As human, our brains are always tuned to spotting something out of the ?normal? or the ?usual stuff.? In short, some anomaly that does not fit with the usual pattern. With the abundant growth of data, data science tools are also looking for anomalies that do not subscribe to the normal data flow. For example, an ?unusually high? number of login attempts may point to a potential cyberattack, or a major hike in credit card transactions in a short period could potentially be a credit card fraud.
Machine Learning in Finance | Data Driven Investor
Before we cover some Machine Learning finance applications, let’s first understand what Machine Learning is. Machine?
www.datadriveninvestor.com
At the same time, detecting anomalies in the face of a continuous stream of unstructured data from various sources has its own challenges. An example of a challenge is to assume that a majority of credit card transactions are legitimate and proper while looking for major deviations in a few transactions that fall outside the ?normal? range.
Thanks to the growth of various deep learning technologies, anomaly detection using machine learning (or ML) is a practical solution today. Machine learning algorithms can be deployed to define data patterns that are normal and using ML models to find deviations or anomalies.
So, as a data analyst, how can you implement anomaly detection using machine learning? And what are the methods and benefits of anomaly detection using deep learning technologies? Let?s answer each of these questions and more in the following sections.
What is Anomaly Detection?
Also referred to as outlier detection, anomaly detection is simply the mode of detecting and identifying anomalous data in any data-based event or observation that differs majorly from the rest of the data. Anomalous data can be critical in detecting a rare data pattern or potential problem in the form of financial frauds, medical conditions, or even malfunctioning equipment.
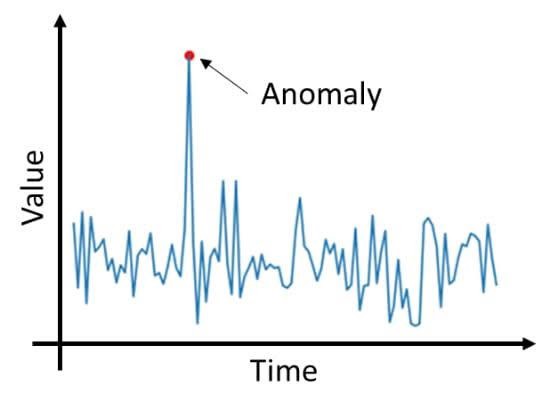
How do you go about detecting an anomaly in data? Let?s examine this with the aid of an anomaly detection use case using 2 variables (X & Y). Consider the following visualized data that plots the X and Y variables.

Consider the data patterns of the 2 variables based on the plotted graphs to the right. Based on these data points, it?s not possible to detect any anomaly (or outlier). However, when the 2 variables are plotted against each other (as shown in the left figure), we can clearly detect the anomaly.
Does this bring us to the question as to why machine learning is required in anomaly detection? Detecting anomalies can be very challenging if you are plotting not two but hundreds of such variables in real-life scenarios.
How does machine learning help in outlier analysis? Let?s discuss this in the next section.
Machine Learning and Outlier Analysis
An outlier is identified as any data object or point that significantly deviates from the remaining data points. In data mining, outliers are commonly discarded as an exception or simply noise. However, the same cannot be done in anomaly detection, hence the emphasis on outlier analysis.

An example of performing anomaly detection using machine learning is the K-means clustering method. This method is used to detect the outlier based on their plotted distance from the closest cluster.
K-means clustering method involves the formation of multiple clusters of data points each with a mean value. Objects within a cluster have the closest mean value. Any object with a threshold value greater than the nearest cluster mean value is identified as an outlier. Here is the step-by-step method used in K-means clustering:
- Calculate the mean value of each cluster.
- Set an initial threshold value.
- During the testing process, determine the distance of each data point from the mean value.
- Identify the cluster that is nearest to the test data point.
- If the ?Distance? value is more than the ?threshold? value, then mark it as an outlier.
Next, let?s look at some of the other methods of executing anomaly detection using machine learning.
Anomaly Detection Methods
Based on different machine learning algorithms, anomaly detection methods are primarily classified under the following two headings
Supervised methods.
As the name suggests, this anomaly detection method requires the existence of a labeled dataset that contains both normal and anomalous data points. Examples of supervised methods include anomaly detection using neural networks, Bayesian networks, and the K-nearest neighbors (or k-NN) method.
Supervised methods provide a better rate of anomaly detection thanks to their ability to encode any interdependency between variables and including previous data in any predictive model.
Unsupervised methods
Unsupervised methods of anomaly detection do not depend on any training data with manual labeling. These methods are based on the statistical assumption that most of the inflowing data are normal and only a minor percentage would be anomalous data. These methods also estimate that any malicious data would be different statistically from normal data. Some of the unsupervised methods include the K-means method, autoencoders, and hypothesis-based analysis.
In the next sections, we shall look at some of the business benefits of anomaly detection using machine learning.
Anomaly Detection ? Business Benefits
Using the capability of machine learning, anomaly detection has practical applications and benefits in different areas of business operations. Some of the benefits of the anomaly detection medium include:
Intrusion detection
Any nefarious activity that can damage an information system can be broadly classified as an intrusion. Anomaly detection can be effective in both detecting and solving intrusions of any kind. Common data-centric intrusions include cyberattacks, data breaches, or even data defects.
Mobile sensor data
Another benefit of anomaly detection using machine learning is in the domain of gathering and analyzing mobile sensor data. The growing adoption of IoT devices and the reduced costs of data capture through mobile sensors is definitely driving this trend.
For instance, a particular industry case study is that of the IBM Data Science Experience that developed a tool for anomaly detection using Jupyter Notebook for capturing sensor data from mobile phones and connected IoT devices.
Network server or app failure
Be it a mobile app or a network failure, a sudden degradation in performance can affect any business. Want to detect a sudden rise in the number of failed server requests? Anomaly detection code in Python programming can be used to detect any failing server on your network.
Additionally, anomaly detection can provide you with any supportive data that can identify the root cause of the problem.
Statistical Process Control
Statistical Process Control (or SPC) is a quality standard that is common in the manufacturing process. Quality-related data on product or process measure is retrieved during the manufacturing run-time process and is plotted on a graph to monitor if the data is within the configured control limits.
Anomaly detection is deployed to check if any data falls outside the control limits and to determine the root cause. In short, anomaly detection in SPC can be used to detect any product variation or any issue occurring in the manufacturing process that needs to be immediately resolved.
Conclusion
Future advancement in machine learning and deep learning technologies will only add to the scope of anomaly detection techniques and its value to business data. The increasing volume and complexity of data translate to major opportunities in harnessing this information for business success.
Since its inception, Countants has mastered deep learning solutions in artificial intelligence and machine learning for its global customers. If you have invested in machine learning tools like Python or Jupyter Notebook, then we can help you build business leverage from anomaly detection methods. Visit us at our website or call us now with your data-related queries.


{kind=link}
{kind=link}