Non Maximum Suppression (NMS) is a technique used in many computer vision algorithms. It is a class of algorithms to select one entity (e.g. bounding boxes) out of many overlapping entities. The selection criteria can be chosen to arrive at particular results. Most commonly, the criteria is some form of probability number along with some form of overlap measure (e.g. IOU).
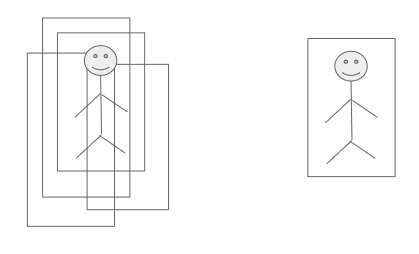 Before NMS and after NMS
Before NMS and after NMS
Most object detection algorithms use NMS to whittle down a large number of detected rectangles to a few. The need for NMS arises because of the way object detection works in most cases ( e.g. Faster RCNN, Yolo V3, SSD, etc). At the most basic level, most object detectors do some form of windowing. Many, thousands, windows of various size and shapes are generated either directly on the image or on a feature of the image ( e.g. after a deep CNN such as ResNet). These windows supposedly contain only one object, and a classifier is used to obtain a probability/score for each classes. Once the detector outputs the large number of bounding boxes, it is necessary to pick the best ones. NMS is the most commonly used algorithm for this task. In essence it is a form of clustering algorithm. Attempts have been made to use standard clustering algorithms such as k-means, Nearest Neighbor, DB Scan, etc. in object detection.
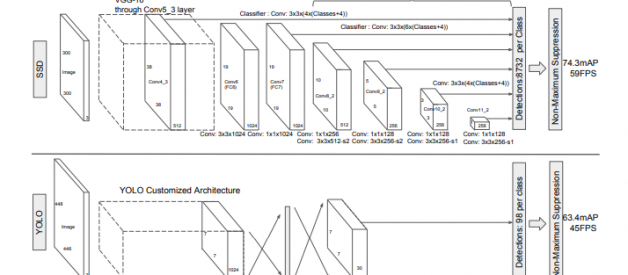
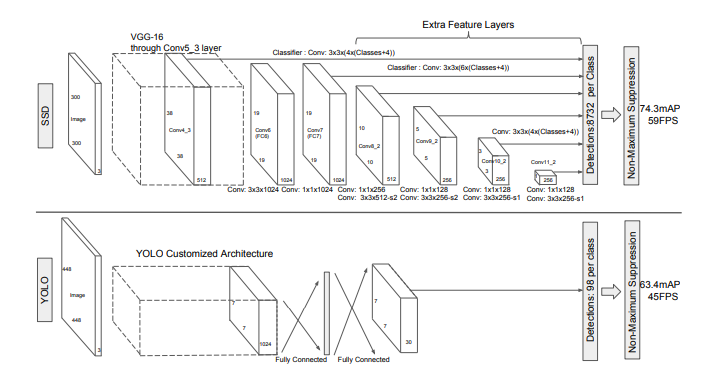 SSD and Yolo object detection networks ( from 12) .
SSD and Yolo object detection networks ( from 12) .
NMS has been implemented in most deep learning platforms ( Tensorflow, PyTorch, etc.) and in the well known computer vision software OpenCV. In most of the frameworks, there are implementations for both CPU and GPU.
The OpenCV CPU algorithm is roughly as follows[1].
select only rectangles above a confidence thresholdsort the thresholded rectangles in descending ordercreate an empty set of kept rectangleloop over the sorted thresholded rectangles: loop over the set of kept rectangles: compute IOU between the rectangles if IOU is above IOU threshold break loop if all IOU are below the IOU threshold add to kept
Tensorflow (version 1.15) has multiple NMS CPU Ops, however all of them seem to end up calling one particular function [2, 3] called NonMaxSuppressionOp. The basic algorithm is roughly as follows.
create a priority queue of rectangles based on their scorescreate an empty set of selected rectanglesloop over priority queue : loop over selected set : compute IOU between rectangles if IOU above threshold break loop if loop did not break add priority queue rectangle to selected set
Tensorflow NMS also incorporates Soft NMS [4]. Soft NMS dynamically lowers the score value ( of the rectangle not in the selected set) based on the just computed NMS. A higher score is assigned when there is higher overlap ? intuitively this means a box has higher chance of rejection if it has higher overlap . Soft NMS appears to help in detecting similar objects close to each (i.e. have high IOU) and can result in 1?3% higher mAP.
Tensorflow also has GPU (e.g. CUDA) implementations of NMS [5]. The algorithm is as follows.
radix sort rectangles in score descending order(DeviceRadixSort)flip boxes to get x1<x2 and y1<y2 if necessary for each box, compute bitmask of other boxes with IOU > threshold (NMSKernel)build a global bit mask for selected boxes (NMSReduce) (each thread handles a number of boxes) make all bits of bitmask 0xFFFFFFF (e.g. all boxes are selected) loop over all boxes if the bit corresponding to the box is still 1 Bitwise AND inverse of this thread’s box of global mask with bitmask of box
The code of all of the above steps are run in parallel, although with different number of threads. Only 1024 threads are used for the NMSReduce kernel as the shared bitmask has to be placed in the local memory of a block. Whereas NMSKernel uses many more threads, for example 128*128*16*16= 2^(7+7+4+4) = 2 .
