Aim: To develop an AI to predict the stock prices and accordingly decide on buying, selling or holding stock. The AI algorithm should be flexible to consider various trading environmental factors like stock price changes, latency, gaining protection from future price movements.
Introduction: To develop a TradeBot, you have to model stock prices correctly, so as a stock buyer you can reasonably decide when to buy stocks and when to sell them to make a profit, which involves developing a Time-Series model. Thus, the problem statement can also be loosely handled in a ?Supervised learning approach using LSTM?.
What?s LSTM?
Humans don?t start their thinking from scratch every second. As you read this essay, you understand each word based on your understanding of previous words. We don?t throw everything away and start thinking from scratch again. The LSTM or Long Short-Term Memory neural networks allow us to learn the context required to make predictions in time series forecasting problems, rather than having this context pre-specified and fixed. LSTM thus can look at the history of a sequence of Trading data and predict what the future elements of the sequence are going to be.
Why Reinforcement Learning over Supervised approaches (LSTM)?
As described in my other post, Reinforcement learning is a branch of ML which involves taking suitable action to maximize reward in a particular situation. RL differs from the supervised learning in a way that in supervised learning the training data has the answer key with it so the model is trained with the correct answer itself whereas in reinforcement learning, there is no answer but the reinforcement agent decides what to do to perform the given task.
While the problem statement can also be loosely handled in a supervised learning approach using LSTM, RL is more robust as it allows flexibility to take into account various other environmental factors which affect the stock prices, like latency etc.
A forecast predicts future events whereas an RL agent optimizes future outcomes.
Approach:
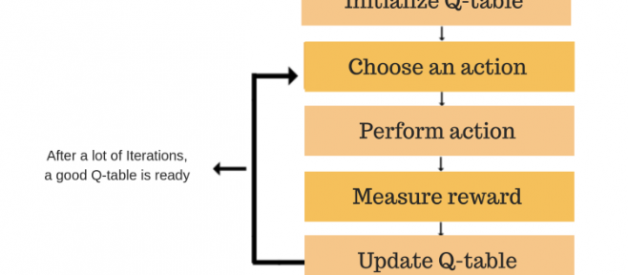
I have used Deep Q learning RL algorithm to train the TradeBot. The goal of Q-learning is to learn a policy, which tells an agent what action to take under what circumstances. In general, Q learning involves the following flow:
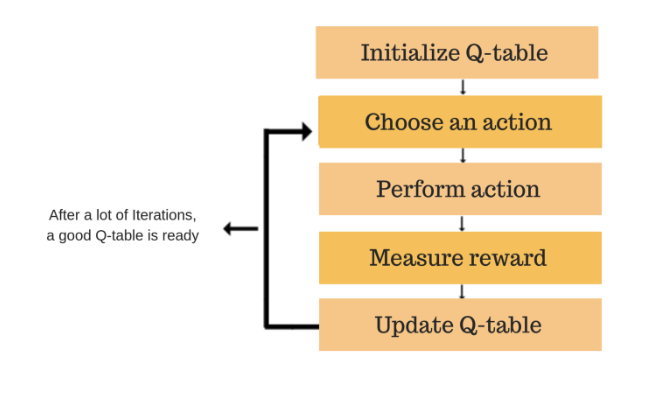 Q-Learning General Flow
Q-Learning General Flow
FlowChart :
![]() Bellman Approximation
Bellman Approximation
- Start with an empty table, mapping states to values of actions.
- By interacting with the environment, obtain the tuple s, a, r, s? (state, action, reward, new state). In this step, we need to decide which action to take, and there is no single proper way to make this decision. I have taken one of the approaches. There has to be a balance between exploration vs exploitation for any RL Bot.
- Update the Q(s, a) value using the Bellman approximation described above.
- Repeat from step 2
Implementation:
The implementation is done using Pytorch and the code can be found here.
To formulate RL problem, we need to define three things: observation of the environment, possible actions and a reward system. In this implementation, I took a basic trading agent in its simplest form. This is to establish the Q-Learning algorithm on the trading environment.
