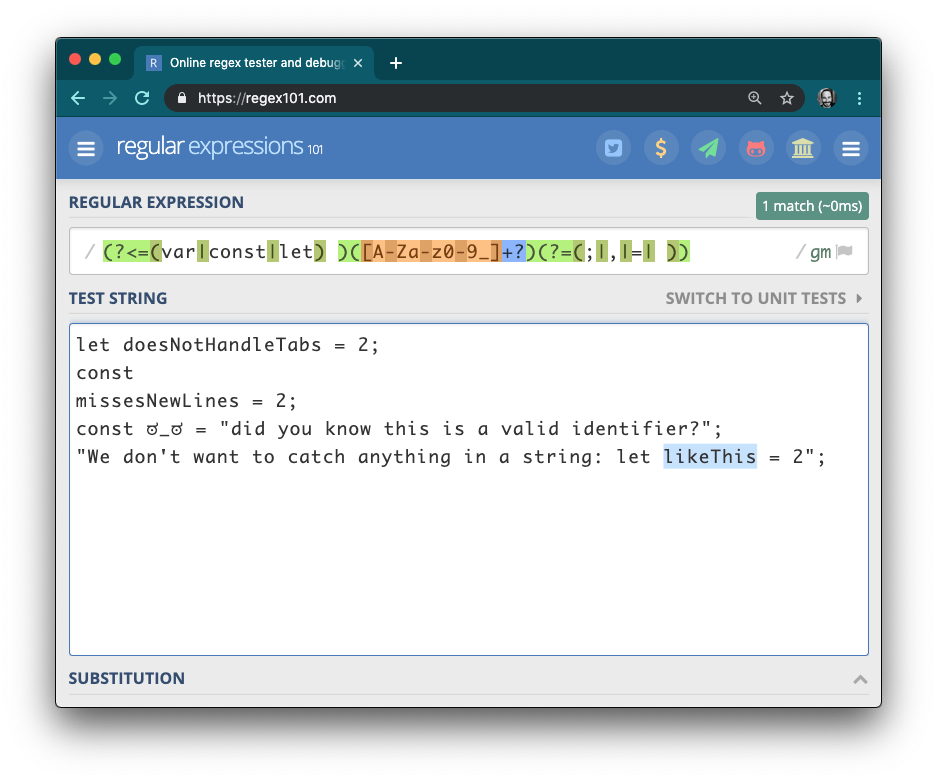
Another user dramatically improved the original regular expression while also dramatically increasing its complexity. Yet it still misses common usage and falls into edge case traps:
 https://twitter.com/d0nutptr/status/1143087965775679490
https://twitter.com/d0nutptr/status/1143087965775679490
The truth is regular expressions can not parse JavaScript. Full stop.
How to parse JavaScript
About a half-dozen ready-made JavaScript parsers are available in the node.js ecosystem. Others exist outside of node but if you plan to manipulate JavaScript you?re not going to find better tools in another language. The parsers are as simple to use as any other library but the complexity comes from understanding how to use their output. These JavaScript parsers produce an Abstract Syntax Tree, an AST. This is nothing more than a big fat object representing the input JavaScript. If you can look at raw HTTP requests and responses without freaking out then an AST shouldn?t scare you.
