Coauthors: Jeremy Lewi (Google), Josh Bottum (Arrikto), Elvira Dzhuraeva (Cisco), David Aronchick (Microsoft), Amy Unruh (Google), Animesh Singh (IBM), and Ellis Bigelow (Google).
On behalf of the entire community, we are proud to announce Kubeflow 1.0, our first major release. Kubeflow was open sourced at Kubecon USA in December 2017, and during the last two years the Kubeflow Project has grown beyond our wildest expectations. There are now hundreds of contributors from over 30 participating organizations.
Kubeflow?s goal is to make it easy for machine learning (ML) engineers and data scientists to leverage cloud assets (public or on-premise) for ML workloads. You can use Kubeflow on any Kubernetes-conformant cluster.
With 1.0, we are graduating a core set of stable applications needed to develop, build, train, and deploy models on Kubernetes efficiently. (Read more in Kubeflow?s versioning policies and application requirements for graduation.)
Graduating applications include:
- Kubeflow?s UI, the central dashboard
- Jupyter notebook controller and web app
- Tensorflow Operator (TFJob) and PyTorch Operator for distributed training
- kfctl for deployment and upgrades
- Profile controller and UI for multiuser management
Hear more about Kubeflow?s mission and 1.0 release in this interview with Kubeflow founder and core contributor Jeremy Lewi on the Kubernetes Podcast.
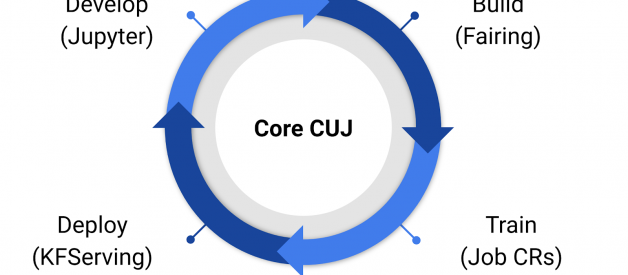
Develop, Build, Train, and Deploy with Kubeflow
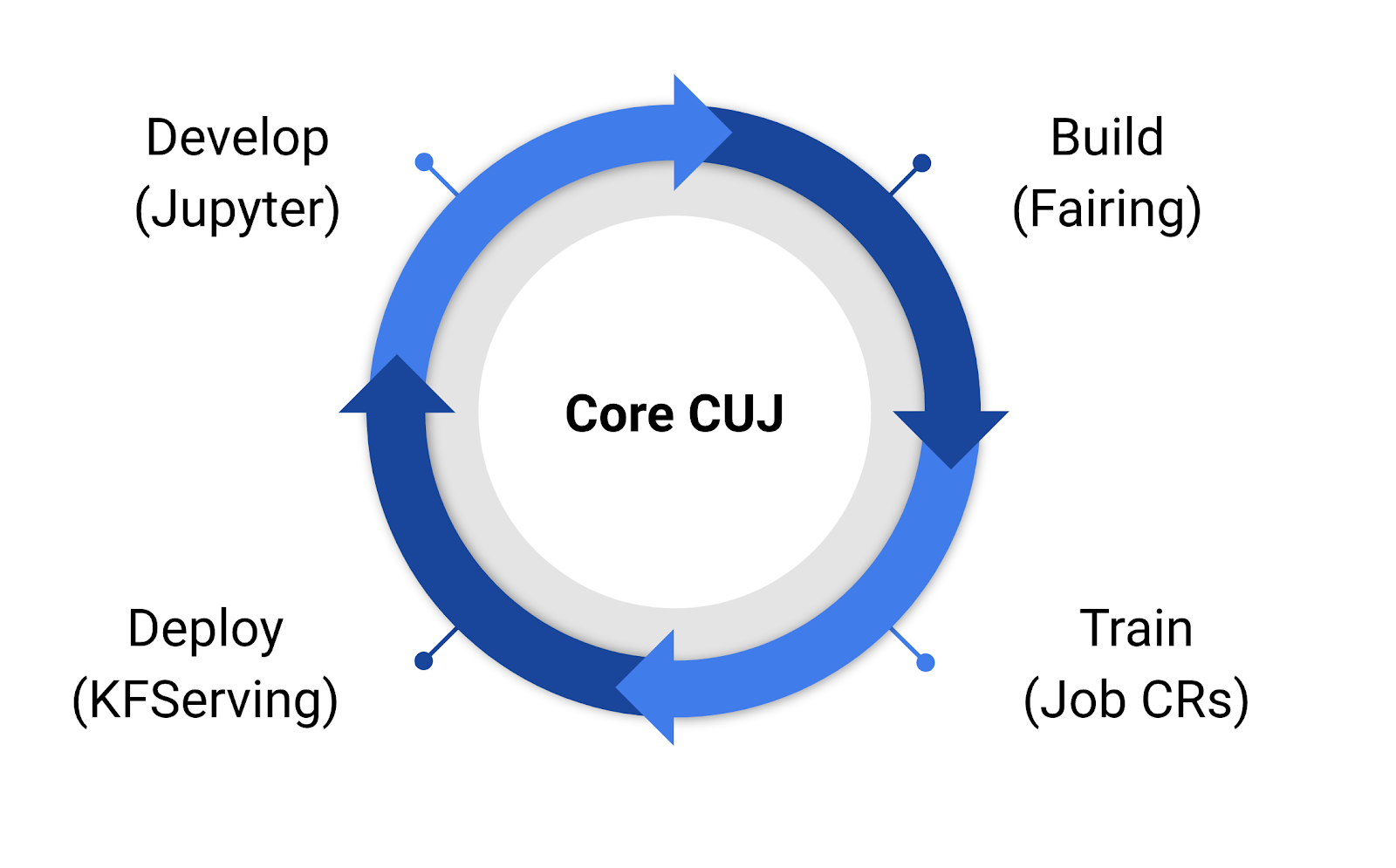 Kubeflow?s 1.0 applications that make up our develop, build, train, deploy critical user journey.
Kubeflow?s 1.0 applications that make up our develop, build, train, deploy critical user journey.
