An English pangram is a sentence that contains all 26 letters of the English alphabet. The most well known English pangram is probably ?The quick brown fox jumps over the lazy dog?. My favorite pangram is ?Amazingly few discotheques provide jukeboxes.?
A perfect pangram is a pangram where each of the letters appears only once. I have found some sources online that list the known perfect pangrams. Nobody seems to have endeavored successfully to produce all of them exhaustively, so I took it on as a fun challenge. This is how I found all* of the perfect pangrams of English. I will explain the asterisk later.
Here are some of my favorite perfect pangrams I discovered
 A crwth. Source.
A crwth. Source.
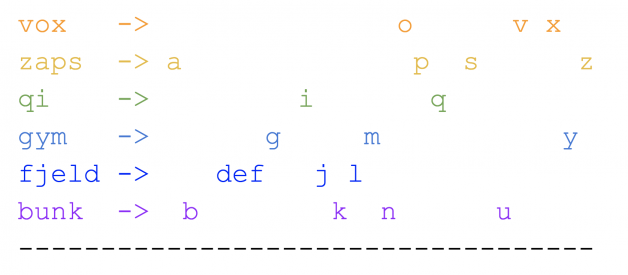
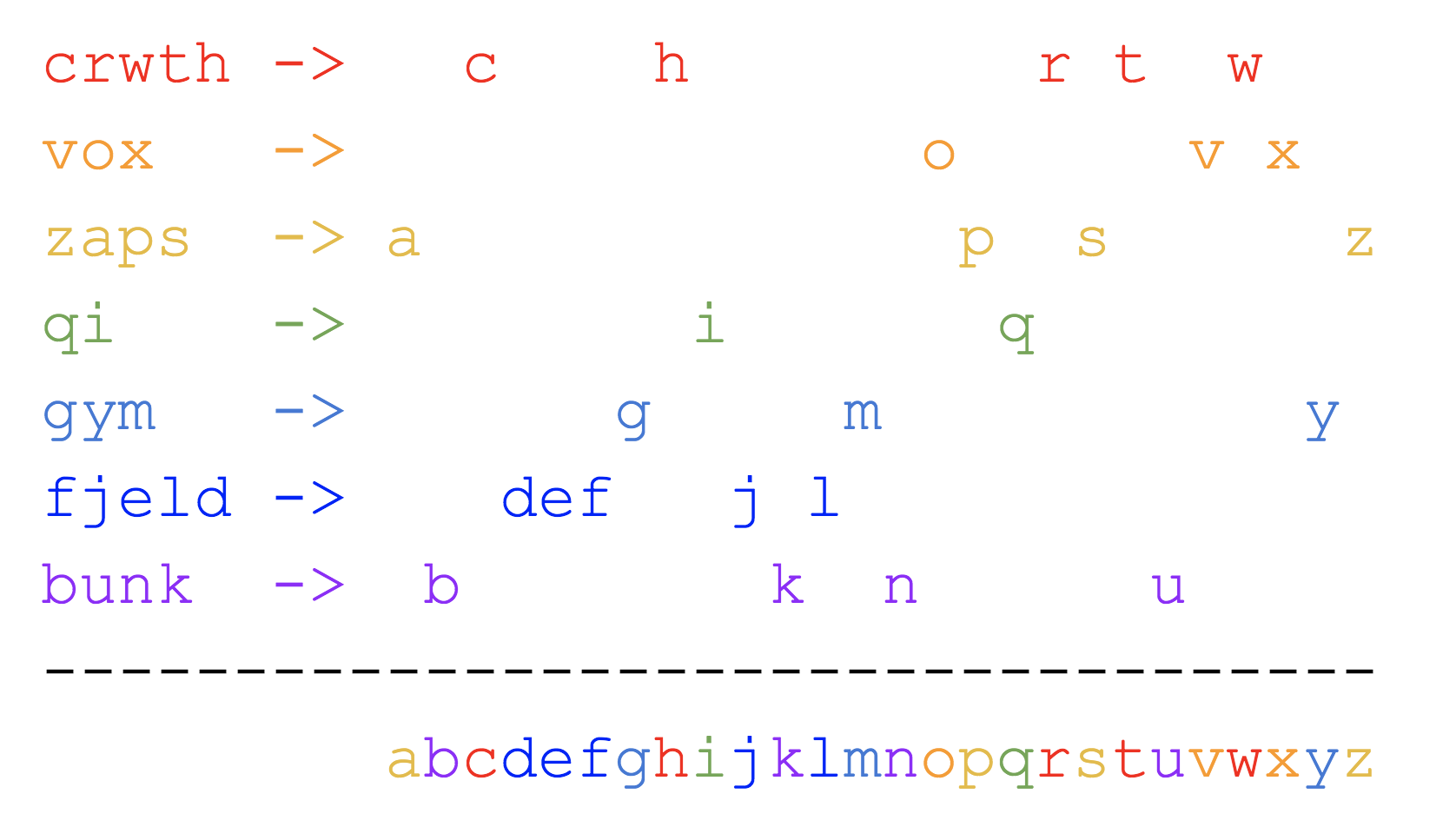
- Crwth vox zaps qi gym fjeld bunk. (The sound of a Celtic violin strikes an eastern spiritual forces-focused fitness center situated in a barren plateau of Scandinavia.) This one is all Scrabble legal words!