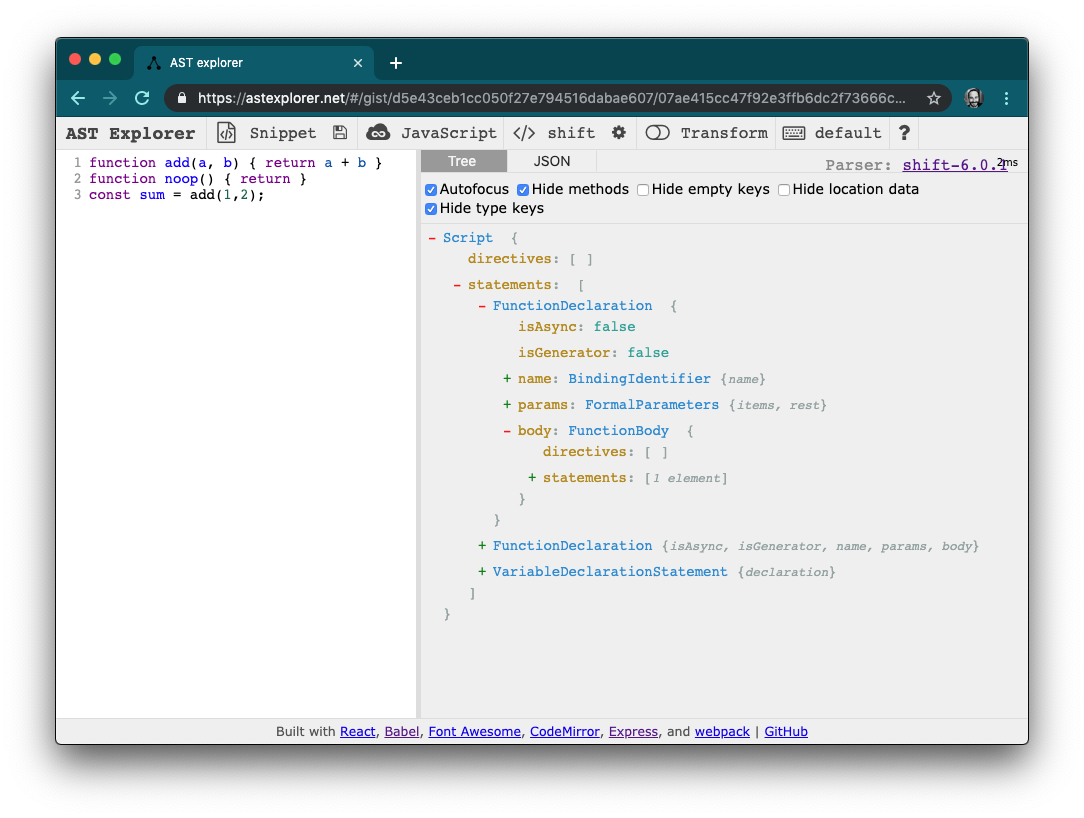
You can check out what an AST looks like via a tool like ASTExplorer.
 ASTExplorer.net
ASTExplorer.net
AST Explorer takes JavaScript entered on one side and displays the resulting AST on the right. You can also swap between parsers to compare and contrast ASTs if it ever becomes relevant.
Choosing a parser
All ASTs aren?t created equal. If you think about HTTP 1.0, 1.1, 2.0 etc, you wouldn?t expect that all tools designed to produce or accept one version will work seamlessly with all others. Parsers and ASTs are the same. At one point there was one standard but its deficiencies were so great that the community built out their own solutions and now there?s some fragmentation.
For all my work I use the Shift suite of tools because 1) I have fallen into the traps that common ASTs lead you into and 2) people I know and trust to steer me away from those traps wrote it. The Shift AST was the first (and only?) specification-based AST which means that the authors accounted for how to represent the entirety of ECMAScript before even starting on the problem of how to parse it. The authors of the first generation of JavaScript tooling developed it to normalize a lot of the edge cases found in other ASTs.
To use shift-parser you need to import the library and call its parse method on a string of JavaScript source. If you?re not familiar with using node and installing dependencies, install node via nvm and learn how to use npm here.
This code is all it takes to produce an AST for any JavaScript source.
const { parseScript } = require(“shift-parser”);const ast = parseScript(javascriptSource);
Going back to JavaScript from an AST
To take an AST and turn it back into source you?re going to want a code generator. This can be a little more complicated because how you want to format code is a matter of personal opinion. If you want source that is easy to read you?re going to want a code generator that properly indents the source at least. shift-codegen comes with two basic formatters and one extensible formatter. The following example code takes an AST produced by the parser and generates JavaScript source with shift-codegen. If you don?t care about the formatting then you can omit the FormattedCodeGen import and instantiation.
const { default: codegen, FormattedCodeGen } = require(‘shift-codegen’); console.log(codegen(ast, new FormattedCodeGen()));
Manipulating JavaScript via the AST
You can change the AST directly by hand as you would any other JavaScript object:
const { parseScript } = require(‘shift-parser’);const { default: codegen, FormattedCodeGen } = require(‘shift-codegen’);const source = `const myVar = “Hello World”;`const ast = parseScript(source);ast .statements[0] .declaration .declarators[0] .init .value = ‘Hello Reader’;console.log(codegen(ast, new FormattedCodeGen()));// > const myVar = “Hello Reader”;
As you can see navigating deeply into a large data structure is ugly and error prone. This can be useful when you know the data structure and know it won?t change but it?s not sufficient for writing general purpose tools. For that we?ll need a utility to traverse the tree for us. For that we?re going to use shift-traverser.