With Kubeflow 1.0, users can use Jupyter to develop models. They can then use Kubeflow tools like fairing (Kubeflow?s python SDK) to build containers and create Kubernetes resources to train their models. Once they have a model, they can use KFServing to create and deploy a server for inference.
Getting Started with ML on Kubernetes
Kubernetes is an amazing platform for leveraging infrastructure (whether on public cloud or on-premises), but deploying Kubernetes optimized for ML and integrated with your cloud is no easy task. With 1.0 we are providing a CLI and configuration files so you can deploy Kubeflow with one command:
kfctl apply -f kfctl_gcp_iap.v1.0.0.yamlkfctl apply -f kfctl_k8s_istio.v1.0.0.yamlkfctl apply -f kfctl_aws_cognito.v1.0.0.yamlkfctl apply -f kfctl_ibm.v1.0.0.yaml
Jupyter on Kubernetes
In Kubeflow?s user surveys, data scientists have consistently expressed the importance of Jupyter notebooks. Further, they need the ability to integrate isolated Jupyter notebooks with the efficiencies of Kubernetes on Cloud to train larger models using GPUs and run multiple experiments in parallel. Kubeflow makes it easy to leverage Kubernetes for resource management and put the full power of your datacenter at the fingertips of your data scientist.
With Kubeflow, each data scientist or team can be given their own namespace in which to run their workloads. Namespaces provide security and resource isolation. Using Kubernetes resource quotas, platform administrators can easily limit how much resources an individual or team can consume to ensure fair scheduling.
After deploying Kubeflow, users can leverage Kubeflow?s central dashboard for launching notebooks:
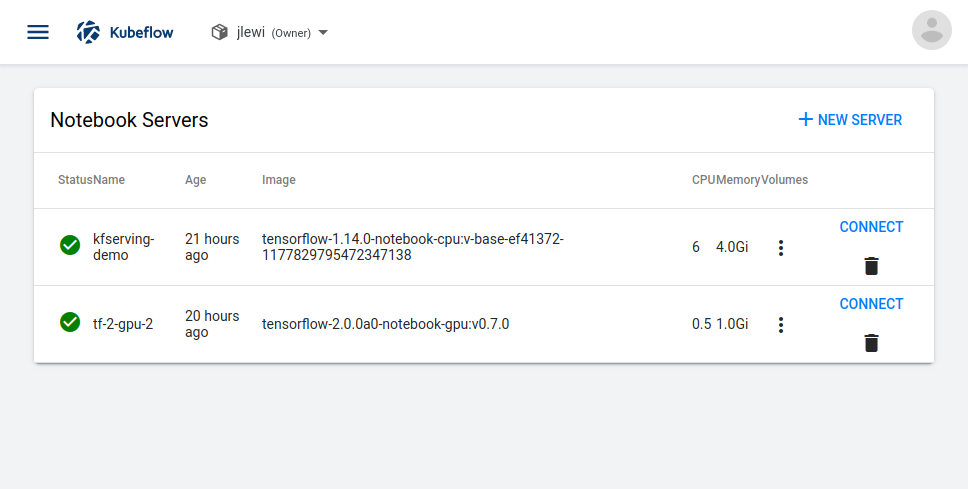 Kubeflow?s UI for managing notebooks: view and connect to existing notebooks or launch a new one.
