
 source: https://www.americanforests.org/blog/may-the-forest-be-with-you-and-why-it-matters/
source: https://www.americanforests.org/blog/may-the-forest-be-with-you-and-why-it-matters/
As a complete beginner to the world of Machine Learning, I was amazed and somewhat mystified by its endless possibilities. It took me a few frustrating weekends and immense blessings of caffeine gods to finally help me get the hang of things. So, I thought of making life a little bit easier for fellow geeks and share a bit of what I have learned. In this article, I will be focusing on the Random Forest Regression model(if you want a practical guide to get started with machine learning refer to this article). First off, I will explain in simple terms for all the newbies out there, how Random Forests work and then move on to a simple implementation of a Random Forest Regression model using Scikit-learn to get you started.
A Random Forest is an ensemble technique capable of performing both regression and classification tasks with the use of multiple decision trees and a technique called Bootstrap Aggregation, commonly known as bagging. What is bagging you may ask? Bagging, in the Random Forest method, involves training each decision tree on a different data sample where sampling is done with replacement.
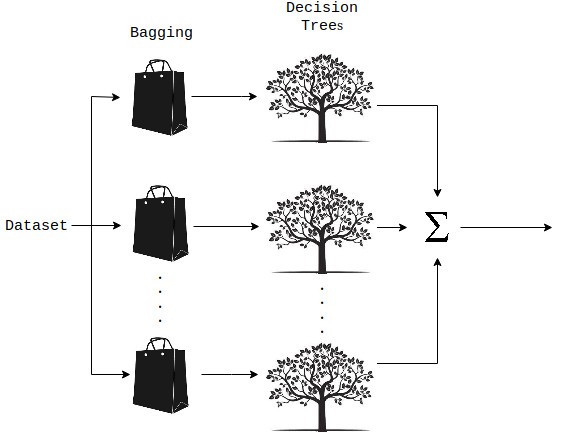 Random Forest Regression: Process
Random Forest Regression: Process
The basic idea behind this is to combine multiple decision trees in determining the final output rather than relying on individual decision trees. If you want to read more on Random Forests, I have included some reference links which provide in depth explanations on this topic.
Let?s get choppin?!
Now I will show you how to implement a Random Forest Regression Model using Python. To get started, we need to import a few libraries.
from sklearn.model_selection import cross_val_score, GridSearchCVfrom sklearn.ensemble import RandomForestRegressorfrom sklearn.preprocessing import MinMaxScaler
The star here is the scikit-learn library. It is a machine learning library which features various classification, regression and clustering algorithms, and is the saving grace of machine learning enthusiasts.
Let?s skip straight into the forest. Here?s how everything goes down,
def rfr_model(X, y):# Perform Grid-Search gsc = GridSearchCV( estimator=RandomForestRegressor(), param_grid={ ‘max_depth’: range(3,7), ‘n_estimators’: (10, 50, 100, 1000), }, cv=5, scoring=’neg_mean_squared_error’, verbose=0, n_jobs=-1) grid_result = gsc.fit(X, y) best_params = grid_result.best_params_ rfr = RandomForestRegressor(max_depth=best_params[“max_depth”], n_estimators=best_params[“n_estimators”], random_state=False, verbose=False)# Perform K-Fold CV scores = cross_val_score(rfr, X, y, cv=10, scoring=’neg_mean_absolute_error’) return scores
First we pass the features(X) and the dependent(y) variable values of the data set, to the method created for the random forest regression model. We then use the grid search cross validation method (refer to this article for more information) from the sklearn library to determine the optimal values to be used for the hyperparameters of our model from a specified range of values. Here, we have chosen the two hyperparameters; max_depth and n_estimators, to be optimized. According to sklearn documentation, max_depth refers to the maximum depth of the tree and n_estimators, the number of trees in the forest. Ideally, you can expect a better performance from your model when there are more trees. However, you must be cautious of the value ranges you specify and experiment using different values to see how your model performs.
After creating a random forest regressor object, we pass it to the cross_val_score() function which performs K-Fold cross validation (refer to this article for more information on K-Fold cross validation) on the given data and provides as an output, an error metric value, which can be used to determine the model performance.
scores = cross_val_score(rfr, X, y, cv=10, scoring=’neg_mean_absolute_error’)
Here we have used 10-fold cross validation(specified by the cv parameter) where the negative Mean Absolute Error(MAE) is taken as the error metric(specified using the scoring parameter) to measure model performance. The lower the MAE is, the better. You can also use the cross_val_predict() function to get the list of values predicted using the model.
predictions = cross_val_predict(rfr, X, y, cv=10)
This brings us to the end of this article. Hope you got a basic understanding of random forest regression by following this post. May the tree nymphs shower you with leaves! Adios!
More articles related to Machine Learning:
- A practical guide to getting started with Machine Learning
- Part I ? Support Vector Machines: An Overview
- Part II ? Support Vector Machines: Regression
Reading Material:

{kind=link}
{kind=link}