PHP has one data structure to rule them all. The array is a complex, flexible, master-of-none, hybrid data structure, combining the behaviour of a list and a linked map. But we use it for everything, because PHP is pragmatic: ?dealing with things sensibly and realistically in a way that is based on practical rather than theoretical considerations?. An array gets the job done. Unfortunately, with flexibility comes complexity.
The recent release of PHP 7 caused a lot of excitement in the PHP community. We couldn’t wait to start using the new features and try out the reported ~2x performance boost. One of the reasons why it runs that much faster is because the array was redesigned. But it?s still the same structure, ?optimised for everything; optimised for nothing? with room for improvement.
?What about the SPL data structures??
Unfortunately they are terrible. They did offer some benefits prior to PHP 7, but have since been neglected to the point of having no practical value.
?Why can?t we just fix and improve them??
We could, but I believe their design and implementation is so poor that it would be better to replace them with something brand new.
?SPL data structures are horribly designed.? ? Anthony Ferrara
Introducing ds, an extension for PHP 7 providing specialized data structures as an alternative to the array.
This post briefly covers the behaviour and performance benefits of each structure. There is also a list of answers to expected questions at the end.
Github: https://github.com/php-ds
Namespace: Ds
Interfaces: Collection, Sequence, Hashable
Classes: Vector, Deque, Map, Set, Stack, Queue, PriorityQueue, Pair
Collection
Collection is the base interface which covers common functionality like foreach, echo, count, print_r, var_dump, serialize, json_encode, and clone.
Sequence
Sequence describes the behaviour of values arranged in a single, linear dimension. Some languages refer to this as a List. It?s similar to an array that uses incremental integer keys, with the exception of a few characteristics:
- Values will always be indexed as [0, 1, 2, ?, size – 1].
- Removing or inserting updates the position of all successive values.
- Only allowed to access values by index in the range [0, size – 1].
Vector
A Vector is a Sequence of values in a contiguous buffer that grows and shrinks automatically. It?s the most efficient sequential structure because a value?s index is a direct mapping to its index in the buffer, and the growth factor isn’t bound to a specific multiple or exponent.