Kubeflow?s UI for managing notebooks: view and connect to existing notebooks or launch a new one.
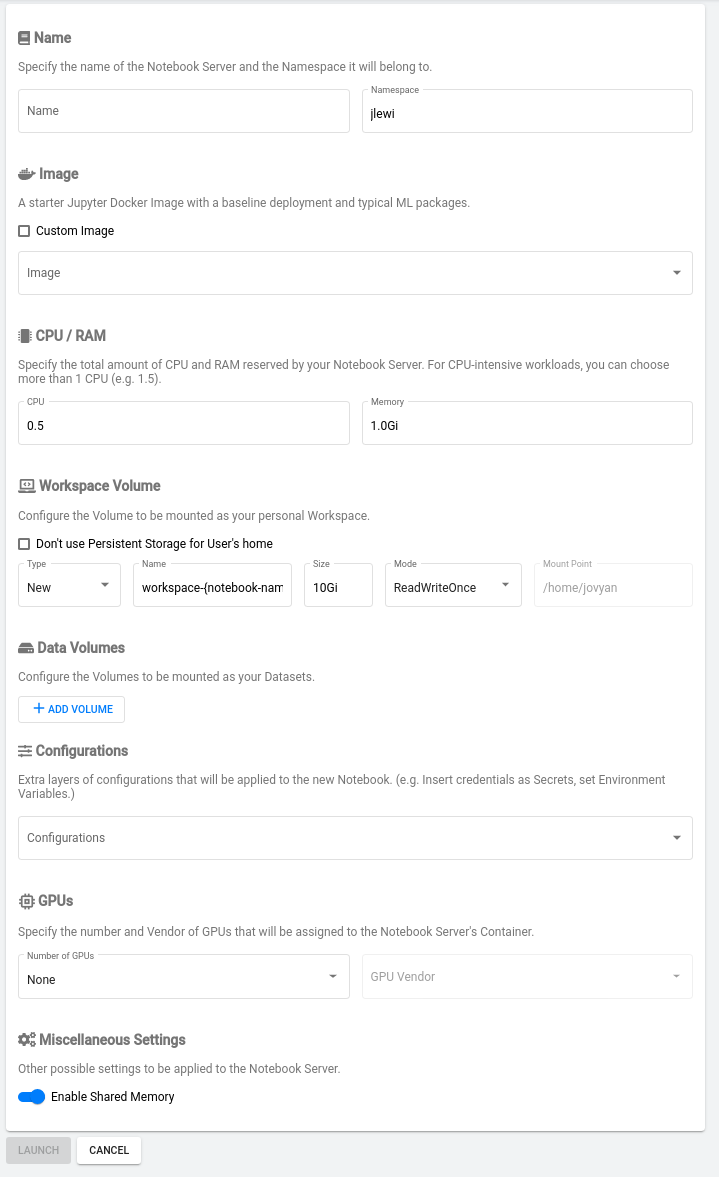
In the Kubeflow UI users can easily launch new notebooks by choosing one of the pre-built docker images for Jupyter or entering the URL of a custom image. Next, users can set how many CPUs and GPUs to attach to their notebook. Notebooks can also include configuration and secrets parameters which simplify access to external repositories and databases.
Training faster with distributed training
Distributed training is the norm at Google (blog), and one of the most exciting and requested features for deep learning frameworks like TensorFlow and PyTorch.
