
Spark ? 2.3.2, Hadoop ? 2.7, Python 3.6, Windows 10
When you need to scale up your machine learning abilities, you will need a distributed computation. PySpark interface to Spark is a good option. Here is a simple guide, on installation of Apache Spark with PySpark, alongside your anaconda, on your windows machine.
 Spark ? Lightning-fast unified analytics engine
Spark ? Lightning-fast unified analytics engine
Apache Spark and PySpark
Apache Spark is an analytics engine and parallel computation framework with Scala, Python and R interfaces. Spark can load data directly from disk, memory and other data storage technologies such as Amazon S3, Hadoop Distributed File System (HDFS), HBase, Cassandra and others.
PySpark Installation and setup
If you find the right guide, it can be a quick and painless installation. But since its fast evolving infrastructure, methods and versions are dynamic, and a lot of outdated and confusing materials out there.
Most issues caused from improperly set environment variables, so be accurate about it and recheck. Another set of problems come from winutils.exe file,which an hadoop component for Windows OS. It is used for running shell commands, and accessing local files. I stole a trick from this article, that solved issues with file.
1. Install Java 8
Before you can start with spark and hadoop, you need to make sure you have java 8 installed, or to install it.
Check if JAVA is installed
Open cmd (windows command prompt) , or anaconda prompt, from start menu and run:
java -version
You Should get something like:
java version “1.8.0_144″Java(TM) SE Runtime Environment (build 1.8.0_144-b01)Java HotSpot(TM) Client VM (build 25.144-b01, mixed mode, sharing)
Check the setup for environment variables: JAVA_HOME and PATH, as described below.
Install JAVA 8
Go to Java?s official download website, accept Oracle license and download Java JDK 8, suitable to your system.
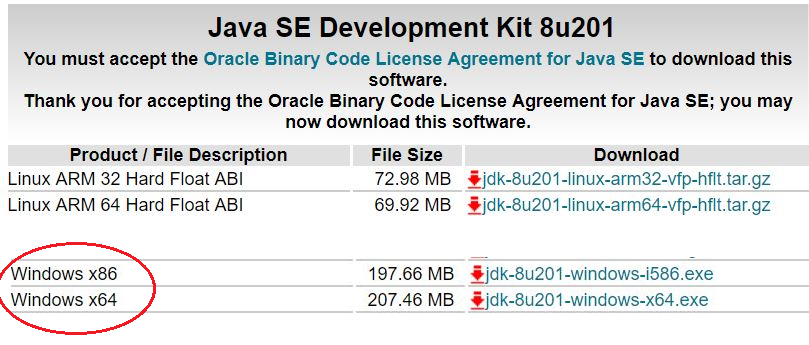 Java download page
Java download page
Run the executable, and JAVA by default will be installed in:
C:Program FilesJavajdk1.8.0_201
Add the following environment variable:
JAVA_HOME = C:Program FilesJavajdk1.8.0_201
Add to PATH variable the following directory:
C:Program FilesJavajdk1.8.0_201bin
2. Download and Install Spark
Go to Spark home page, and download the .tgz file from 2.3.2 version,according to time of writing, the payspark in the latest version did not work correctly.
 apache spark download page
apache spark download page
Extract the file to your chosen directory (7z can open tgz). In my case, it was C:spark. There is another compressed directory in the tar, extract it (into here) as well.
Setup the environment variables
SPARK_HOME = C:sparkspark-2.3.2-bin-hadoop2.7HADOOP_HOME = C:sparkspark-2.3.2-bin-hadoop2.7
Add the following path to PATH environment variable:
C:sparkspark-2.3.2-bin-hadoop2.7bin
3. Download and setup winutils.exe
In hadoop binaries repository, https://github.com/steveloughran/winutils choose your hadoop version, then goto bin, and download the winutils.exe file. In my case: https://github.com/steveloughran/winutils/blob/master/hadoop-2.7.1/bin/winutils.exe
Save winutils.exe in to bin directory of your spark installation, SPARK_HOMEbin directory. In my case: C:sparkspark-2.3.2-bin-hadoop2.7bin. Now the trick. It?s not a must, things did not work well for me without it.
- Create the folder C:tmphive
- Execute the following command in cmd started using the option Run as administrator.
winutils.exe chmod -R 777 C:tmphivewinutils.exe ls -F C:tmphive
The output is something of the sort:
drwxrwxrwx|1|LAPTOP-…..