- Squdgy kilp job zarf nth cwm vex. (The ill-formed kelp buys an ornamental cup warmer that one of many half-open steep-sided hollows at the head of a valley or mountainside has irritated.)
- Jock nymphs waqf drug vex blitz. (The charitable endowment intoxicated the forest spirits, who frustrated the athlete, who engages in an attack.)
- Hm, fjord waltz, cinq busk, pyx veg. (Let?s see, a long narrow deep inlet dances, the five on the dice makes music on the street, and the small round container for the sick and unable rests.) Also Scrabble legal, but has an interjection (Hm).
Unfortunately, these are some of the most legible sentences I could find*. All perfect pangrams generated from the Official Tournament and Club Word List 3 (OWL3) for Scrabble without interjections include either the word cwm or crwth. Waqf is Scrabble tournament legal outside of North America.
How to find all of the perfect pangrams
The method for finding perfect pangrams comes in two steps. The first is to find all sets of words that contain each letter of the English alphabet once. The second step is to see which of those sets can be rearranged into valid English sentences.
Step 1: Finding sets of words for the perfect pangram
To start finding sets of words that span the English alphabet requires a list of English words. Finding and maintaining a high quality list of words was much harder than I had anticipated. Originally, I thought this project would take two days, but it ended up taking two weeks as a result of this data quality problem.
I started with the Unix dictionary, which is a freely available list of English words that comes with almost all Unix-based operating systems. I noticed immediately that the list had quality issues. First, each letter of the alphabet was considered a word in the Unix dictionary, and it included a lot of non-words, like ?vejoz?. This demonstrated the need of a blacklist to manage the lists of words found online. Second, the Unix dictionary lacked plurals for words, so the dictionary would include the word ?orange? but not ?oranges?. The word list is so restrictive, in fact, that no previously known perfect pangrams include only words from the Unix dictionary. I still found some, such as ?squdgy kilp job zarf nth cwm vex?.
I then turned to the internet to find larger sets of words. I found very large word sets that were huge, but when I started digging for perfect pangrams from those lists, I found that they were way too polluted with low quality words that aren?t valid English words. Even after many rounds of iteration, I still failed to pare down the list to find any reasonable or manageable pangrams. I tried to clean it up by creating a whitelist of words of certain lengths, but the list was still extremely low quality.
Finally, after many iterations, I paid $15 to buy a trial membership of the North American Scrabble Players Association, which gave me access to the proprietary and copyrighted OWL3, which is the source of some controversy. Even then, I had to add in some known words in English, such as the single-letter words ?a? and ?I?.
Armed with a proper list of words, I implemented an algorithm to produce all sets of words from that list that each contains one of each letter of the English alphabet. I will describe the algorithm at depth in ?The Algorithm? section below.
Step 2: Forming English sentences from a bag of words
Given a set of words, figuring out whether a valid English sentence is possible with all the provided words is a non-trivial problem, but it is easier than most other natural language processing (NLP) problems.
There are useful heuristics for weeding out ineligible sentences; I was able to form valid English sentences from the remaining words after following those heuristics. The sentences were often nonsensical, but still valid. Here are the heuristics I used:
- There needs to be at least one verb.
- There can only be one more noun than there are verbs unless there is a conjunction or a preposition, both of which are very rare.
- If there are adjectives, there must also be nouns.
The heuristic works in part because of the possibility of implied subjects (neither perfect nor a pangram, but ?move quietly and speak softly? is a sentence with two verbs and no nouns, with the implied subject of ?you?).
