Deep Learning
Outperforms SRCNN, EDSR and RCAN, and SRGAN. Also, won the First Place in PIRM2018-SR challenge
 ESRGAN can have a sharper result than SRGAN
ESRGAN can have a sharper result than SRGAN
In this story, Enhanced Super-Resolution Generative Adversarial Networks (ESRGAN), by The Chinese University of Hong Kong, Chinese Academy of Sciences, University of Chinese Academy of Sciences, and Nanyang Technological University, is described. In ESRGAN:
- Residual-in-Residual Dense Block (RRDB) without batch normalization is introduced.
- Idea from relativistic GAN is used to let the discriminator predict relative realness instead of the absolute value.
- The perceptual loss of using the features before activation is used, which provides stronger supervision for brightness consistency and texture recovery.
And finally, ESRGAN won the First Place in PIRM2018-SR challenge. This is a paper in 2018 ECCVW (ECCV Workshop) with more than 300 citations. (Sik-Ho Tsang @ Medium)
Outline
- Perceptual Quality and Objective Quality
- Residual-in-Residual Dense Block (RRDB)
- Relativistic GAN
- Perceptual Loss
- Network Interpolation
- Ablation Study
- SOTA Comparison
1. Perceptual Quality and Objective Quality
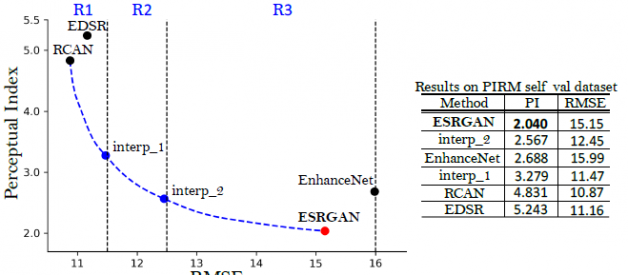
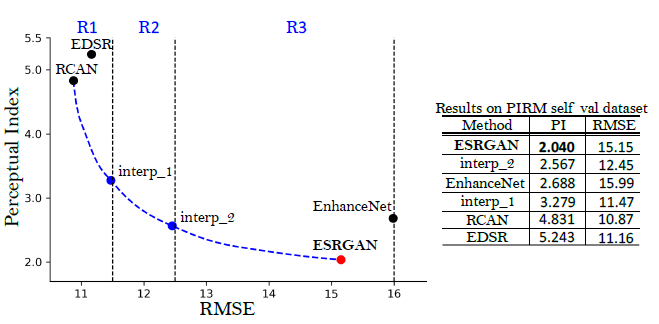 Perceptual Quality and Objective Quality
Perceptual Quality and Objective Quality
- RMSE is a measure of objective quality. Higher RMSE, lower objective quality. It is measured in an objective way.
- Perceptual Index (PI) is a measure of perceptual quality. Higher PI, lower perceptual quality. Perceptual quality is a quality which is much close to human eyes.
- ESRGAN intends to improve perceptual quality rather than objective quality, such as PSNR.
2. Residual-in-Residual Dense Block (RRDB)
 The basic architecture of SRResNet/SRGAN
The basic architecture of SRResNet/SRGAN RRDB is used as Basic Block in ESRGAN
RRDB is used as Basic Block in ESRGAN
- First, Batch Normalization (BN) is removed. Removing BN layers has proven to increase performance and reduce the computational complexity in different PSNR-oriented tasks, including SR. Because BN brings artifacts.
- Second, the Dense block, originated in DenseNet, is used to replace the residual block to enhance the network. (Please feel free to read my story about DenseNet if interested.)
3. Relativistic GAN
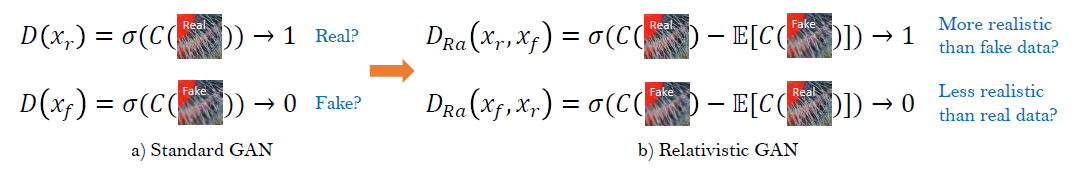 Difference between the standard discriminator and relativistic discriminator
Difference between the standard discriminator and relativistic discriminator
- The standard discriminator D in SRGAN, which estimates the probability that one input image x is real and natural.