The scaling of NMS becomes important as the resolution of input images increases. Higher resolution translates into more number of anchor boxes. The scaling of the Tensorflow GPU NMS algorithm with number of input boxes shows a non-linear trend with the exponent less than 2 ( for the range tested on). The following chart shows that trend.
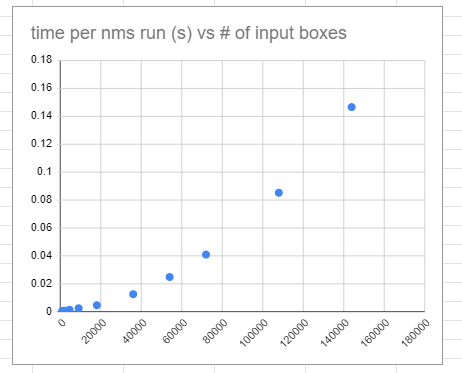 NMS execution time vs number of input boxes.
NMS execution time vs number of input boxes.
The execution time does not appear to depend on the number of distinct boxes ( e.g. boxes with are distinct and has no overlap). The following chart shows almost a flat line.
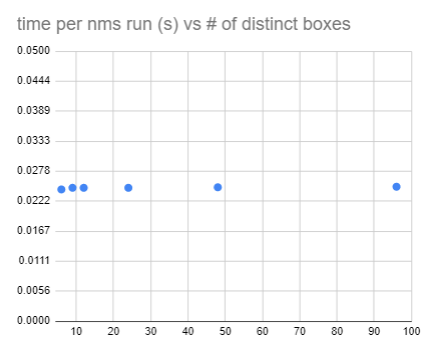 NMS execution time vs number of distinct ( non-overlapping) boxes, with input boxes fixed at 54000.
NMS execution time vs number of distinct ( non-overlapping) boxes, with input boxes fixed at 54000.
Performance of NMS is important when real-time object detection is at stake. Common NMS?s are greedy in nature and O(n**2) in performance. In [7] authors introduce an alternative way. In [9] the authors provide parallel algorithms for GPU. In [10] the algorithm of [9] is improved. According to results from [12], NMS adds 10% to inference latency ( 1.7 msec out of ~ 17 msec) .
In [8] an experimental comparison and code of Tensorflow?s NMS performance in CPU and GPU are made, and found that under normal uses, the GPU version is almost 3 times slower than the CPU version ! [11] provides some Cuda codes for experimenting with a number of NMS custom ops for Tensorflow 1.x. A simple alternative version of NMS code seems to be able to do 2.4x better than the Tensorflow code ! The algorithm roughly is as follows.
radix sort rectangles in score descending order(CUB DeviceRadixSort)run the kernel as follows for each rectangle calculate IOU with each rectangle lower in score if IOU is above threshold mark by setting -1 in the indexextract the non -1 indices (CUB DeviceSelect::If)
In [13], the authors found ways to subtly modify images so that criteria used by NMS is impacted ( e.g. IOU threshold) , which results in many more boxes left unremoved, and thus makes it inaccurate.
References:
- OpenCV NMS https://github.com/opencv/opencv/blob/master/modules/dnn/src/nms.inl.hpp
- tf.image.non_max_suppression https://www.tensorflow.org/versions/r1.15/api_docs/python/tf/image/non_max_suppression
- Tensorflow 1.15 NMS ? CPU https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/non_max_suppression_op.cc
- Improving Object Detection With One Line of Code https://arxiv.org/pdf/1704.04503.pdf
- Tensorflow 1.15 NMS ? GPU https://github.com/tensorflow/tensorflow/blob/r1.15/tensorflow/core/kernels/non_max_suppression_op.cu.cc
- Learning non-maximum suppression, http://openaccess.thecvf.com/content_cvpr_2017/papers/Hosang_Learning_Non-Maximum_Suppression_CVPR_2017_paper.pdf
- MaxpoolNMS: Getting Rid of NMS Bottlenecks in Two-Stage Object Detectors, http://openaccess.thecvf.com/content_CVPR_2019/papers/Cai_MaxpoolNMS_Getting_Rid_of_NMS_Bottlenecks_in_Two-Stage_Object_Detectors_CVPR_2019_paper.pdf
- non_max_suppression GPU version is 3x slower than CPU version in TF 1.15, https://github.com/tensorflow/tensorflow/issues/33708
- WORK-EFFICIENT PARALLEL NON-MAXIMUM SUPPRESSION FOR EMBEDDED GPU ARCHITECTURES, http://rapid-project.eu/_docs/icassp2016.pdf
- An efficient end-to-end object detection pipeline on GPU using CUDA, https://pure.tue.nl/ws/portalfiles/portal/130181034/Wang_XiaoweiMaster_Thesis_3_.pdf
- Code to experiment with NMS ops( or other ops) in Tensorflow 1.x., https://github.com/whatdhack/tf-nms .
- SSD: Single Shot MultiBox Detector, https://arxiv.org/pdf/1512.02325.pdf .
- Daedalus: Breaking Non-Maximum Suppression in Object Detection via Adversarial Examples, https://arxiv.org/abs/1902.02067


){kind=link}
){kind=link}