Since the space of words that can possibly participate in perfect pangrams is small, it?s easy enough to manually tag each individual word with its eligible parts of speech and see if the set of words obeys those three simple heuristics. Whether or not you like the quality of the sentences produced is a matter of taste.
The Algorithm
This section is a bit technical, but hopefully still easy to follow. Feel free to skip to the ?Results & Learnings? section.
High Level Strategy
The goal is to produce all possible sets of words from the given list of words that spans the English alphabet ?perfectly?.
- Clean the list of words to drastically reduce search space, e.g. remove words that have repeated letters, like ?letters?.
- Use bit masks to represent words efficiently and map them back to the original sets of words.
- Search through all possible states, each representing a possible letter combination, by repeatedly iterating through the list of bit masks. Performance is dramatically improved with dynamic programming.
- Draw arrows (directed edges) from the perfect pangram state, the final state that has all the English letters, to the intermediary states that composed it. Do that again with the intermediary states to create a data structure that can reconstruct the sets of words that are possible perfect pangrams. This is called backtracking.
- Output the discovered sets of words that are possibly perfect pangrams as trees.
1. Cleaning the list, aka Canonicalization

First step is to clean the original list of words to reduce search space and increase output quality.
- Strip all whitespace around the word and convert it to lower case only
- Make sure the words only contain letters of the English alphabet; I used a simple regular expression filter: /^[a-z]+$/
- Filter against any other lists, e.g. blacklists; if a word is in the blacklist, skip that word
- Remove all words with repeated letters
This shortened the search space significantly, from lists of 200,000~370,000 words to a much smaller 35,000~65,000 words.
2. Using bit masks

Bit masks are integer representations of states. There are several advantages of bit masks:
- Bit masks represent this problem well. Letter ordering does not matter, so all combinations of words can be represented as a 26 digit long series of 0?s and 1?s, with each digit representing whether or not a letter exists in the combination. For example. if the set of words contains the letter ?e?, the 5th digit will be a 1, otherwise a 0.
- Bit masks are efficient: Since the search space is constant, bit masks offer an efficient storage and representation of all the possible combinations of letters. Furthermore, bitwise-operations are fast; to test if two bit masks can be combined to produce a larger bit mask, check if the bitwise AND of the two masks equals 0, both of which are extremely fast operations.
So, turn each word into a bit mask, which can be represented as an integer. For example, the word ?cab? gets mapped to the bit mask of 111, which is the decimal number 7. The word ?be? gets mapped to 10010, which is the decimal number 18, and so on. The largest possible bit mask is one with all the letters of the alphabet, the possible perfect pangram state, 11111111111111111111111111, which is the decimal number 67,108,863, or 2? -1. This fits well within a standard signed 32-bit integer, which can represent up to 2-1.
Using bit masks further compresses space, as single word anagrams map to the same bit mask. Both ?kiln? and ?link? map to the mask 10110100000000, which is the decimal number 11520. This further reduces the search space of 35,000~65,000 words to 25,000~45,000 bit masks.
Retain a mapping of the bit mask back to the set of words they are derived from. This will be useful when outputting the sets of words.
3. Searching for the perfect pangram with dynamic programming
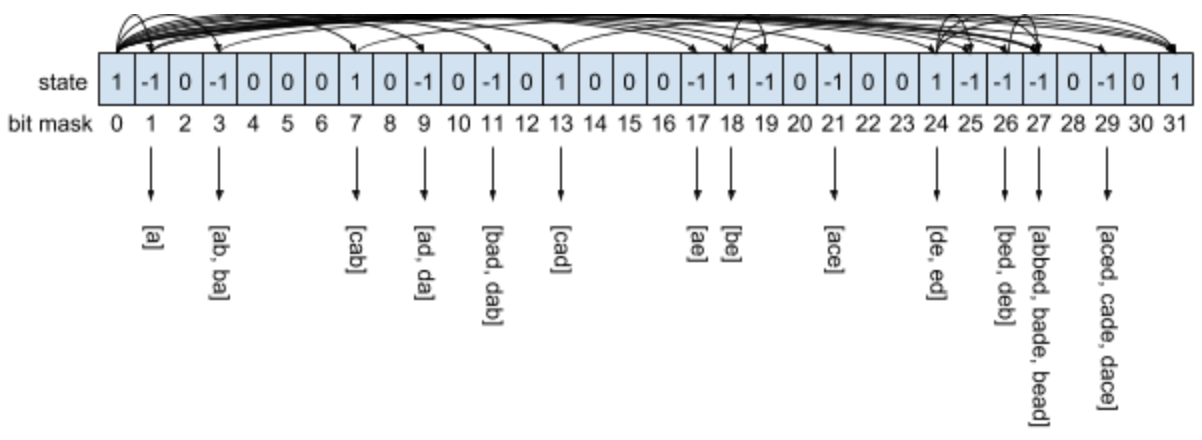 Drawn out toy example for only the first 5 letters of the English alphabet, a-e
Drawn out toy example for only the first 5 letters of the English alphabet, a-e
The core of the algorithm is fairly simple:
Given a possible state (that is composed of valid combinations of existing words), try all of the masks from the initial word list to see if it?s possible to create a new valid state (by checking if the bitwise AND of the state and mask equals 0, which would mean that there are no overlapping letters). Create the new state by using the bitwise OR operation which merges all the 1s together. For each new state discovered, keep repeating until there are no more unexplored states. If this reaches the end, that means that the algorithm has found at least one possible perfect pangram word set. The first possible state that can enumerate all possible states is the empty state or 0, where no letters of the alphabet are included. So start there and then recursively discover which states are possible.