4. Check PySpark installation
In your anaconda prompt,or any python supporting cmd, type pyspark, to enter pyspark shell. To be prepared, best to check it in the python environment from which you run jupyter notebook. You supposed to see the following:
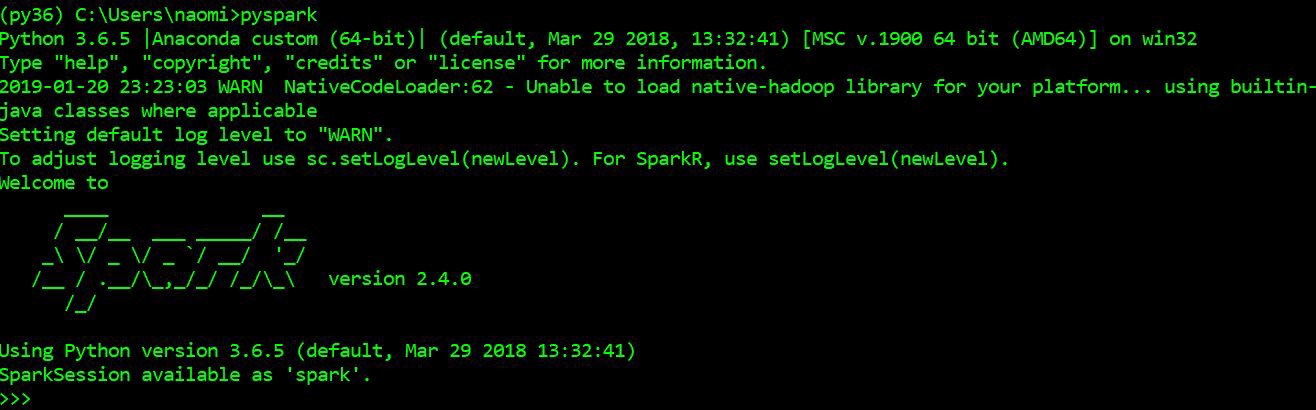 pyspark shell on anaconda prompt
pyspark shell on anaconda prompt
Run the following commands, the output should be [1,4,9,16].
To exit pyspark shell, type Ctrl-z and enter. Or the python command exit()
5. PySpark with Jupyter notebook
Install conda findspark, to access spark instance from jupyter notebook. Check current installation in Anaconda cloud. In time of writing:
conda install -c conda-forge findspark
Open your python jupyter notebook, and write inside:
import findsparkfindspark.init()findspark.find()import pysparkfindspark.find()
Last line will output SPARK_HOME path. It’s just for test, you can delete it.
from pyspark import SparkContext, SparkConffrom pyspark.sql import SparkSessionconf = pyspark.SparkConf().setAppName(‘appName’).setMaster(‘local’)sc = pyspark.SparkContext(conf=conf)spark = SparkSession(sc)
- pyspark.sql.SparkSession Main entry point for DataFrame and SQL functionality.
- Full notebooks on my git.
Run the same test example as in pyspark shell:
nums = sc.parallelize([1,2,3,4])nums.map(lambda x: x*x).collect()
In the end, stop the session
sc.stop()
Installation and setup is done. Next article, let’s start discussing how to run and develop machine learning models.
More about Spark
Scalability
Spark Runs Everywhere. Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud, against diverse data sources.
You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources.
You can deploy Spark on a cluster if you?d like to run it in a distributed mode. You can also run locally on a multicore machine without any setup.
Speed
Unlike Hadoop spark maintains the intermediate results in memory rather than writing every intermediate output to disk. This hugely cuts down the execution time of the operation, resulting in faster execution of task, as more as 100X time a standard MapReduce job. Apache Spark can also hold data onto the disk. When data crosses the threshold of the memory storage it is spilled to the disk. This way spark acts as an extension of MapReduce. Explanation from here.
Recommended reading
- A good spark installation on windows guide. Was very helpful.
- Well written clear explanation on the scaling methods of sklearn models by spark. With a good pandas pyspark example. here
- Good tutorial. Tutorial: Introduction to Apache Spark
Troubleshooting
- Anaconda pyspark. Anaconda has its own pyspark package. In my case, the apache pyspark and the anaconda, did not coexists well, so I had to uninstall anaconda pyspark.
- Code will not work if you have more than one spark, or spark-shell instance open.
- Print environment variables inside jupyter notebook.
import osprint(os.environ[‘SPARK_HOME’])print(os.environ[‘JAVA_HOME’])print(os.environ[‘PATH’])
- If you need more explanation on how to manage system variables, command prompt, etc. It’s all here: basic-window-tools-for-installations
- set command in cmd, print out all environment variables and their values, so check that your changes took place.
- As always, re-open cmd, and even reboot, can solve problems.


{kind=link}
{kind=link}