Traversing a tree
Shift-traverser is a utility I maintain which allows you to walk a Shift AST and manipulate nodes as you come across them. The library is a port of estraverse which you can use when walking a different AST format. If you are familiar with estraverse shift-traverser works the same way. You provide it with an AST object and an enter and an exit method. Shift-traverser calls these methods with the current node and its parent when the walker encounters a node for the first time and when the walker leaves a node permanently.
const { traverse } = require(“shift-traverser”);traverse(ast, { enter(node, parent) { }, exit(node, parent) { }});
Shift-traverser gives you flexible control to walk a tree and query individual nodes that interest you. This allows you to create logic that better adapts to any changes in the AST.
Wiring it all up together.
I started this post coming up with all the cases that a regular expression fails to parse JavaScript so how can we do it better with these tools? First we need to look for all variable declarations in our source. These all get parsed into VariableDeclaration nodes that include zero or more nodes of type VariableDeclarator. Think of the code let a = 2, b = 3. That is one variable declaration with two declarators. A VariableDeclarator contains a binding (binding) and an optional initial value (init). The binding can be a simple identifier (let a = 2) or it can also be an object or array pattern (let {c} = d, [a] = b;) so we’ll need to inspect the binding and account for the properties or elements there, respectively.
How did I know all this? I don?t know all the node types and what they contain by heart. I use AST Explorer to explore the nodes I want to analyze for the use case I?m interested in.
This is what the code looks like:
I published this code under the js-identifiers package on npm so you can reuse it as a command line utility. Think of it as strings but for JavaScript identifiers. How does it stack up against our evil example code?
$ js-identifiers scratch.jsfindsThisOneandThisOneandOneMoreokSoFarbutMissesThisOnewhatAboutThisorthesemissesTabsmissesNewLines?_?
It catches all the identifiers and omits the gotcha in the string. Perfect!
Next steps
Now the code to do this is ~21 lines long plus the CLI adapter. This is not as simple as a 50 byte regex but it is certainly easier to understand than the only-slightly-more-effective 1k regex we saw in the followup.
(?(DEFINE)(?’value'(?P>any)?))(?(DEFINE)(?’any'(?P>unbalanced_outer)*(?:(?P>paran)|(?P>curly_braces)|(?P>brackets)|(?P>string)|)+(?P>unbalanced_outer)*))(?(DEFINE)(?’any_inner'(?P>unbalanced_inner)*(?:(?P>paran)|(?P>curly_braces)|(?P>brackets)|(?P>string)|)+(?P>unbalanced_inner)*))(?(DEFINE)(?’paran'(s*(?P>any_inner)+s*)))(?(DEFINE)(?’curly_braces'{s*(?P>any_inner)+s*}))(?(DEFINE)(?’brackets'[s*(?P>any_inner)+s*]))(?(DEFINE)(?’string'((?P>string_double_quote)|(?P>string_single_quote)|(?P>string_tick))))(?(DEFINE)(?’string_double_quote'”(?P>string_context)?”))(?(DEFINE)(?’string_single_quote”(?P>string_context)?’))(?(DEFINE)(?’string_tick’`(?P>string_context)?`))(?(DEFINE)(?’string_context'(?>\[sS]|[^\])*))(?(DEFINE)(?’unbalanced_outer'[^(){}[]”‘`,;]))(?(DEFINE)(?’unbalanced_inner'(?:(?P>unbalanced_outer)|[,;])))(var|let|const|G,)s+(?:(?<variable_name>w+)(?:s*=s*(?P>value))?s*);?
Using a parser and traversal tools to analyze JavaScript may seem like a scary jump when you?re used to working with regular expressions but regexes have a limit in both effectiveness and practicality. Often times that limit is well before what we push a regex solution to. Getting familiar with parsers and ASTs sooner rather than later will give you serious power in both simple analysis and complex transformations.
This was a small example that just outputs strings line by line on the command line. You can get a lot more powerful if you consider JSON as a common transport format for AST manipulation and analysis tools. I?ve put out an example using CLI versions ofshift-query and shift-codegen that allow you to query and extract arbitrary code from a JavaScript source file. Add a few more tools in between and you have a powerful reverse engineering and hacking pipeline all on the command line.
If you like topics like this, make sure to follow me here on Medium, on Twitter, and/or YouTube. This is what I do ?


{kind=link}
{kind=link}