One huge efficiency gain is to notice that there are many ways to reach an intermittent state and that the work on the state does not change based on how it was reached. So instead of repeating the work when a state is revisited, store the result of each state. This technique is called dynamic programming and turns a complex combinatorial problem into a linear program. The process of storing the intermittent state is called memoization.
So create an array of size 2?, between 0 and 67,108,863, inclusive. Each index represents a bit mask state as explained before. The value at each index of the array represents what is known about the state. 0 means either that the state is untouched or unreachable. 1 means that the state has found a way to reach the possible perfect pangram state. -1 means that the state has failed to find a way to reach the end.
Pseudocode below:
int PANGRAM_STATE; // 2^26 – 1 == 67108863// dp[state] == 0 means the state is untouched or unreachable// dp[state] == 1 means the target is reachable from state// dp[state] == -1 means the target is unreachable from stateint solve(int state, int target, int dp, List<Integer> masks) { if (state == target) { // Base Case: Does it reach the target? return 1; } if (dp[state] != 0) { // DP: don’t repeat work for a state return dp[state]; } boolean reachesTarget = false; for (int mask : masks) { // try all masks if ((state & mask) != 0) { // check for overlap continue; } int newState = state | mask; // combine state and masks dp[newState] = solve(newState, target, dp, masks); if (dp[newState] == 1) { reachesTarget = true; } } return reachesTarget ? 1 : -1;}solve(0, PANGRAM_STATE, dp, masks);
Interlude: Complexity and Practical Runtime Analysis
There are 2? possible bit masks for a series of 26 bits. Since each state is processed only once because of memoization, the runtime of this algorithm is O(n 2^d), where d is the size of the alphabet, 26. The variable n does not stand for the number of words, but the number of bit masks. With 67,108,863 and roughly 45,000 bit masks, this comes out to on the order of 3 trillion, which my MacBook Pro could handle in roughly 45 minutes; tractable for any modern computer. It?s also worth noting that the recursive call stack will never get deeper than 26 (likely never gets deeper than 15), so it?s also very manageable from that dimension as well.
One advantage of the bit mask approach with only 2? states is that all the states can be stored in memory. Since there are only 3 values per state (-1, 0, 1), this can be stored in a single byte. At a single bytes per state, 2? states comes out to around 67 megabytes, which is again very manageable.
As the alphabet increases, though, the search space increases exponentially and so does the run time, causing the problem to become intractable very quickly. A brief discussion on approaching the perfect pangram for larger alphabets are in the ?Language w/ Larger Alphabets? section below.
