Just about every computer available has some capacity for parallelization. The computer I?m working on is 7 years old, has a single processor, but has the capability of 8 cores (four real, four virtual).
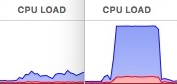 The benefits of parallelization: on the left: single process; on the right: multi-process.
The benefits of parallelization: on the left: single process; on the right: multi-process.
Fortunately, functions in popular packages, like the scikit-learn models, have parameters to accommodate parallelization, like n_jobs. However, a lot of the day-to-day data manipulation in Python doesn?t take advantage of these off-the-shelf capabilities inherent in our computers. Repetitive, iterative operations crawl along and take forever, like text cleaning and data preparation for natural language processing.
In the course of my work, I was introduced to the parallelization capabilities of Python ? and it?s turbo-charged my workflow.
It?s actually surprisingly simple to implement parallelization with the multiprocessing and joblib libraries in python.
Breaking this down:
multiprocessing.cpu_count() gets the number of cores, and by extension, the number of jobs the computer can handle.
inputs stores set of items that we want our function to iterate over. I?ve generally been working with lists or pandas Series.
if __name__ == “__main__”: this sets up our parallel process to run inside the __main__ module. More on why that?s necessary here.
processed_list is an object to hold the result of our function.
From right to left:
delayed(my_function(i,parameters) for i in inputs) behind the scenes creates tuple of the function, i, and the parameters, one for each iteration. Delayed creates these tuples, then Parallel will pass these to the interpreter.
Parallel(n_jobs=num_cores) does the heavy lifting of multiprocessing. Parallel forks the Python interpreter into a number of processes equal to the number of jobs (and by extension, the number of cores available). Each process will run one iteration, and return the result. Read more here.
Implementation
Writing custom functions that can be parallelized is a little tricky because it requires us to think more carefully about our inputs and outputs. What do I mean by that?
If we wrote a function like:
The function will peel one element of the list, do something, then return the result. With Parallel and delayed(), we start one level up. Instead of passing a list of elements to my_function, we pass a single element of myListto my_function at a time.
In the above example, if myList was a list of strings, Parallel and delayed() would iterate over each character in the string!
Thinking about the outputs now: if the result we expect from our function was supposed to be the sum of every element in myList squared, we would be surprised when our parallelized function returned a list of the squared elements!
Because these small operations are spread out over all the cores as a tuple, each job processes 1 element, then puts all the elements back together at the end. It?s like a list comprehension on steroids.
In our example above, when we were expecting my_function to return 1 quantity, Parallel and delayed() return 1 quantity for each element!
Bonus: wrapping the myList in a tqdm() is a convenient way to monitor the progress of the parallelized process ? and see its benefits.
Wrapping our iterable in a tqdm will let us monitor progress with a status bar
Parallelizing in Python can be really easy. Understanding the structure and function of Parallel and delayed() unlocks the ability to effectively write your own custom functions that scale and efficiently use your computer?s time ? and your own.
You can check out my other blog posts here. Thanks for reading!

{kind=link}
{kind=link}