Convex hulls tend to be useful in many different fields, sometimes quite unexpectedly. In this article, I?ll explain the basic Idea of 2d convex hulls and how to use the graham scan to find them. So if you already know about the graham scan, then this article is not for you, but if not, this should familiarise you with some of the relevant concepts.
What is the convex hull?
The convex hull of a set of points is defined as the smallest convex polygon, that encloses all of the points in the set. Convex means that the polygon has no corner that is bent inwards.
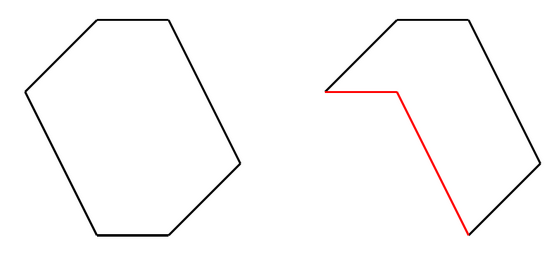 A convex polygon on the left side, non-convex on the right side.
A convex polygon on the left side, non-convex on the right side.
The red edges on the right polygon enclose the corner where the shape is concave, the opposite of convex.
A useful way to think about the convex hull is the rubber band analogy. Suppose the points in the set were nails, sticking out of a flat surface. Imagine now, what would happen if you took a rubber band and stretched it around the nails. Trying to contract back to its original length, the rubber band would enclose the nails, touching the ones that stick out the furthest from the centre.
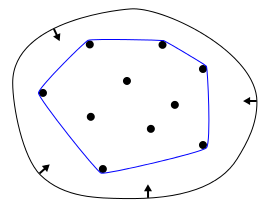 The rubber band analogy, image from Wikipedia.
The rubber band analogy, image from Wikipedia.
To represent the resulting convex hull in code, we usually store the list of points that hold up this rubber band, i.e. the list of points on the convex hull.
Note that we still need to define what should happen if three points lie on the same line. If you imagine the rubber band to have a point where it touches one of the nails but it doesn?t bend there at all, that means that the nail there lies on a straight line between two other nails. Depending on the problem, we might consider this nail along the straight line to be part of the output, since it touches the rubber band. On the other hand, we might also say this nail shouldn?t be part of the output, because the shape of the rubber band doesn?t change when we remove it. This decision depends on the problem you are currently working on, and best of all if you have an input where no three points are collinear (this is often the case in easy tasks for programming competitions) then you can even completely ignore this problem.
Finding the convex hull
Looking at a set of points, human intuition lets us quickly figure out which points are likely to touch the convex hull, and which ones will be closer to the centre and thus away from the convex hull. But translating this intuition in to code takes a bit of work.
To find the convex hull of a set of points, we can use an algorithm called the Graham Scan, which is considered to be one of the first algorithms of computational geometry. Using this algorithm, we can find the subset of points that lie on the convex hull, along with the order in which these points are encountered when going around the convex hull.
The algorithm starts with finding a point, that we know to lie on the convex hull for sure. The point with the lowest y coordinate for example can be considered a safe choice. If multiple points exist at the same y coordinate, we take the one that has the biggest x coordinate (this also works with other corner points, e.g. first lowest x then lowest y).
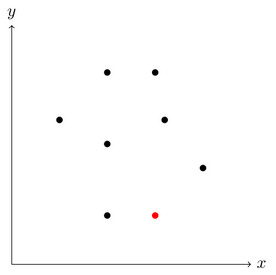 The chosen starting point is marked in red.
The chosen starting point is marked in red.
Next, we sort the other points by the angle at which they lie as seen from the starting point. If two points happen to be at the same angle, the point that is closer to the starting point should occur earlier in the sorting.
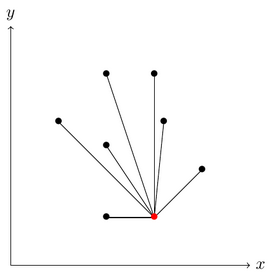 Sorting the points by angle.
Sorting the points by angle.
Now, the idea of the algorithm is to walk around this sorted array, determining for every point, whether or not it lies on the convex hull. This means, that for every triple of points we encounter, we decide if they form a convex or a concave corner. If the corner is concave, then we know, that the middle point out of this triplet can?t lie on the convex hull.
(Note that the terms concave and convex corner have to be used in relation to the entire polygon, just a corner on its own can?t be convex or concave, since there would be no reference direction.)
