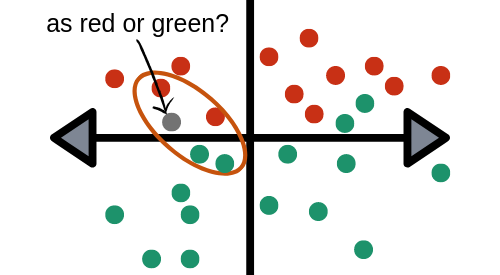
Part 1 of a Series on Introductory Machine Learning Algorithms

Introduction
If you?re familiar with machine learning and the basic algorithms that are used in the field, then you?ve probably heard of the k-nearest neighbors algorithm, or KNN. This algorithm is one of the more simple techniques used in machine learning. It is a method preferred by many in the industry because of its ease of use and low calculation time.
What is KNN? KNN is a model that classifies data points based on the points that are most similar to it. It uses test data to make an ?educated guess? on what an unclassified point should be classified as.
Pros:
- Easy to use.
- Quick calculation time.
- Does not make assumptions about the data.
Cons:
- Accuracy depends on the quality of the data.
- Must find an optimal k value (number of nearest neighbors).
- Poor at classifying data points in a boundary where they can be classified one way or another.
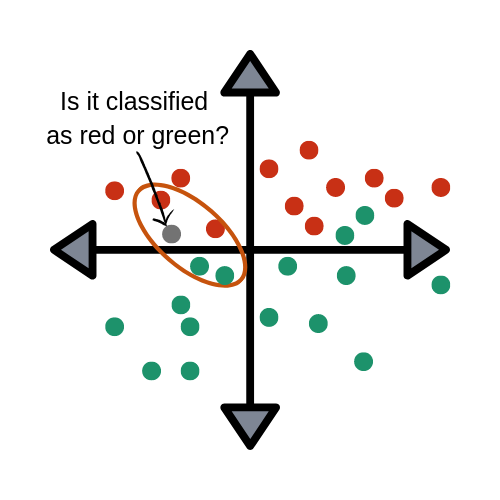
KNN is an algorithm that is considered both non-parametric and an example of lazy learning. What do these two terms mean exactly?
- Non-parametric means that it makes no assumptions. The model is made up entirely from the data given to it rather than assuming its structure is normal.
- Lazy learning means that the algorithm makes no generalizations. This means that there is little training involved when using this method. Because of this, all of the training data is also used in testing when using KNN.
Where to use KNN
KNN is often used in simple recommendation systems, image recognition technology, and decision-making models. It is the algorithm companies like Netflix or Amazon use in order to recommend different movies to watch or books to buy. Netflix even launched the Netflix Prize competition, awarding $1 million to the team that created the most accurate recommendation algorithm!
You might be wondering, ?But how do these companies do this?? Well, these companies will apply KNN on a data set gathered about the movies you?ve watched or the books you?ve bought on their website. These companies will then input your available customer data and compare that to other customers who have watched similar movies or bought similar books. This data point will then be classified as a certain profile based on their past using KNN. The movies and books recommended will then depend on how the algorithm classifies that data point.
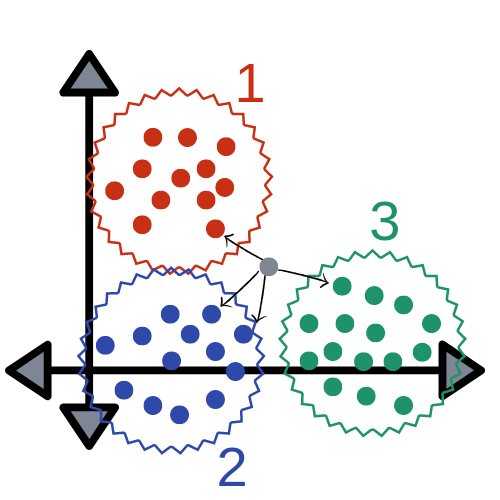
The image above visualizes how KNN works when trying to classify a data point based a given data set. It is compared to its nearest points and classified based on which points it is closest and most similar to. Here you can see the point Xj will be classified as either W1 (red) or W3 (green) based on its distance from each group of points.
The Mathematics Behind KNN
Just like almost everything else, KNN works because of the deeply rooted mathematical theories it uses. When implementing KNN, the first step is to transform data points into feature vectors, or their mathematical value. The algorithm then works by finding the distance between the mathematical values of these points. The most common way to find this distance is the Euclidean distance, as shown below.
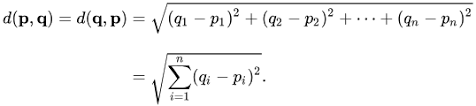
KNN runs this formula to compute the distance between each data point and the test data. It then finds the probability of these points being similar to the test data and classifies it based on which points share the highest probabilities.
To visualize this formula, it would look something like this:
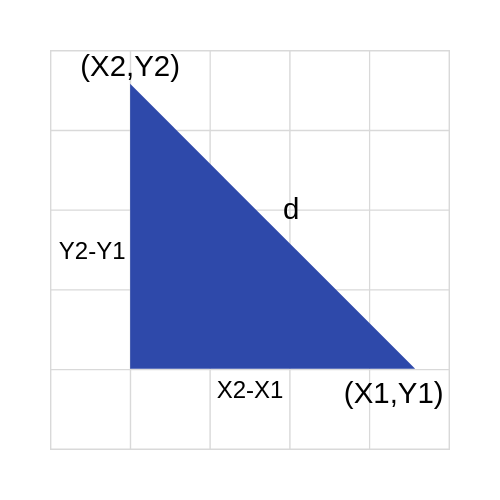
Conclusion
Now you know the fundamentals of one of the most basic machine learning algorithms. It?s a great place to start when first learning to build models based on different data sets. If you have a data set with a lot of different points and accurate information, this is a great place to begin exploring machine learning with KNN.
When looking to begin using this algorithm keep these three points in mind:
- First, find a data set that will be easy to work with, ideally one with lots of different points and labeled data.
- Second, figure out which language will be easiest for use to solve the problem. I am most familiar with using KNN in R, but Python is also a popular language with machine learning professionals.
- Third, do your research. It is important to learn the correct practices for using this algorithm so you are finding the most accurate results from your data set.
There have been various studies conducted on how this algorithm can be improved. These studies aim to make it so you can weigh categories differently in order to make a more accurate classification. The weighting of these categories varies depending on how the distance is calculated.
In conclusion, this is a fundamental machine learning algorithm that is dependable for many reasons like ease of use and quick calculation time. It is a good algorithm to use when beginning to explore the world of machine learning, but it still has room for improvement and modification.
For more resources, check out some projects using k-nearest neighbors:
- Hand-Written Digit Recognition
- Scikit-Learn
- KNN Using Python
Related:
- K-Means Clustering Algorithm for Machine Learning
- Naives Bayes Classifiers for Machine Learning
- Random Forest Algorithm for Machine Learning
- Artificial Neural Networks for Machine Learning
DISCLOSURE STATEMENT: 2019 Capital One. Opinions are those of the individual author. Unless noted otherwise in this post, Capital One is not affiliated with, nor endorsed by, any of the companies mentioned. All trademarks and other intellectual property used or displayed are property of their respective owners.

 Algorithm for Machine Learning){kind=link}
 Algorithm for Machine Learning){kind=link}