- (If interested, please read my story about GAN and SRGAN.)
- In contrast, a relativistic discriminator tries to predict the probability that a real image XR is relatively more realistic than a fake one xf.
- The standard discriminator with the Relativistic average Discriminator Dra.
- E is the operation of taking the average for all fake data in the mini-batch. The discriminator loss is:
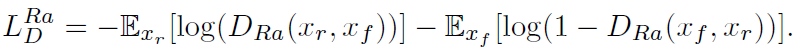
- The adversarial loss for the generator is in a symmetrical form:
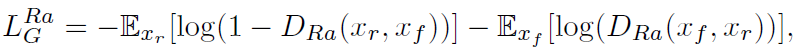
- It is observed that the adversarial loss for the generator contains both XR and xf. Therefore, the generator benefits from the gradients from both generated data and real data in adversarial training, while in SRGAN, only generated part takes effect.
4. Perceptual Loss
- In ESRGAN, the features before the activation layers are used.
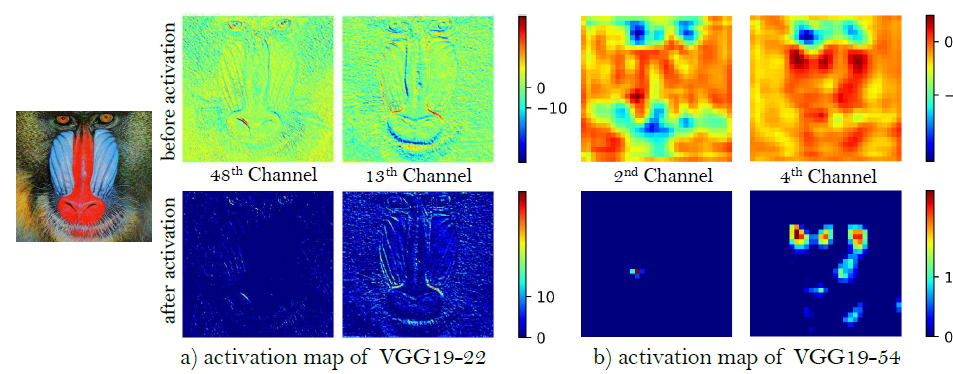 Example of feature maps before and after activation
Example of feature maps before and after activation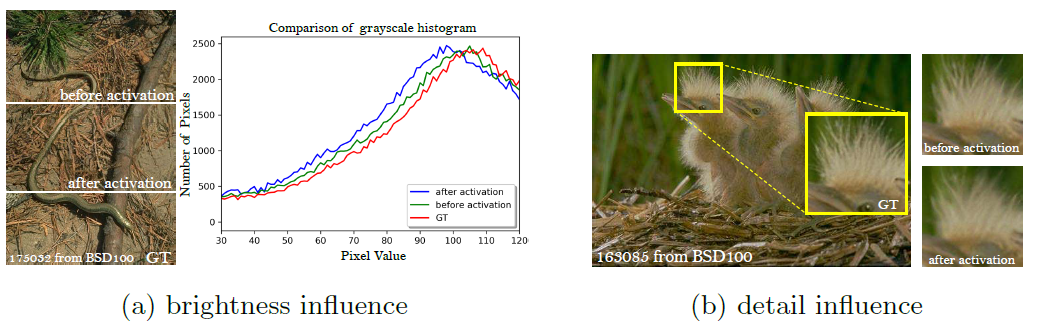 Example of influence for feature maps before and after activation
Example of influence for feature maps before and after activation
- If features after activation layers are used, there would be drawbacks:
- First, the activated features are very sparse, as shown above, especially after a very deep network. For example, the average percentage of activated neurons for image ?baboon? after the VGG19?546 layer is merely 11.17%. The sparse activation provides weak supervision and thus leads to inferior performance.
