HashMap is the data structure used in Java to store key-value pairs, where the average retrieval time for get() and put() operations is constant i.e. O(1).
How the java implements it, is discussed in detail below:
Hashmap uses the array of Nodes(named as table), where Node has fields like the key, value (and much more). Here the Node is represented by class HashMapEntry. Basically, HashMap has an array where the key-value data is stored. It calculates the index in the array where the Node can be placed and it is placed there. Now while getting the element from HashMap, it again calculates the index of the element to retrieve and goes to the array index and returns the value of the element/Node(if exists).
So this is the basic functionality of the Hashmap. But it is not as simple, because there can be cases of collision as well. The collision is when 2 elements have the same index. Is it possible?
Yes, any 2 elements can have the same index of the table array. Take for example the Hashmap has initial size = 16(Default size)Now suppose we insert one element(let it be named elementOne)and suppose index is calculated as 2 and hence it will be placed at index 2 of the table array.If we insert one more (let it be named elementTwo)and suppose its index also comes out to be 2, then what will happen in that case? It is the collision scenario.i.e. it is very common in hashmap that more than one element gets the same index in the hashmap table. Here as the size was 4, it could have been that while insertion all the elements get placed in all different indexes, or in the worst case all may point to the same index(collision), so collision cases can occur.
To make hashmap work even in cases of collision we have LinkedList at the array indexes, i.e. as in the above example at index 2 we will have elementTwo -> elementOne i.e. both of these elements at the same index but in the LinkedList Data structure. So while getting back the element, we first calculate the index, then iterate over the LinkedList at that index to get the item.
So as you must have guessed the Node structure must have these things at least:a. keyb. valuec. next
Here next is for the next element in the LinkedList.Apart from these 3, it also has the other field i.e. the hash. Hash is used while comparing 2 Nodes and for calculating the index of the Node.
So the node looks like:
So it has the array of HashMapEntry, with each HashMapEntry pointing to next in case of collision as shown below with gray boxes representing the nodes at their corresponding indexes:
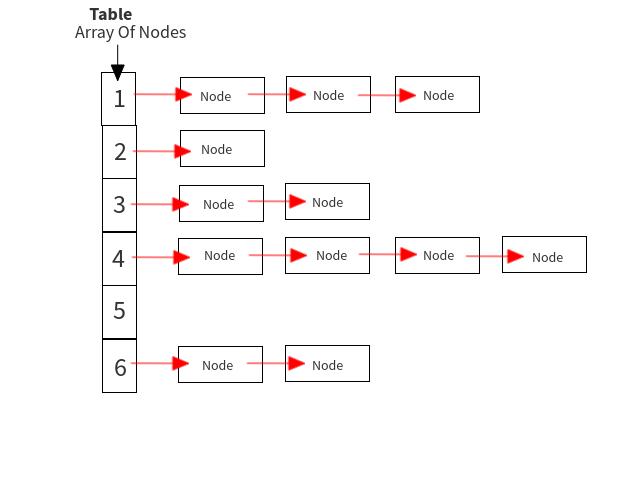
PUT Operation:
Initially, the table is initialized as EMPTY_TABLE like:
So while putting an element it checks if the table is empty, in case its empty the table is inflated, it’s done as:
Here the capacity(maximum size of HashMap) is calculated in the way that it is always the power of 2.
Now 2 cases can rise while inserting the key-value pair.
case 1. The key (of the Node to insert) is nullIf the key is null, the table iterates over the first table index(null Node is always inserted at index 0) to find if there is any null key present already. If there already is a null present the replace its value with the new value, and return the old value.
If there was no Node with the null key already inserted, then insert this Node at 0 indexes. As it is to be inserted at 0th Index, the hash will be 0 and index = 0.Note: We can not calculate the hash of the null Node, so the hashcode of null Node is taken as 0. As the Node is inserted the first time, return null, signifying that there was no Node will null key inserted before.
Note: put() method inserts the Node and returns the previous value if the Node with same Key already existed before. If it is being inserted for the first time then it returns null.
How the Node is added will be discussed later.
case 2. The key(of the Node to insert) is non-nullIn case the key of the Node to be inserted is not null, calculate the following:a. hashcode for the keyb. index to place the Node atThe index is calculated from hashcode and the current length of the table so that the index is always within the array length.Now iterate at the table[index] to check if there already is the Node with same key present or not.
So it iterates at table[i] where (i= index calculated at step: b) and checks if there is the node already present.If the Node is present, its value is replaced and the old value is returned, as done will null case(when there was already Node with the null key present).
NOTE: To check for equality of 2 nodes, both the hashcode and equals come into picture, as observable from the code above.To compare the 2 Nodes, it checks whether their hashcodes are equal, and whether their equals also returns true.So for any object to be treated as the key for the hashmap, we must override the hashcode and the equals method in that object, so that they can be checked against the equality efficiently.
And if there was no such key found, then add the new Node into the hashmap.
Adding the Nodes into hashmap:To add the Node, we need its hashcode, index, key, and value.For Node will null key- the key, hash, index are all 0, and value as provided.For the non-null key node, the hash and index are calculated, and key and value as provided.While adding the new Node, we check if the current size of the Hashmap is more than the threshold value or not.