When we started Kubeflow, one of our key motivations was to leverage Kubernetes to simplify distributed training. Kubeflow provides Kubernetes custom resources that make distributed training with TensorFlow and PyTorch simple. All a user needs to do is define a TFJob or PyTorch resource like the one illustrated below. The custom controller takes care of spinning up and managing all of the individual processes and configuring them to talk to one another:
Monitoring Model Training With TensorBoard
To train high quality models, data scientists need to debug and monitor the training process with tools like Tensorboard. With Kubernetes and Kubeflow, userscan easily deploy TensorBoard on their Kubernetes cluster by creating YAML files like the ones below. When deploying TensorBoard on Kubeflow, users can take advantage of Kubeflow?s AuthN and AuthZ integration to securely access TensorBoard behind Kubeflow?s ingress on public clouds:
// On GCP: https://${KFNAME}.endpoints.${PROJECT}.cloud.goog/mnist/kubeflow-mnist/tensorboard/// On AWS:http://8fb34ebe-istiosystem-istio-2af2-925939634.us-west-2.elb.amazonaws.com/mnist/anonymous/tensorboard/
No need to `kubectl port-forward` to individual pods.
Deploying Models
KFServing is a custom resource built on top of Knative for deploying and managing ML models. KFServing offers the following capabilities not provided by lower level primitives (e.g. Deployment):
- Deploy your model using out-of-the-box model servers (no need to write your own flask app)
- Auto-scaling based on load, even for models served on GPUs
- Safe, controlled model rollout
- Explainability (alpha)
- Payload logging (alpha)
Below is an example of a KFServing spec showing how a model can be deployed. All a user has to do is provide the URI of their model file using storageUri:
Check out the samples to learn how to use the above capabilities.
Solutions are More Than Models
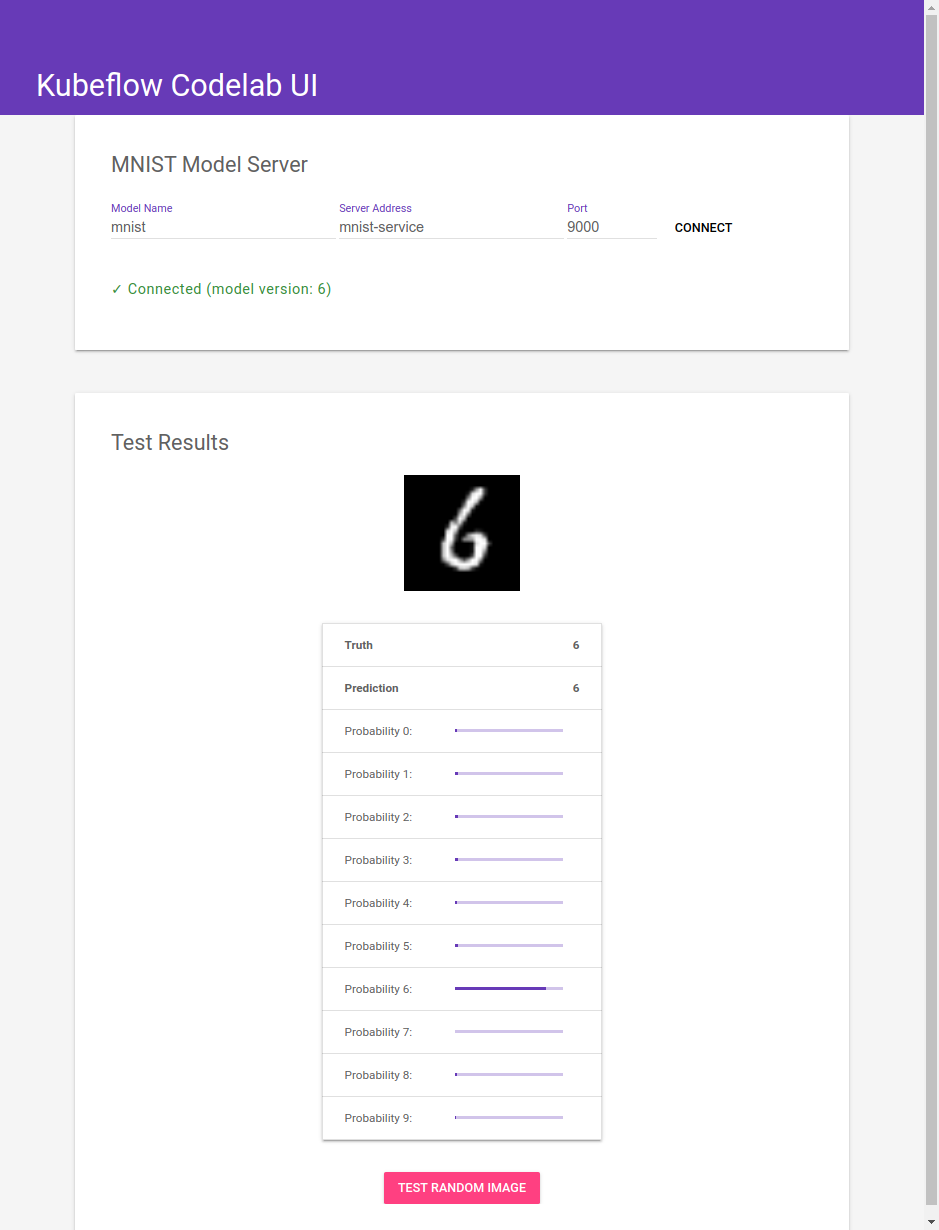
A model gathering dust in object storage isn?t doing your organization any good. To put ML to work, you typically need to incorporate that model into an application ? whether it?s a web application, mobile app, or part of some backend reporting pipeline.