Strengths
- Very low memory usage
- get, set, push and pop are O(1)
Weaknesses
- insert, remove, shift, and unshift are O(n)
The number one data structure used in Photoshop was Vectors.? ? Sean Parent, CppCon 2015
Deque
A Deque (pronounced ?deck?) is a Sequence of values in a contiguous buffer that grows and shrinks automatically. The name is a common abbreviation of ?double-ended queue? and is used internally by DsQueue.
Two pointers are used to keep track of a head and a tail. The pointers can ?wrap around? the end of the buffer, which avoids the need to move other values around to make room. This makes shift and unshift very fast ? something a Vector can?t compete with.
Accessing a value by index requires a translation between the index and its corresponding position in the buffer: ((head + position) % capacity).
Strengths
- Low memory usage
- get, set, push, pop, shift, and unshift are all O(1)
Weaknesses
- insert, remove are O(n)
- Buffer capacity must be a power of 2.
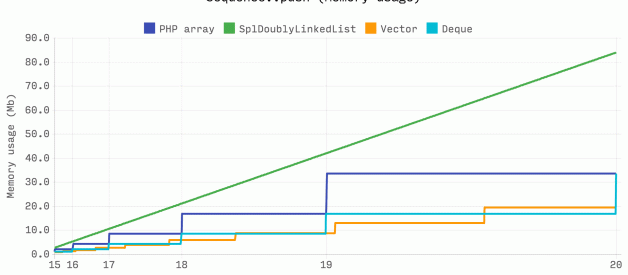
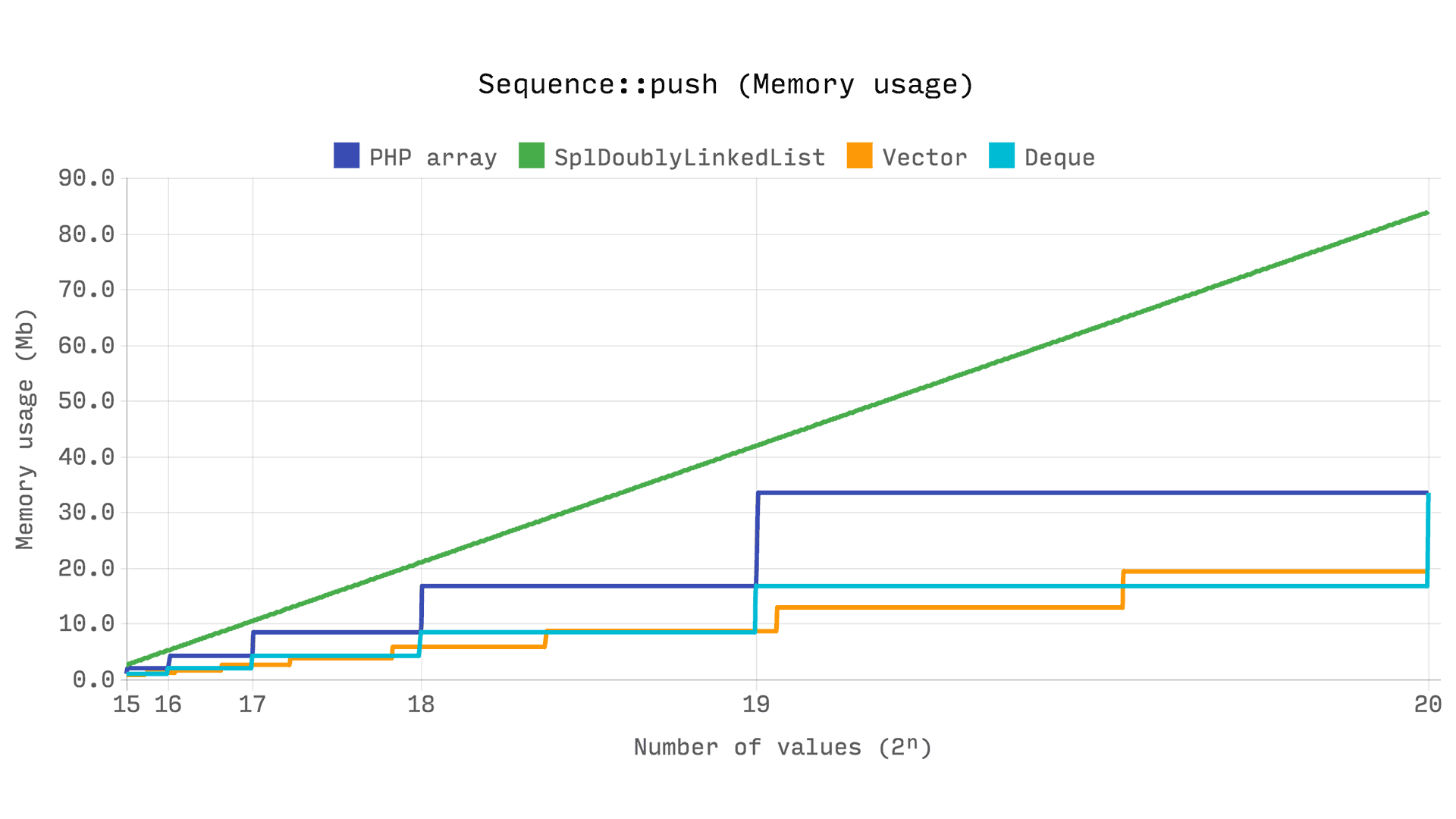
The following benchmark shows the total time taken and memory used to push 2? random integers. PHP array, DsVector and DsDeque are all fast, but SplDoublyLinkedList is consistently more than 2x slower.
