

Recently I installed my gaming notebook with Ubuntu 18.04 and took some time to make Nvidia driver as the default graphics driver ( since the notebook has two graphics cards, one is Intel, and the other is Nvidia). I do not want to talk about the details of installation steps and enabling Nvidia driver to make it as default, instead, I would like to talk about how to make your PyTorch codes to use GPU to make the neural network training much more faster.
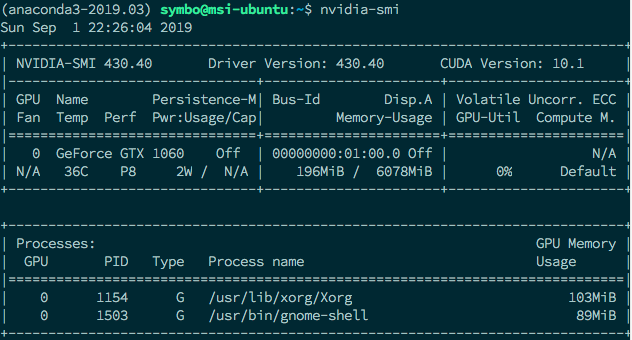
Below is my graphics card device info.
Check if GPU is available on your system
We can check if a GPU is available and the required NVIDIA drivers and CUDA libraries are installed using torch.cuda.is_available.
import torchtorch.cuda.is_available()
If it returns True, it means the system has Nvidia driver correctly installed.
Moving tensors around CPU / GPUs
Every Tensor in PyTorch has a to() member function. It’s job is to put the tensor on which it’s called to a certain device whether it be the CPU or a certain GPU. Input to the to function is a torch.device object which can initialized with either of the following inputs.
- cpu for CPU
- cuda:0 for putting it on GPU number 0. Similarly, if your system has multiple GPUs, the number would be the GPU you want to pu tensors on
Generally, whenever you initialize a Tensor, it?s put on the CPU. You should move it to the GPU to make the related calculation faster.
if torch.cuda.is_available(): dev = “cuda:0” else: dev = “cpu” device = torch.device(dev) a = torch.zeros(4,3) a = a.to(device)
cuda() function
Another way to put tensors on GPUs is to call cuda(n) a function on them where n is the index of the GPU. If you just call cuda, then the tensor is placed on GPU 0.
The torch.nn.Module class also has to add cuda functions which put the entire network on a particular device. Unlike, Tensors calling to on the nn.Module the object is enough, and there’s no need to assign the returned value from the to function.
clf = myNetwork() clf.to(torch.device(“cuda:0”))
Make sure using the same device for tensors
While it?s good to be able to explicitly decide on which GPU does a tensor go, generally, we create a lot of tensors during our operations. We want them to be automatically created on a certain device, so as to reduce cross-device transfers which can slow our code down. In this regard, PyTorch provides us with some functionality to accomplish this.
First, is the torch.get_device function. It’s only supported for GPU tensors. It returns us the index of the GPU on which the tensor resides. We can use this function to determine the device of the tensor so that we can move a created tensor automatically to this device.
#making sure t2 is on the same device as t2 a = t1.get_device() b = torch.tensor(a.shape).to(dev)
We can also call cuda(n) while creating new Tensors. By default, all tensors created by cuda the call are put on GPU 0, but this can be changed by the following statement if you have more than one GPU.
torch.cuda.set_device(0) # or 1,2,3
If a tensor is created as a result of an operation between two operands which are on the same device, so the operation will work out. If operands are on different devices, it will lead to an error.
That?s the main ways to put the data operation on GPU. If you don?t have one, use Google Colab can be an option. Anyway, below codes can be used to see your running environment info regarding Cuda and devices information. Try them on your jupyter notebook
import torchimport sysprint(‘__Python VERSION:’, sys.version)print(‘__pyTorch VERSION:’, torch.__version__)print(‘__CUDA VERSION’, )from subprocess import call# call([“nvcc”, “–version”]) does not work! nvcc –versionprint(‘__CUDNN VERSION:’, torch.backends.cudnn.version())print(‘__Number CUDA Devices:’, torch.cuda.device_count())print(‘__Devices’)# call([“nvidia-smi”, “–format=csv”, “–query-gpu=index,name,driver_version,memory.total,memory.used,memory.free”])print(‘Active CUDA Device: GPU’, torch.cuda.current_device())print (‘Available devices ‘, torch.cuda.device_count())print (‘Current cuda device ‘, torch.cuda.current_device())
And this one is for finding out the exact device information of your graphics driver
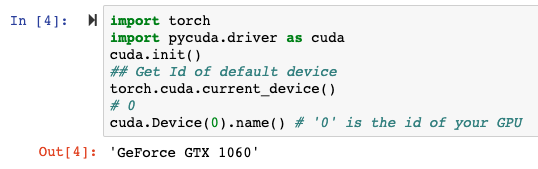
!pip install pycudaimport torchimport pycuda.driver as cudacuda.init()## Get Id of default devicetorch.cuda.current_device()# 0cuda.Device(0).name() # ‘0’ is the id of your GPU
And here is the output from my desktop and my Colab environment



{kind=link}
{kind=link}