- Second, using features after activation also causes inconsistent reconstructed brightness compared with the ground-truth image.
- Therefore, the total loss is:
![]()
- where Lpercep is the VGG loss, LGRA is the adversarial loss, and L1 is the standard L1 loss, which is act as a content loss.
- (In the PIRM-SR challenge, another loss called MINC loss is used. But I don?t mention it in detail since it is also not mentioned in the paper.)
4. Network Interpolation
- First, we train a PSNR-oriented network GPSNR, and then we obtain a GAN-based network GGAN by fine-tuning.
- All the corresponding parameters of these two networks are interpolated to derive an interpolated model GINTERP:
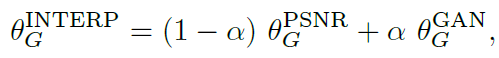
- where ? is between 0 to 1. There are two merits:
- First, the interpolated model is able to produce meaningful results for any feasible without introducing artifacts.
- Second, we can continuously balance perceptual quality and fidelity without re-training the model.
5. Ablation Study
5.1. Data
- Training Data: DIV2K that contains 800 images, Flickr2K dataset that consisting of 2650 2K high-resolution images, and OutdoorSceneTraining (OST) dataset are used.
- Models are trained in RGB channels, and the training dataset is augmented with random horizontal flips and 90-degree rotations.
- Benchmark Dataset: Set5, Set14, BSD100, Urban100 and PIRM Self-Validation Dataset.
5.2. Ablation Experiments
 Ablation Experiments
Ablation Experiments
- BN Removal (3rd column): Slight improvement is observed over the 2nd column.
- Before Activation in Perceptual Loss (4th column): Sharper edges and richer textures are produced compared to the 3rd column.
- RaGAN (5th column): Again, sharper edges and more detailed textures are learned to produce compared to the 4th column.
- Deeper network with RRDB (6th column): The proposed RRDB can further improve the recovered textures, especially for the regular structures like the roof of image 6, since the deep model has a strong representation capacity to capture semantic information.
5.3. Network Interpolation

- ? is chosen from 0 to 1 with an interval of 0.2.
- The pure GAN-based method produces sharp edges and richer textures but with some unpleasant artifacts, while the pure PSNR-oriented method outputs cartoon-style blurry images.
- By employing network interpolation, unpleasing artifacts are reduced while the textures are maintained.
7. SOTA Comparison
7.1. Benchmark Dataset
 The number at the left: PSNR, Number at the right: Perceptual Index (PI)
The number at the left: PSNR, Number at the right: Perceptual Index (PI)
- PSNR-oriented methods such as SRCNN, EDSR, and RCAN, tend to generate blurry results
- Previous GAN-based methods, i.e., EnhanceNet and SRGAN, tend to produce textures that are unnatural and contain unpleasing noise.
- ESRGAN gets rid of these artifacts and produces natural results.
7.2. PIRM-SR Challenge
- ESRGAN with 16 residual blocks with MINC loss is used. (There are also other details.)
- And it won the first place in the PIRM-SR Challenge (Region 3) with the best perceptual index (PI).
During the days of coronavirus, let me have a challenge of writing 30 stories again for this month ..? Is it good? This is the 16th story in this month. Thanks for visiting my story..
Reference
[2018 ECCVW] [ESRGAN]ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks
Super Resolution
[SRCNN] [FSRCNN] [VDSR] [ESPCN] [RED-Net] [DnCNN] [DRCN] [DRRN] [LapSRN & MS-LapSRN] [MemNet] [IRCNN] [WDRN / WavResNet] [MWCNN] [SRDenseNet] [SRGAN & SRResNet] [EDSR & MDSR] [MDesNet] [RDN] [SRMD & SRMDNF] [DBPN & D-DBPN] [RCAN] [ESRGAN] [SR+STN]
Generative Adversarial Network
[GAN] [CGAN] [LAPGAN] [DCGAN] [SRGAN & SRResNet]
My Other Previous Readings
Published via Towards AI

){kind=link}
){kind=link}