SplDoublyLinkedList allocates memory for each value individually, so linear memory growth is expected. Both an array and DsDeque have a 2.0 growth factor to maintain a 2? capacity. DsVector has a growth factor of 1.5, which results in more allocations but lower memory usage overall.
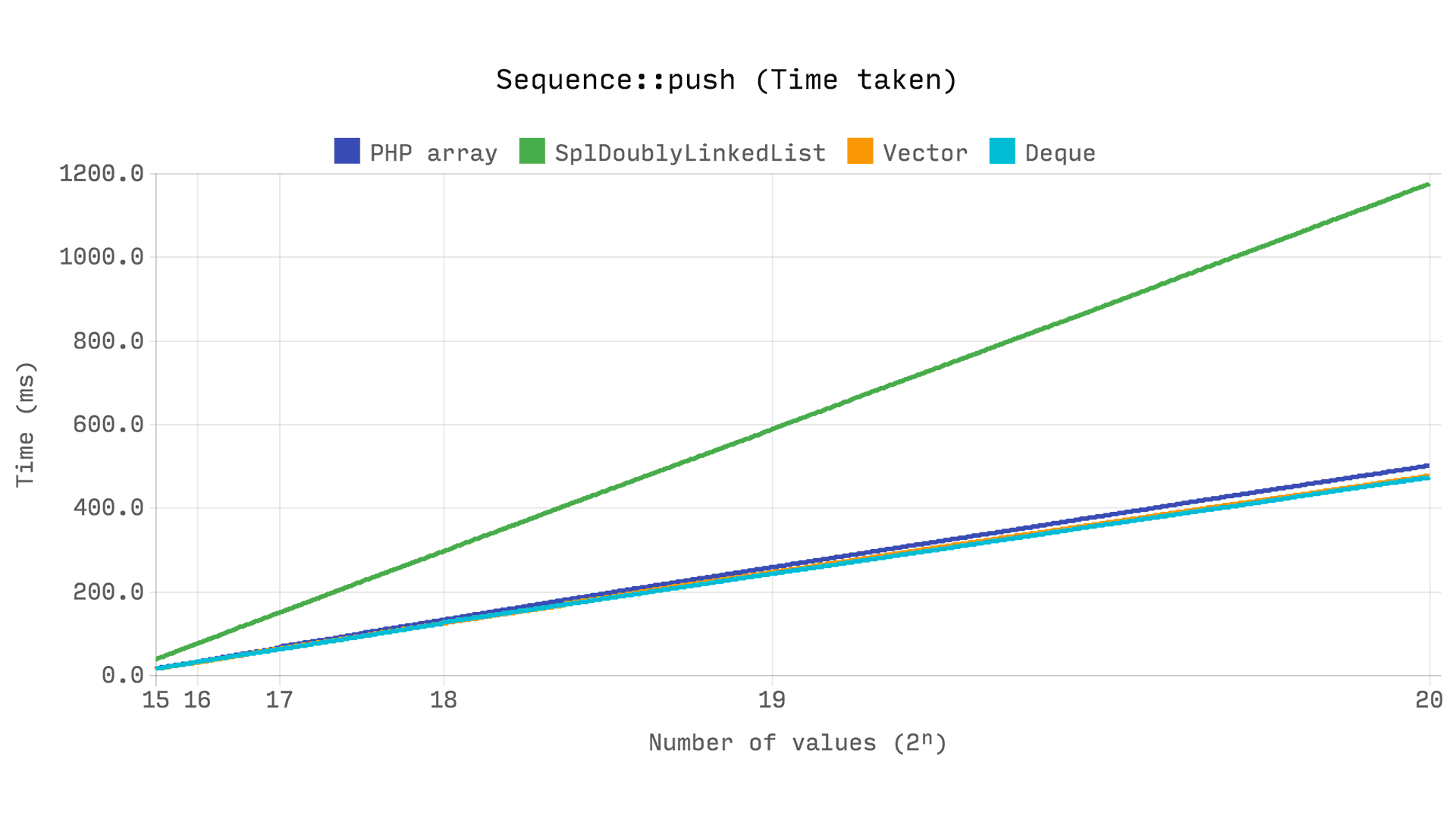
The following benchmark shows the time taken to unshift a single value into a sequence of 2? values. The time it takes to set up the sample is not included in the benchmark.
It shows that array_unshift is O(n). Every time the sample size doubles, so does the time it takes to unshift. This makes sense, because every numerical index in the range [1, size – 1] has to be updated.
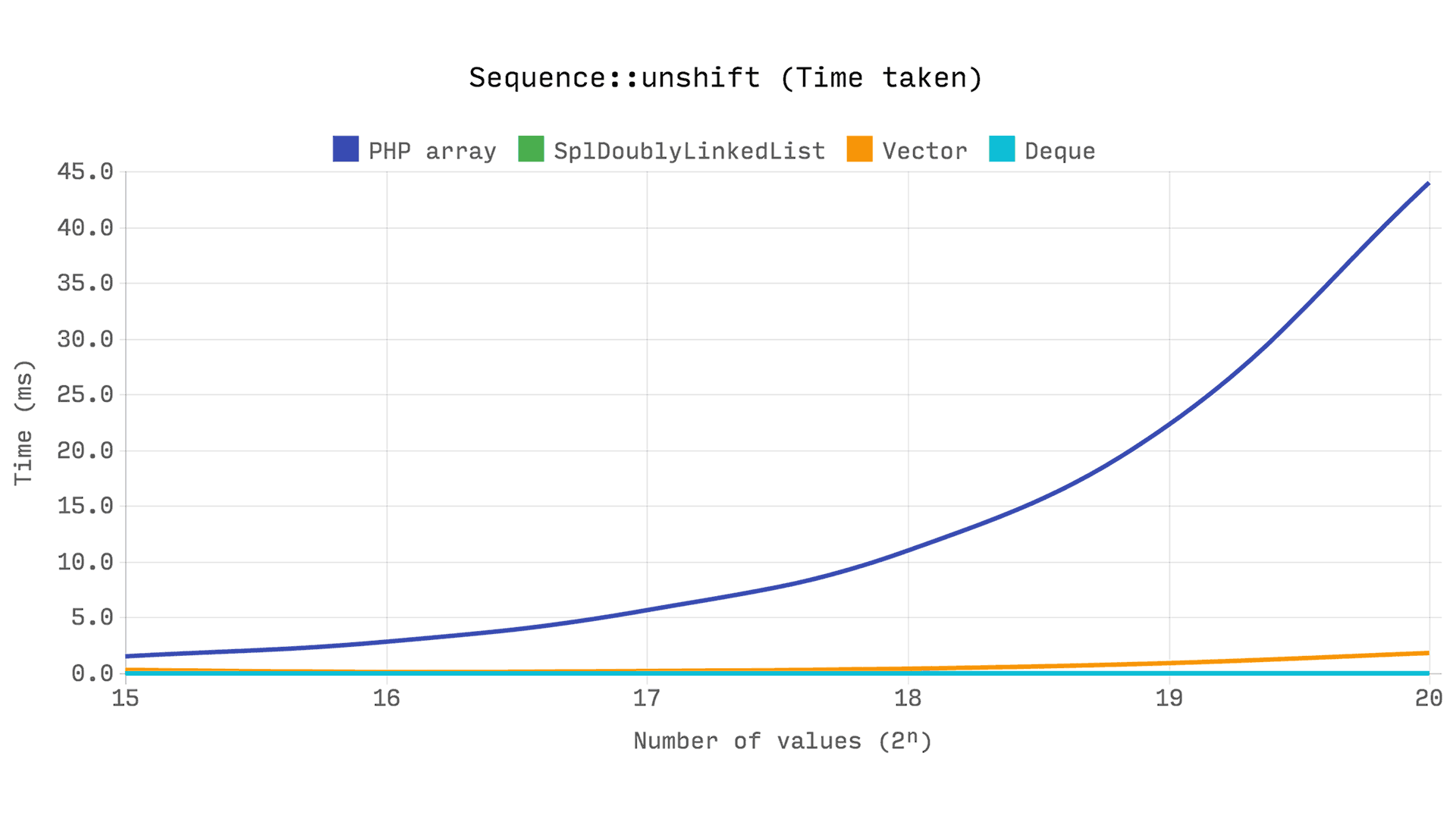
But DsVector::unshift is also O(n), so why is it so much faster? Keep in mind that an array stores each value in a bucket, along with its hash and key. So we have to inspect every bucket and update its hash if the index is numeric. Internally, array_unshift actually allocates a brand new array to do this, and replaces the old one when all the values have been copied over.
The index of a value in a Vector is a direct mapping to its index in the buffer, so all we need to do is move every value in the range [1, size – 1] to the right by one position. Internally, this is done using a single memmove operation.