The observation will include the following information: a) N past bars, where each has open, high, low and close prices. b) An indication of the current position value of the trading agent. c) Profit or loss we currently have from our current position. Note: to develop an advanced Trading Bot, one can extend the observations and change the hyperparameters of the Q-Learning network accordingly.
At every step, the agent can take one of the following actions: a) Do Nothing (Hold): Skip the bar without taking actions. b) Buy a share: Appended in the agent?s position. c) Close the position(Sell)
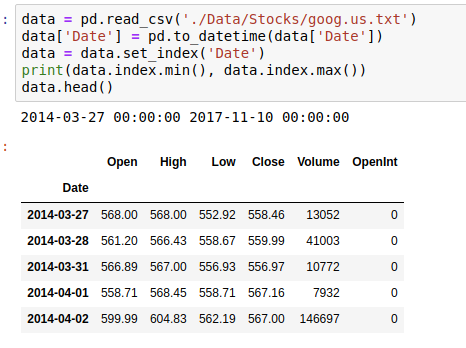 Data preview
Data preview
The dataset used in the implementation is an opensource dataset. The code above reads the stock data and arranges it based on the ?Date? column. We then split this data into ?Train? and ?Test? set.
 Establishing the Trading Environment
Establishing the Trading Environment
The Environment class establishes the trading environment. The position list includes the list of current stocks with the trading bot. The position value of the trade bot and the delta of the stock prices changes contribute to the observation set for the Tradebot.
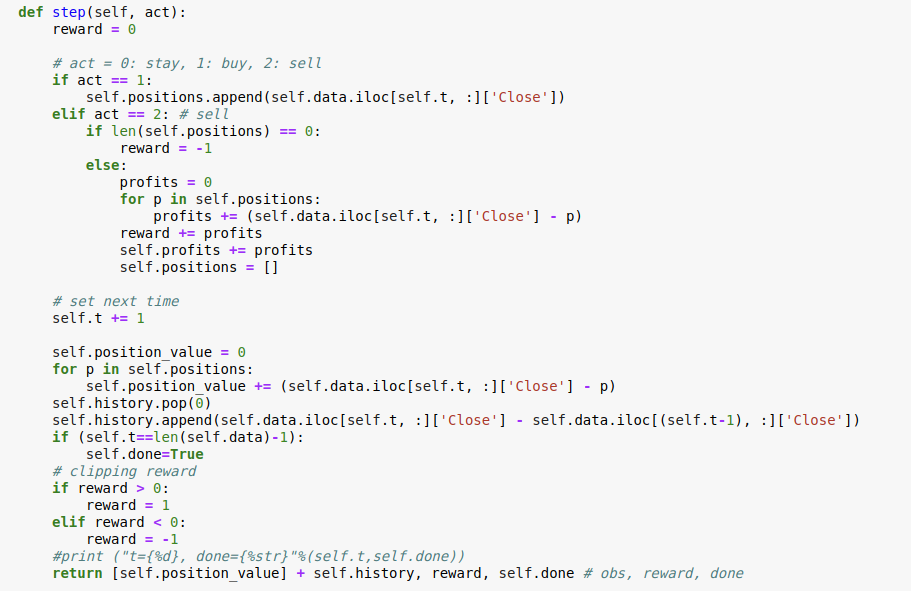 Setting the actions
Setting the actions
As described before, the agent has 3 options for taking action. If the agent decides to buy the stock, its position increases. If the agent decides to sell, its profit is calculated as a difference between the price it decided to sell and the buying price. To ensure that the tradebot doesn?t learn to sell the bot while having no positions, it is penalised with a reward of -1.
In the next step, the tradebot updates its history with the delta of stock prices. Also, a track of the bot?s position is maintained at each step. If the current step leads to a profit, the agent is rewarded with a +1 and if the current action leads to a loss, then the agent is penalized with a -1.
 model network
model network
The model involves a 3 layer neural network. The hidde_size is a hyperparameter and was set 100 for my experiment. The network projects the observation vector to 3 classes (number of actions).