4. Dynamically building a Directed Acyclical Graph (DAG)
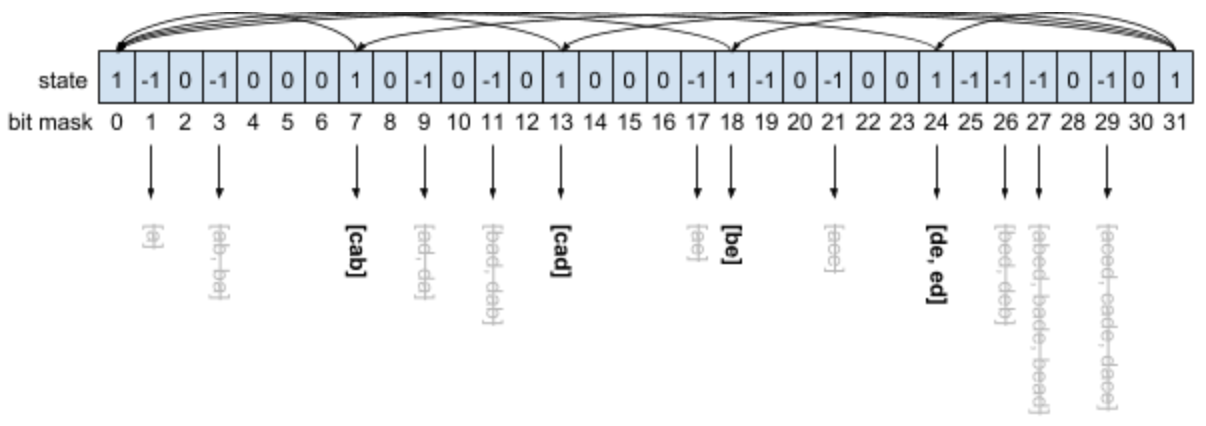 Drawing the DAG only for bit masks with state 1
Drawing the DAG only for bit masks with state 1
Now that we have filled out the bit mask states, time to retrieve the solution!
To find the sets of words that created the set of possible perfect pangrams, we need to derive which intermediary states were integral to composing the final states. Then, the follow-up question is which other intermediary states composed those intermediary states, and so on until the only thing remaining are the states that map directly to words. This process is called backtracking.
To keep track of the relationships between states, the goal is to created a Directed Acyclical Graph (DAG), which maintains which intermediary states composes any given state. DAGs are easy to traverse to retrieve outputs, especially due to their non-cyclical nature. To construct, start from the possible perfect pangram state, and create a directed edge (arrow) that points to the intermediary states that compose it. Repeat the process with the intermediary states, and it will produce a DAG. There will never be any cycles because the arrows always point to a state with a smaller value.
Instead of rebuilding the relationships that were discovered in the search step, which involves traversing again through trillions of possible states combinations, it?s more efficient to build the DAG during the dynamic programming phase. Inside the solve method, if a newly constructed state can reach the possible perfect pangram state, store a directed edge from the newly constructed state to the original state only if the original state is smaller than its complement (to reduce edge duplication).
5. Print out the fruits of your labor in tree form!
 Output of the toy example
Output of the toy example
Likely the easiest format for viewing the resulting sets of words is by listing them as trees with the root node as the perfect pangram state. Given the DAG constructed from above, the best way to unpack it is to do so recursively, writing each state to disk on each step instead of in-memory since the tree is an order of magnitude larger than the DAG.
int PANGRAM_STATE; // 2^26 – 1 == 67108863Map<Integer, List<Integer>> edges; // DAG edgesMap<Integer, List<String>> maskMap; // Mask back to word listvoid outputTree(int level, int state, Map edges, Map maskMap) { output.indent(level); // uniformly indent based on level output.print(state); if (maskMap.containsKey(state)) { output.print(“====>”); output.print(maskMap.get(state)); } for (int substate : edges.get(state)) { int composite = state ^ substate; outputTree(level + 1, substate, edges, maskMap); outputTree(level + 1, composite, edges, maskMap); }}outputTree(0, PANGRAM_STATE, edges, maskMap);
An improvement to this form of expansion is to summarize states that have only a single possible combination of words. A state that is a mask to words and no substates that compose it can be trivially summarized. A state can be summarized if its substates and its composites can be summarized, and all masks derived from itself and its children do not have overlapping bits/characters. Printing the summarized DAG improves the readability of the resulting output tree by shortening and simplifying it.
Since the summarization depends only on the smaller of the two states, iterating through the array from the initial state of 0 upwards and using the rules above to manage the summarization rule allows for this to be completed in linear time.
Results & Learnings
Produced Pangram Trees!
Feel free to traverse through the perfect pangram trees to see if you can find interesting sentences!
https://github.com/temporalparts/PerfectPangrams
There are a lot of possible perfect pangrams
I was surprised by the number of perfect possible pangrams. There are a lot! The best strategy for piecing them together does not require a complex natural language processor. Once the candidate words have been labeled as noun or verb eligible, the bag of words must contain at least one noun, one verb, and the right ratio of nouns and verbs.