Both DsDeque and SplDoublyLinkedList are very fast, because the time it takes to unshift a value is not affected by the sample size, ie. O(1)
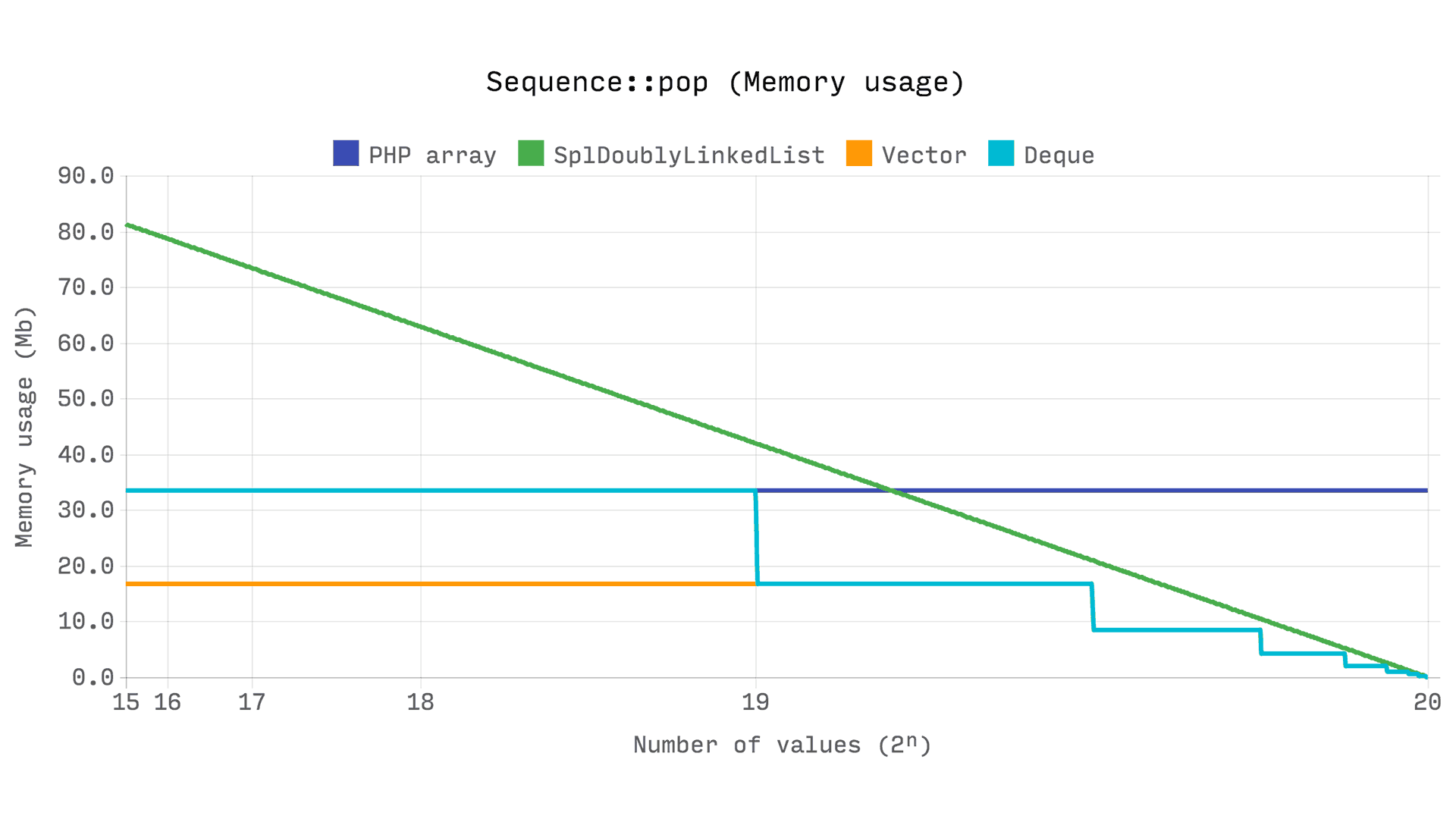
The following benchmark shows how memory usage is affected by 2? pop operations, or from a size of 2? to zero.
What?s interesting here is that an array always holds on to allocated memory, even if its size decreases substantially. DsVector and DsDeque will halve their allocated capacity if their size drops below a quarter of their current capacity. SplDoublyLinkedList will free each individual value?s memory, which is why we can see a linear decline.
Stack
A Stack is a ?last in, first out? or ?LIFO? structure that only allows access to the value at the top of the structure and iterates in that order, destructively.
DsStack uses a DsVector internally.
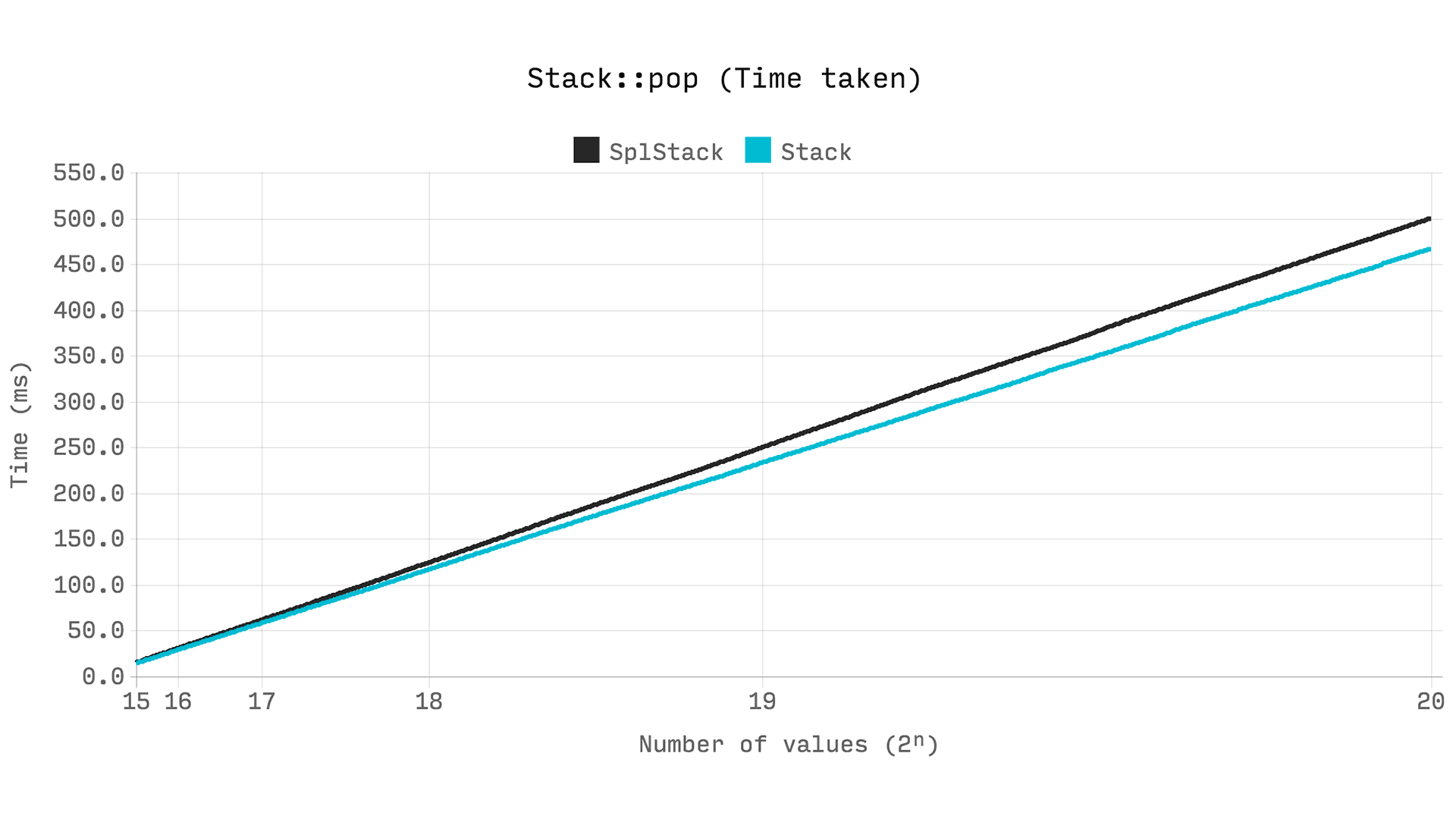
SplStack extends SplDoublyLinkedList, so a performance comparison would be equivalent to comparing DsVector to SplDoublyLinkedList, as seen in the previous benchmarks. The following benchmark shows the time taken to perform 2? pop operations, or from a size of 2? to zero.