Frameworks like flask and bootstrap make it easy for data scientists to create rich, visually appealing web applications that put their models to work. Below is a screenshot of the UI we built for Kubeflow?s mnist example.
With Kubeflow, there is no need for data scientists to learn new concepts or platforms to deploy their applications, or to deal with ingress, networking certificates, etc. They can deploy their application just like TensorBoard; the only thing that changes is the Docker image and flags.
If this sounds like just what you are looking for we recommend:
1. Visiting our docs to learn how to deploy Kubeflow on your public or private cloud.
2. Walking through the mnist tutorial to try our core applications yourself.
What?s coming in Kubeflow
There?s much more to Kubeflow than what we?ve covered in this blog post. In addition to the applications listed here, we have a number of applications under development:
- Pipelines (beta) for defining complex ML workflows
- Metadata (beta) for tracking datasets, jobs, and models,
- Katib (beta) for hyper-parameter tuning
- Distributed operators for other frameworks like xgboost
In future releases we will be graduating these applications to 1.0.
User testimonials
All this would be nothing without feedback from and collaboration with our users. Some feedback from people using Kubeflow in production include:
?The Kubeflow 1.0 release is a significant milestone as it positions Kubeflow to be a viable ML Enterprise platform. Kubeflow 1.0 delivers material productivity enhancements for ML researchers.? ? Jeff Fogarty, AVP ML / Cloud Engineer, US Bank
?Kubeflow?s data and model storage allows for smooth integration into CI/CD processes, allowing for a much faster and more agile delivery of machine learning models into applications.? ? Laura Schornack, Shared Services Architect, Chase Commercial Bank
?With the launch of Kubeflow 1.0 we now have a feature complete end-to-end open source machine learning platform, allowing everyone from small teams to large unicorns like Gojek to run ML at scale.? ? Willem Pienaar, Engineering Lead, Data Science Platform, GoJek
?Kubeflow provides a seamless interface to a great set of tools that together manages the complexity of ML workflows and encourages best practices. The Data Science and Machine Learning teams at Volvo Cars are able to iterate and deliver reproducible, production grade services with ease.?? Leonard Aukea, Volvo Cars
?With Kubeflow at the heart of our ML platform, our small company has been able to stack models in production to improve CR, find new customers, and present the right product to the right customer at the right time.? ? Senior Director, One Technologies
?Kubeflow is helping GroupBy in standardizing ML workflows and simplifying very complicated deployments!? ? Mohamed Elsaied, Machine Learning Team Lead, GroupBy
Thank You!
None of this would have been possible without the tens of organizations and hundreds of individuals that have been developing, testing, and evangelizing Kubeflow.

An Open Community
We could not have achieved our milestone without an incredibly active community. Please come aboard!
- Join the Kubeflow Slack channel
- Join the kubeflow-discuss mailing list
- Attend a weekly community meeting
- If you have questions, run into issues, please leverage the Slack channel and/or submit bugs via Kubeflow on GitHub.
Thank you all so much ? onward!


{kind=link}
{kind=link}