Data Quality is a hard problem
The algorithm section took two days, but the data quality problem took two weeks. When I mentioned this finding to my friend who is a senior staff engineer Google, he was not surprised, commenting that data quality issues are some of the hardest problems in engineering. Lesson learned.
The Rules of Perfect Pangrams
There are a lot of nuances as to what qualifies as a perfect pangram! I wanted to search through pangrams without any interjections (e.g. hm, pht), but there are also other popular restrictions such as abbreviations, acronyms, contractions, initialisms, isolated letters, proper nouns, and Roman numerals. There are also words which are names of letters, like Qoph, which I felt is cheating.
With some of those constraints relaxed, there are a lot of ?perfect? pangrams. In the order of trillions, probably. There are a lot of acronyms and initialisms.
The Asterisk
The asterisk is in place because the definition of all of the perfect pangrams of English is not well defined. There are nuances related to what should be allowed in perfect pangrams of English. There are also a lot of contentions regarding whether or not some words are even English words. Given these nuances, it is really difficult to say that I have found all of the perfect pangrams. I can make two claims fairly confidently:
- I have found a methodology for producing all of the perfect pangrams of English and other languages with similar or smaller character sets.
- I have enumerated all sets of words that can possibly form perfect pangrams using the official Scrabble tournament dictionary, OWL3.
Please feel free to produce your own perfect pangrams with the techniques described in this post!
Perfect Pangrams? dependence on words of Welsh and Arabic roots
Welsh- and Arabic-derived words were really important for the existence of perfect English pangrams (unless the constraints of the perfect pangram are relaxed). Using the OWL3 word list with strict rules regarding perfect pangrams, there are no perfect pangrams that do not include the words ?cwm(s)? or ?crwth(s)?, both Welsh words. In international Scrabble, the Arabic derived word ?waqf(s)? is a valid word which can produce perfect pangrams without resorting to ?cwm(s)? or ?crwth(s)?.
Work Stream Efficiencies
It was important to become more efficient at parallelizing tasks during this project. A full run takes 25 minutes for the Unix dictionary and close to an hour for the really large dictionaries. I had some initial trouble context switching for a 30 minute window, but got better at it as I went along to improve my productivity.
Extension/Generalization ? Anagram Finder
The perfect pangram search is also equivalent to an anagram finder for the string ?abcdefghijklmnopqrstuvwxyz?. What if you wanted to build a generic anagram finder?
The same technique can be used as long as the state representation and management rules for checking word combination validity are updated. Instead of having states be managed as an integer, it would be easier to track the state as a map of the relevant characters. Seeing if combinations are valid is to say that the combination of two maps do not exceed the anagram?s desired character count for each letter. Just make sure that the state space is tractable; with too many letters, the search space can get really big in a jiffy. Also, are you allowed to repeat words? Make sure you define those rules inside your dynamic programming solution.
Languages w/ Larger Alphabets
 Iroha is a famous Japanese perfect pangram poem written in the Heian Period
Iroha is a famous Japanese perfect pangram poem written in the Heian Period
This approach and solution are linear in the word-set size, but exponential in alphabet size. This approach may not work with a larger character set, say modern Japanese which has 46 syllabaries. 2?? is 70,368,744,177,664; over a million times larger than the English search space of 2? = 67,108,864.
It?s not entirely clear whether or not this approach would work for Japanese. If Japanese language has sufficiently low entropy, which is possible, this approach would be viable. Instead of initializing an array of size 2??, the states will be kept tracked in a map. Furthermore, the structure of Japanese can be exploited; for example the kana ? (wo) is almost exclusively used as a post positional participle, and can be excluded from the search, reducing the search space.
The Cambodian language of Khmer has the largest alphabet with 74. Another possible next step is to explore solutions that are sub-exponential in alphabet size.
Inspiration
I was inspired by Aubrey De Grey?s advancement in finding the chromatic number of the plane to be at least 5. This is a significant advancement which was achieved through basic computational methods.
Needless to say, finding perfect pangrams does not hold a candle to improving the lower bound of the chromatic number of a plane.
This makes me believe that there are a lot of low hanging fruit problems that have simple computational methods towards solving a problem that is manually intractable. I challenge you to find and solve some of these problems. Please let me know if you find something!
Thanks
I?m quite thankful for my very excellent friends who helped by proofreading and jamming on this with me, especially Anna Zeng, Catherine Gao, Danny Wasserman, George Washington, and Nick Wu!

{kind=link}
{kind=link}