Queue
A Queue is a ?first in, first out? or ?FIFO? structure that only allows access to the value at the front of the queue and iterates in that order, destructively.
DsQueue uses a DsDeque internally. SplQueue extends SplDoublyLinkedList, so a performance comparison would be equivalent to comparing DsDeque to SplDoublyLinkedList, as seen in the previous benchmarks.
PriorityQueue
A PriorityQueue is very similar to a Queue. Values are pushed into the queue with an assigned priority, and the value with the highest priority will always be at the front of the queue. Iterating over a PriorityQueue is destructive, equivalent to successive pop operations until the queue is empty.
Implemented using a max heap.
First in, first out ordering is preserved for values with the same priority, so multiple values with the same priority will behave exactly like a Queue. On the other hand, SplPriorityQueue will remove values in arbitrary order.
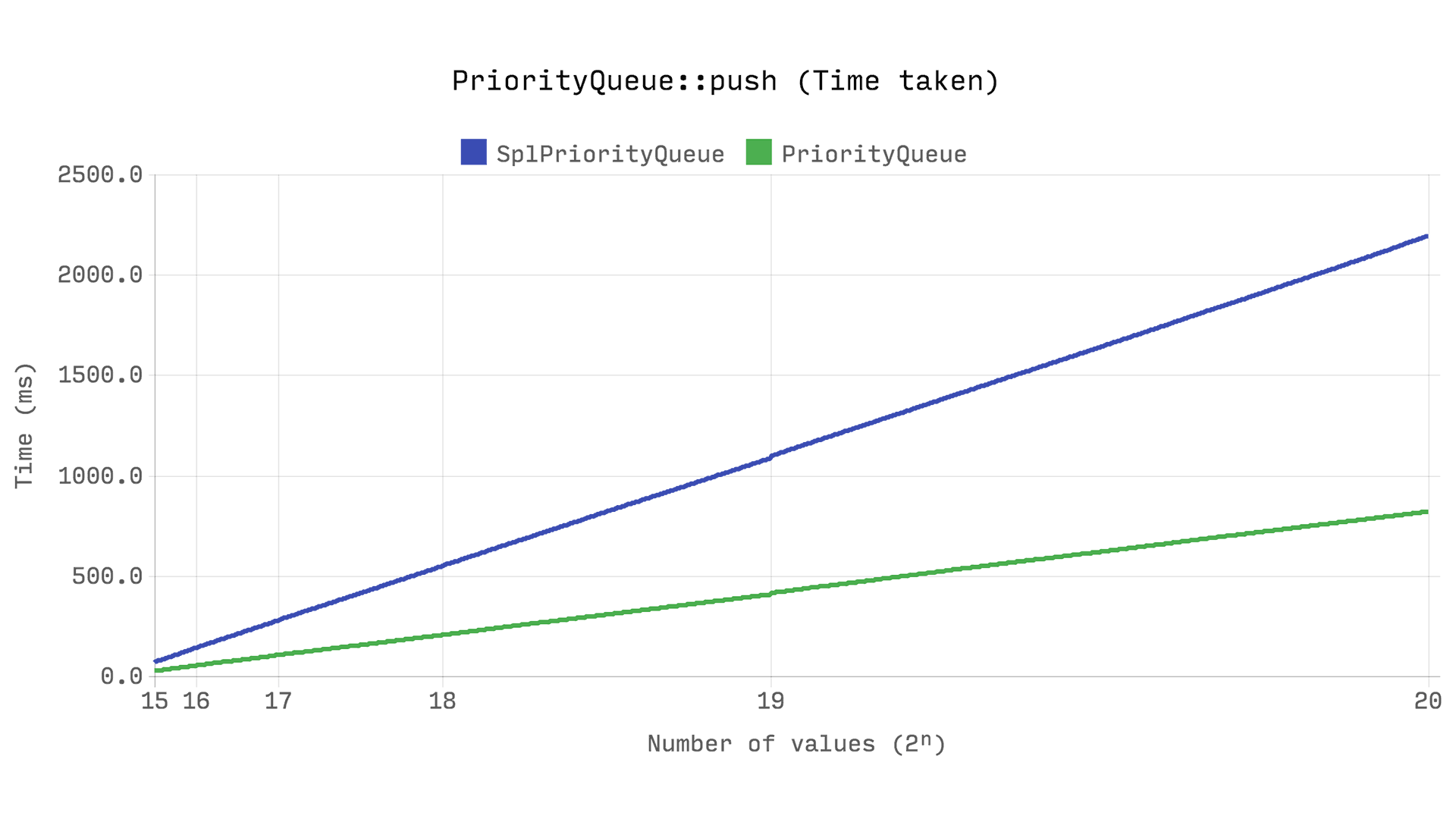
The following benchmark shows the time taken and memory used to push 2? random integers with a random priority into the queue. The same random numbers are used for each benchmark, and the Queue benchmark also generates a random priority even though it doesn’t use it for anything.