We store the points that lie on the convex hull on a stack, that way we can add points if we reach them on our way around the sorted points, and remove them if we find out that they form a concave corner.
(Strictly speaking, we have to access the top two points of the stack, therefore we use a std::vector instead, but we think of it as a kind of stack, because we?re always only concerned about the top couple of elements.)
Going around the sorted array of points, we add the point to the stack, and if we later on find that the point doesn?t belong to the convex hull, we remove it.
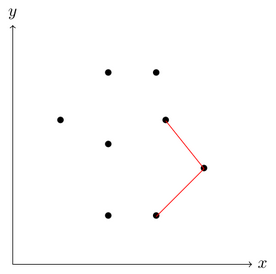 Encountering a convex corner.
Encountering a convex corner.
We can measure whether the current corner bends inwards or outwards by calculating the cross product and checking if that is positive or negative. The figure above shows a triplet of points where the corner they form is convex, therefore the middle one out of these three points remains on the stack for now.
Going on to the next point, we keep doing the same thing: check whether the corner is convex and if not, remove the point. Then go on adding the next point and repeat.
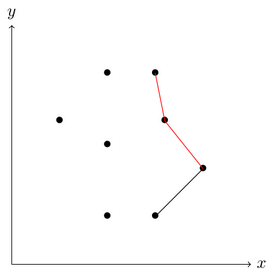 Encountering a concave corner.
Encountering a concave corner.
This corner marked in red is concave, therefore we remove the middle point from the stack as it can?t be part of the convex hull.
How do we know that this will give us the correct answer?
Writing a rigorous proof is out of the scope of this article, but I can write down the basic ideas. I encourage you, however, to go on and try to fill in the gaps!
Since we calculated the cross product at every corner, we know for sure that we?re getting a convex polygon. Now we only have to prove, that this convex polygon really does enclose all the points.
(Actually, you?d also need to show that this is the smallest possible convex polygon satisfying these conditions, but that follows quite easily from the corner points of our convex polygon being a subset of the original set of points.)
Suppose, there exists a point P outside the polygon we just found.
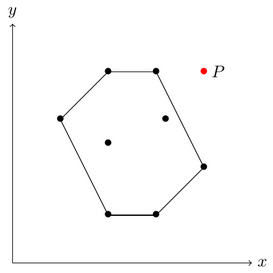 The red point P lies outside the convex polygon.
The red point P lies outside the convex polygon.
Since every point has been added to the stack once, we know that P was removed from the stack at some point. This means, that P, together with its neighbouring points, let?s call them O and Q, formed a concave corner.
Since O and Q lie inside the polygon (or on its border), P would have to lie inside the border as well, because the polygon is convex and the corner that O and Q form with P is concave with relation to the polygon.
Thus we have found a contradiction, which means that such a point P can?t exist.
Implementation
The here provided implementation has a function convex_hull, which takes a std::vector that contains the points as std::pairs of ints and returns another std::vector that contains the points that lie on the convex hull.
Runtime and memory analysis
It?s always useful to think about the complexity algorithms in terms of the Big-O notation, which I won?t explain here, because Michael Olorunnisola here has already done a much better job explaining it than I probably would:
Algorithms in plain English: time complexity and Big-O notation
by Michael Olorunnisola Algorithms in plain English: time complexity and Big-O notation Every good developer has time?
www.freecodecamp.org
Sorting the points initially takes O(n log n) time, but after that, every step can be calculated in constant time. Every point gets added to and removed from the stack at most once, this means that the worst-case runtime lies in O(n log n).
The memory usage, which lies in O(n) at the moment, could be optimized by removing the need for the stack and performing the operations directly on the input array. We could move the points that lie on the convex hull to the beginning of the input array and arrange them in the right order, and the other points would be moved to the rest of the array. The function could then return just a single integer variable that denotes the amount of points in the array that lie on the convex hull. This, of course, has the downside, that the function gets a lot more complicated, I would therefore advise against it, unless you?re coding for embedded systems or have similarly restrictive memory concerns. For most situations, the bug probability/memory saving trade-off is just not worth it.
Other Algorithms
An alternative to the Graham Scan is Chan?s algorithm, which is based on effectively the same idea but is easier to implement. It makes sense to first understand how Graham Scan works though.
If you?re really feeling fancy and want to tackle the problem in three dimensions, take a look at the algorithm by Preparata and Hong introduced in their 1977 paper ?Convex Hulls of Finite Sets of Points in Two and Three Dimensions?.


{kind=link}
{kind=link}