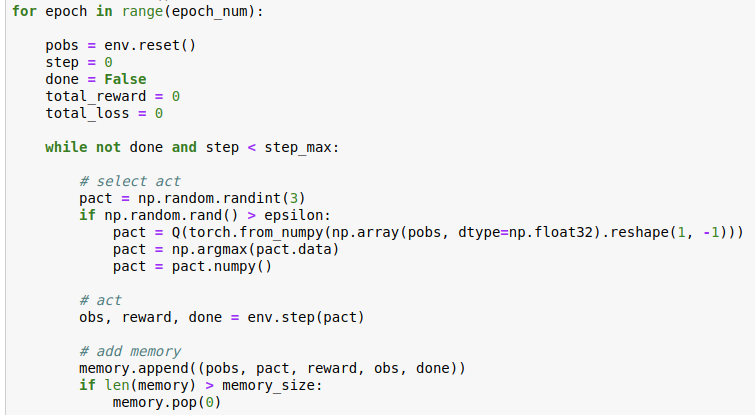 Training Pipeline
Training Pipeline
The first step is to initialize the environment, including its observation and rewards. The model (Q function) predicts the highest probable action for the initial set of observations using argmax. The predicted action is passed through the environment and generates the new set of observations(s?), the reward for carrying the step and the done flag which indicates whether the episode is over (which involves reading through the entire training set). The memory is buffer which keeps a record of the last 200 actions and its corresponding observations, rewards and the new set of observations obtained upon doing the action.
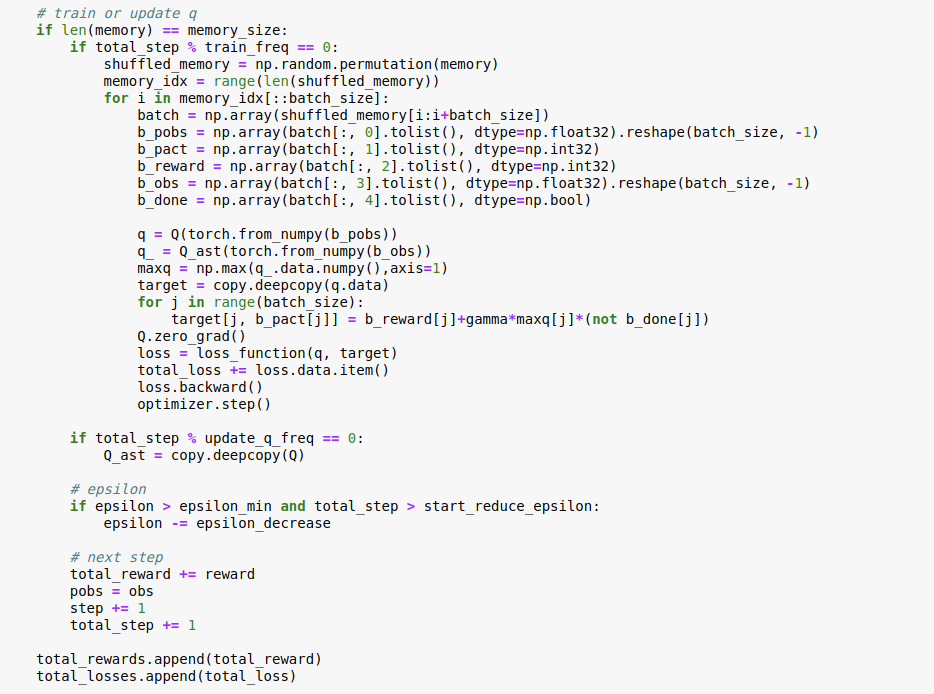 Update q value
Update q value
The above code involves creating batches of the ?b_pobs? (s), b_pact (a?), b_reward(r), b_obs(s?) and the done flag.
The target is the Q table where we update the Q values for each set of action and its corresponding state according to the Belmann equation described in the flowchart above. The loss function is a Mean squared error function. The optimizer aims to update the Q values for minimizing the loss.
In the next post, I will try to implement advanced extensions of Q-Learning as well as Actor-Critic approach. Stay Tuned.


{kind=link}
{kind=link}