This is probably the most significant of all the benchmarks? DsPriorityQueue is more than twice as fast as an SplPriorityQueue, and uses only 5% of its memory. That?s 20 times more memory efficient.
But how? How can the difference be that much when SplPriorityQueue also uses a similar internal structure? It all comes down to how a value is paired with a priority. SplPriorityQueue allows any type of value to be used as a priority, which means that each priority pair takes up 32 bytes.
DsPriorityQueue only supports integer priorities, so each pair only allocates 24 bytes. But that?s not nearly a big enough difference to explain the result.
If you take a look at the source for SplPriorityQueue::insert, you will notice that it actually allocates an array to store the pair.
Because an array has a minimum capacity of 8, each pair actually allocates zval + HashTable + 8 * (Bucket + hash) + 2 * zend_string + (8 + 16) byte string payloads = 16 + 56 + 36 * 8 + 2 * 24 + 8 + 16 = 432 bytes (64 bit).
?So? why an array??
SplPriorityQueue uses the same internal structure as SplMaxHeap, which requires that a value must be a zval. An obvious (but inefficient) way to create a zval pair that is also a zval itself is to use an array.

Hashable
An interface which allows objects to be used as keys. It?s an alternative to spl_object_hash, which determines an object?s hash based on its handle: this means that two objects that are considered equal by an implicit definition would not be treated as equal because they are not the same instance.
Hashable introduces only two methods: hash and equals. Many other languages support this natively, like Java?s hashCode and equals, or Python?s __hash__ and __eq__. There have been a few RFC?s to add this to PHP but none of them have been accepted.
All structures that honour this interface will fall back to spl_object_hash if an object key does not implement Hashable.
Data structures that honour the Hashable interface are Map and Set.
Map
A Map is a sequential collection of key-value pairs, almost identical to an array when used in a similar context. Keys can be any type, but must be unique. Values are replaced if added to the map using the same key.
Like an array, insertion order is preserved.
Strengths
- Performance and memory efficiency is almost identical to an array.
- Automatically frees allocated memory when its size drops low enough.
- Keys and values can be any type, including objects.
- put, get, remove, and hasKey are O(1)
Weaknesses
- Can?t be converted to an array when objects are used as keys.
The following benchmarks show that the performance and memory efficiency is very similar between an array and a DsMap. However, an array will always hold on to allocated memory, where a DsMap will free allocated memory when its size drops below a quarter of its capacity.


Set
A Set is a collection of unique values. The textbook definition of a set will say that values are unordered unless an implementation specifies otherwise. Using Java as an example, java.util.Set is an interface with two primary implementations: HashSet and TreeSet. HashSet provides O(1) add and remove, where TreeSet ensures a sorted set but O(log n) add and remove.
Set uses the same internal structure as a Map, which is based on the same structure as an array. This means that a Set can be sorted in O(n * log(n)) time whenever it needs to be, just like a Map and an array.
Strengths
- add, remove, and contains are O(1)
- Honours the Hashable interface.
- Supports any type of value (SplObjectStorage only supports objects).
Weaknesses
- Doesn?t support push, pop, insert, shift, or unshift.
- get is O(n) if there are deleted values before the index, O(1) otherwise.
The following benchmark shows the time taken to add 2? new instances of stdClass. It shows that DsSet is slightly faster than SplObjectStorage, and uses about half the memory.