Threshold has the value which is loadfactor*capacityCapacity is the maximum size of the HashMap
Threshold is set while the table is inflated as below:
float thresholdFloat = capacity * loadFactor;if (thresholdFloat > MAXIMUM_CAPACITY + 1) { thresholdFloat = MAXIMUM_CAPACITY + 1;}threshold = (int) thresholdFloat;
So the threshold means if the current size exceeds this value, then the HashMap needs to be resized.Now threshold is 0.75*capacity i.e. if the current of the hashmap is more than 0.75 of the total size set, then resize it.Also we can set the loadFactor, but its default value is 0.75
So if the size exceeds the threshold then resize the hashmap.In resizing it, calculate the new capacity and copy all the Nodes to the new capacity hashmap.Note: the new size of the HashMap is double the previous size.
Why we need to resize the HashMap? Its because if the size is fixed and as more and more elements are added to the hashmap, then there will be more and more collisions and hence longer linkedlists maintained, hence iterating over them will not be with constant time anymore but may go upto O(n). So to spread the Nodes more evenly, resize the hashmap once the total number of nodes in it exceeds some threshold value.
So to resize:
new Hashmap with new capacity (= double the previous capacity) is created, the table now points to it, and the new threshold is created.Finally, the old elements are transferred to this new Hashmap as:
We iterate over every table index, at every index we iterate over all the elements of the LinkedList there.At every array index, the element found let be ?e?.
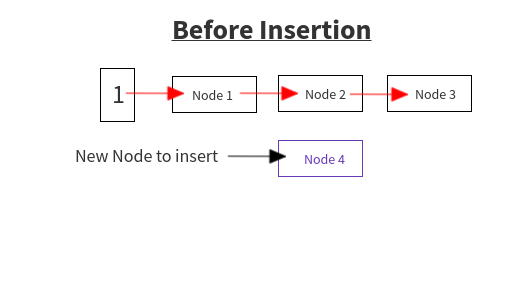
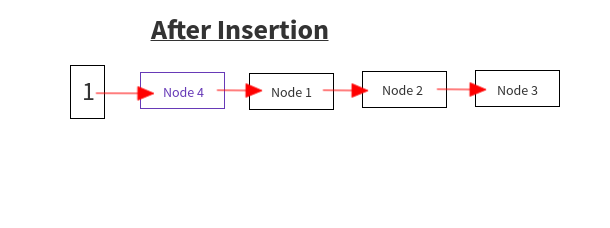
Now, let us suppose at index ?i? we have the state before insertion as shown.While iterating over the old HashMap, we get the node(node 4). calculate the index to insert it in the new HashMap. Let the index be ?i?So insert it as the code above:Let e i.e. the Node to be inserted i.e. Node 4e.next = null (Node4 does not point to any Node)Calculate the new index to insert it, i.e. i(as mentioned above)e.next = newtable[i] i.e. Node4 -> Node1 as newTable[i] has Node 1newTable[i] = ei.e. new table now points to newly inserted Node i.e. Node4 instead of Node1 now.newtable[i] = Node1 -> Node2 -> Node 3is changed to newtable[i] = Node 4 -> Node1 -> Node2 -> Node 3
Hence the Node is inserted into the new table.Likewise, all the nodes are inserted into the new Hashmap.
Finally, after the Hashmap has resized i.e. all the old data has been copied to new Hashmap with increased size (in case the size exceeded the threshold only when the resizing will be done), the new Node can be inserted.
Till now only the old data is added to new hashmap with increased size.
createEntry() Phase:
In this method, the entry is finally added to a hashmap.So new Node with calculated hash, the index is inserted in the similar way as shown above.Let the index to insert it be i.Let at index i the state istable[i] -> Node1 -> Node2Now to insert Node3 into it,After insertion the table[i] will be:table[i] -> Node 3 -> Node1 -> Node2 So new node is inserted at the top of all nodes at the index.
e here points to the Node1 in our example, i.e. Node at table[index] before insertion.now table[index] points to new HashMapEntry<>(hash, key, value, e); Means to Node3 now is created and table[index] pointing to it.Not Node3 must also point to Node1 else the Node1 LinkedList will be lost.It is done by pointing the Node1 as the next while the Node 3 is created.
Where the Signature of HashMapEntry<>(hash, key, value, e) is :
Hence the Value is inserted.
So the complete put() method is:
GET Operation:
Get finds the value of the Node after matching the hashcode and equals.if no such node is found then null is returned.It checks if the key provided as input is null or not.
Case 1: Key(of the Node to search for) is nullIn case the key is null, it iterates over the table[0] i.e. 0th index to find any null key there. If found it returns the value of the key or returns null if the null key is not there.
Case 2: Key(of the Node to search for) is not nullIn case the key is not null, it calculates the hashcode and then the index to search it on.It then iterates over the table[index], checking against the hashcode and equals and returning the value if key matches, else returning null.
So the complete get() method is:


{kind=link}
{kind=link}