
 Get the dolphin up to speed ? Photo by JIMMY ZHANG on Unsplash
Get the dolphin up to speed ? Photo by JIMMY ZHANG on Unsplash
When you need to bulk-insert many million records in a MySQL database, you soon realize that sending INSERT statements one by one is not a viable solution.
The MySQL documentation has some INSERT optimization tips that are worth reading to start with.
I will try to summarize here the two main techniques to efficiently load data into a MySQL database.
LOAD DATA INFILE
If you?re looking for raw performance, this is indubitably your solution of choice. LOAD DATA INFILE is a highly optimized, MySQL-specific statement that directly inserts data into a table from a CSV / TSV file.
There are two ways to use LOAD DATA INFILE. You can copy the data file to the server’s data directory (typically /var/lib/mysql-files/) and run:
LOAD DATA INFILE ‘/path/to/products.csv’ INTO TABLE products;
This is quite cumbersome as it requires you to have access to the server?s filesystem, set the proper permissions, etc.
The good news is, you can also store the data file on the client side, and use the LOCAL keyword:
LOAD DATA LOCAL INFILE ‘/path/to/products.csv’ INTO TABLE products;
In this case, the file is read from the client?s filesystem, transparently copied to the server?s temp directory, and imported from there. All in all, it?s almost as fast as loading from the server?s filesystem directly. You do need to ensure that this option is enabled on your server, though.
There are many options to LOAD DATA INFILE, mostly related to how your data file is structured (field delimiter, enclosure, etc.). Have a look at the documentation to see them all.
While LOAD DATA INFILE is your best option performance-wise, it requires you to have your data ready as delimiter-separated text files. If you don?t have such files, you?ll need to spend additional resources to create them, and will likely add a level of complexity to your application. Fortunately, there?s an alternative.
Extended inserts
A typical SQL INSERT statement looks like:
INSERT INTO user (id, name) VALUES (1, ‘Ben’);
An extended INSERT groups several records into a single query:
INSERT INTO user (id, name) VALUES (1, ‘Ben’), (2, ‘Bob’);
The key here is to find the optimal number of inserts per query to send. There is no one-size-fits-all number, so you need to benchmark a sample of your data to find out the value that yields the maximum performance, or the best tradeoff in terms of memory usage / performance.
To get the most out of extended inserts, it is also advised to:
- use prepared statements
- run the statements in a transaction
The benchmark
I?m inserting 1.2 million rows, 6 columns of mixed types, ~26 bytes per row on average. I tested two common configurations:
- Client and server on the same machine, communicating through a UNIX socket
- Client and server on separate machines, on a very low latency (< 0.1 ms) Gigabit network
As a basis for comparison, I copied the table using INSERT ? SELECT, yielding a performance of 313,000 inserts / second.
LOAD DATA INFILE
To my surprise, LOAD DATA INFILE proves faster than a table copy:
- LOAD DATA INFILE: 377,000 inserts / second
- LOAD DATA LOCAL INFILE over the network: 322,000 inserts / second
The difference between the two numbers seems to be directly related to the time it takes to transfer the data from the client to the server: the data file is 53 MiB in size, and the timing difference between the 2 benchmarks is 543 ms, which would represent a transfer speed of 780 mbps, close to the Gigabit speed.
This means that, in all likelihood, the MySQL server does not start processing the file until it is fully transferred: your insert speed is therefore directly related to the bandwidth between the client and the server, which is important to take into account if they are not located on the same machine.
Extended inserts
I measured the insert speed using BulkInserter, a PHP class part of an open-source library that I wrote, with up to 10,000 inserts per query:
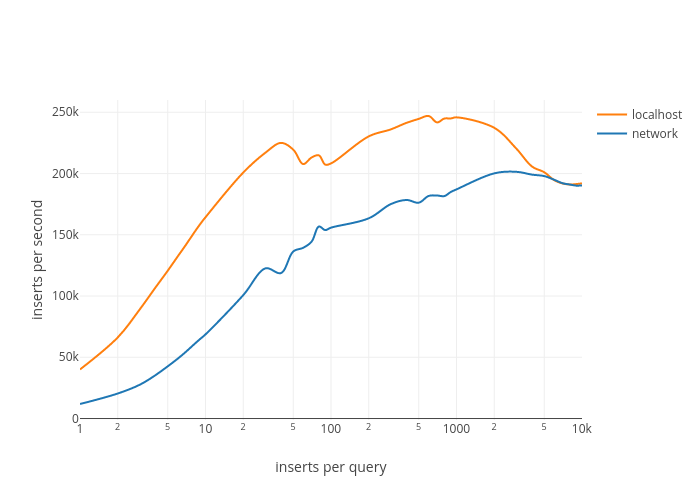
As we can see, the insert speed raises quickly as the number of inserts per query increases. We got a 6 increase in performance on localhost and a 17 increase over the network, compared to the sequential INSERT speed:
- 40,000 ? 247,000 inserts / second on localhost
- 12,000 ? 201,000 inserts / second over the network
It takes around 1,000 inserts per query to reach the maximum throughput in both cases, but 40 inserts per query are enough to achieve 90% of this throughput on localhost, which could be a good tradeoff here. It?s also important to note that after a peak, the performance actually decreases as you throw in more inserts per query.
The benefit of extended inserts is higher over the network, because sequential insert speed becomes a function of your latency:
max sequential inserts per second ~= 1000 / ping in milliseconds
The higher the latency between the client and the server, the more you?ll benefit from using extended inserts.
Conclusion
As expected, LOAD DATA INFILE is the preferred solution when looking for raw performance on a single connection. It requires you to prepare a properly formatted file, so if you have to generate this file first, and/or transfer it to the database server, be sure to take that into account when measuring insert speed.
Extended inserts on the other hand, do not require a temporary text file, and can give you around 65% of the LOAD DATA INFILE throughput, which is a very reasonable insert speed. It?s interesting to note that it doesn?t matter whether you?re on localhost or over the network, grouping several inserts in a single query always yields better performance.
If you decide to go with extended inserts, be sure to test your environment with a sample of your real-life data and a few different inserts-per-query configurations before deciding upon which value works best for you.
Be careful when increasing the number of inserts per query, as it may require you to:
- allocate more memory on the client side
- increase the max_allowed_packet setting on the MySQL server
As a final note, it?s worth mentioning that according to Percona, you can achieve even better performance using concurrent connections, partitioning, and multiple buffer pools. See this post on their blog for more information.
The benchmarks have been run on a bare metal server running Centos 7 and MySQL 5.7, Xeon E3 @ 3.8 GHz, 32 GB RAM and NVMe SSD drives. The MySQL benchmark table uses the InnoDB storage engine.
The benchmark source code can be found in this gist. The benchmark result graph is available on plot.ly.


{kind=link}
{kind=link}