A common way to create an array of unique values is to use array_unique, which creates a new array containing only unique values. An important thing to keep in mind here is that values in an array are not indexed, so in_array is a linear search, O(n). Because array_unique deals with values instead of keys, each membership test is a linear search, resulting in O(n).

Responses to expected questions and opinions
Are there tests?
Right now there are ~2400 tests. It?s possible that some of the tests are redundant but I?d rather indirectly test the same thing twice than not at all.
Documentation? API reference?
Documentation is available on php.net, and the polyfill is also documented for IDE integration. You can include the polyfill in your project even if you?re using the extension, because the extension will be loaded first.
Can we see how the benchmarks were configured? Are there more of them?
You can find a complete list of configurable benchmarks in the dedicated benchmark repository: php-ds/benchmarks.
All featured benchmarks were created using a default build of PHP 7.0.3 on a 2015 Macbook Pro. Results will vary between versions and platforms.
Why are Stack, Queue, Set, and Map not interfaces?
I don?t believe that any of them have an alternative implementation worth including. Introducing 3 interfaces and 7 classes is in my opinion a good balance between pragmatism and specialisation.
When should I use a Deque rather than a Vector?
If you know for sure that you won?t be using shift and unshift, use Vector. You can use Sequence as a typehint to accept either.
Why are all the classes final?
The design of the ds API enforces composition over inheritance.
The SPL structures are a good example of how inheritance can be misused, eg. SplStack extends SplDoublyLinkedList which supports random access by index, shift and unshift ? so it?s not technically a Stack.
The Java Collections Framework also has a few interesting cases where inheritance causes ambiguity. An ArrayDeque has three methods for appending a value: add, addLast, and push. This is not exactly a bad thing, because ArrayDeque implements Deque and Queue, which is why it must implement addLast and push. However, having three methods that do the same thing causes confusion and inconsistency.
The old java.util.Stack extends java.util.Vector, and states that ?a more complete and consistent set of LIFO stack operations is provided by the Deque interface and its implementations?, but the Deque interface includes methods like addFirst and remove(x), which shouldn’t be part of a stack API.
Just because these structures don?t extend each other doesn’t mean that we shouldn’t be allowed to either.
That?s actually a fair point, but I still believe that composition is more appropriate for data structures. They are designed to be self-contained, much like an array. You can?t extend an array, so we design our own APIs around it by using an internal array to store the actual data.
Inheritance would also introduce unnecessary internal complexity.
Why no linked list?
LinkedList was actually the first structure because it seemed like a good place to start. I decided to remove it when I realised it wouldn?t be able to compete with Vector or Deque in any situation. The two primary reasons to support that are allocation overhead and locality of reference.
A linked list has to either allocate or free memory whenever a value is added or removed. A node also has two pointers (in the case of a doubly linked list) to reference another node that comes before, and one that comes after. Both Vector and Deque allocate a buffer of memory in advance, so there?s no need to allocate and free as often. They also don?t need additional pointers to know what value comes before or after another, so there?s less overhead.
Would a linked list have lower peak memory because there?s no buffer?
Only when the collection is very small. The upper bound of a Vector?s memory usage is ((1.5 * (size – 1)) * zval) bytes, with a minimum of 10 * zval. A doubly linked list would use (size * (zval + 8 + 8)) bytes, so would only use less memory than a Vector when its size is less than 6.
Okay? so a linked list uses more memory. But why is it slow?
The nodes of a linked list have bad spatial locality. This means that the physical memory location of a node might be far away from its adjacent nodes. Iterating through a linked list therefore jumps around in memory instead of utilizing the CPU cache. This is where both Vector and Deque have a significant advantage: values are physically right next to each other.
?Discontiguous data structures are the root of all performance evil. Specifically, please say no to linked lists.?
?There is almost nothing more harmful you can do to the performance of an actual modern microprocessor than to use a linked list data structure.?
? Chandler Carruth (CppCon 2014)
PHP is a web development language ? performance is not important.
Performance should not be your top priority. Code should be consistent, maintainable, robust, predictable, safe, and easy to understand. But that?s not to say that performance is ?not important?.
We spend a lot of time trying to reduce the size of our assets, benchmark frameworks, and publish pointless micro-optimisations:
- print vs echo, which one is faster?
- The PHP Ternary Operator: Fast or not?
- The PHP Benchmark: setting the record straight
- Disproving the Single Quotes Performance Myth
The ~2x performance increase that came with PHP 7 had us all desperately eager to try it out. It?s arguably one of the most-mentioned benefits of switching from PHP 5.
Efficient code reduces the load on our servers, reduces the response time of our APIs and web pages, and reduces the runtime of our development tools. Performance is important, but maintainable code should come first.
? Discuss: Twitter, Reddit, StackOverflow
? Explore: github.com/php-ds
? Benchmarks: github.com/php-ds/benchmarks


{kind=link}
{kind=link}