In this blog, we will talk about the Distributed Cache in Hadoop. First, we will take a brief introduction to Hadoop. Then see what is actually this distributed Cache in terms of Hadoop. We will explore the working of the Hadoop Distributed Cache. And take a look at two methods of using distributed cache ? GenericOptionParser and Java API.
 Hadoop Distributed Cache
Hadoop Distributed Cache
What is Hadoop?
Hadoop is a Big Data technology for storing and processing of huge volumes of Data. The basis of Hadoop is the principle of distributed storage and distributed computing. It has a master-slave kind of architecture. Master gets configured on a high-end machine and slaves get configured on commodity hardware.
In Hadoop slaves store the actual business data. Whereas Master store the metadata. By metadata, we mean location details about the real data. Hadoop framework splits big files into a number of blocks. And stored in a distributed fashion on the cluster of slave machines. When the client submits any job to Hadoop it divides into a number of independent tasks. These tasks run in parallel on the group of worker nodes. Worker nodes are the slave machines which does the actual task. The master is responsible for allocating resources to worker nodes. It also assigns slave machines tasks for running.
You must read Hadoop master-slave architecture.
Side Data in Hadoop
Side data is extra read-only data required by the job to process the main dataset. For example, we have two datasets ? weather station data and weather record. We want to reconcile the two. The station file is having Station-id and station-name. And weather file is having station-id, timestamp and temperature fields. Now in the output, we want Station-id, station-name, timestamp, and temperature. So it is apparent that we have to join the data in two files. The implementation of this join depends upon how large the datasets are and how are they partitioned.
Suppose the station file is small so that Hadoop can distribute it to each node in the cluster. The mapper or reducer can use this small file ? ?station? to look up the detail data in ?weather? file. Station ID would be the basis of the join condition. The challenge here is to make this small dataset available in an easy and efficient way. This is where the distributed cache comes into the picture.
What is Hadoop Distributed Cache?
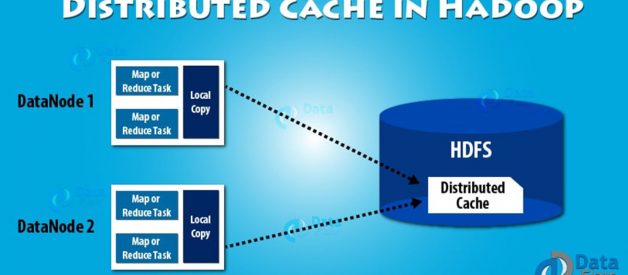
Distributed cache in Hadoop is a way to copy small files or archives to worker nodes in time. Hadoop does this so that these worker nodes can use them when executing a task. To save the network bandwidth the files get copied once per job.
For tools that use GenericOptionsParser we can specify the files to get distributed as comma separated URIs in ?files option. Files can be on HDFS, local Filesystem, or any Hadoop-readable filesystem like S3. If the user does not specify any scheme then Hadoop assumes that the file is on the local filesystem. This is true even when default filesystem is not the local filesystem.
%Hadoop jar <JARFileName> <ClassName> -files <list of files to get distributed via distributed cache> <inputFilePath> <outputFilePath>
One can also copy archive files using ?archives option. Archive file includes JAR files, ZIP files, tar files, and gzipped tar files. These archived files get unarchived at the task nodes. The ?libjars option will add the jar files to the classpath of mapper and reducer tasks. This is useful when you haven?t bundled library jar files in your job jar file.
How Hadoop Distributed Cache Works?
When the user launches a job, Hadoop copies the file specified as arguments in ?files, -archives, -libjars to HDFS. Before running the task, the NodeManager copies these files from HDFS to local disk ? cache. It does this so that the task can now access these files. At this point, the file gets tagged as localized. From the task?s point of view, the files are symbolically linked to the task?s working directory. The files specified under ?libjars option gets copied to task?s classpath before it starts execution.
The NodeManager maintains a count for the number of tasks using these localized files. Before running the task the counter increases by one. And after the task finish execution, the counter gets decremented by one. The file is eligible for deletion only when there are no tasks using it. The file gets deleted when the cache size exceeds a certain limit like 10GB (default). The Hadoop deletes the files to make room for other files getting used at present. The file gets deleted using least recently used algorithm. One can change the cache size setting the property
yarn.nodemanager.localizer.cache.target-size-mb.
Do you know about the Hadoop High Availability Feature?
Hadoop Distributed Cache API
If the GenericsOptionParser is not used then we can use distributed cache API to put the objects in the cache. Following are the methods in the API:-
public void addCacheFile(URI uri)public void addCacheArchive(URI uri)public void setCacheFiles(URI files)public void setCacheArchives(URI archives)public void addFileToClassPath(Path file)public void addArchiveToClassPath(Path archive)
We can distribute two kinds of files via distributed cache. They are normal files and archives. Hadoop leaves the normal files intact on the task node. On the other hand, it unarchives the archives on the task nodes. Below is the table showing various API methods and their description.
Hadoop Distributed Cache API Methods
Job API MethodGenericsOptionParser EquivalentDescriptionaddCacheFile-filesAdd files to distributed cache for copying to task node.addCacheArchive-archivesAdd archives to distributed cache for unarchiving and copying to task node. setCacheFiles-filesAdd files to distributed cache for copying to task node.setCacheArchives-archivesAdd archives to distributed cache for unarchiving and copying to task node. addFileToClassPath-libjarsAdd files to distributed cache for copying to task?s classpath. The files are not unarchived. So this a way to add JAR files to classpathaddArchiveToClassPathNoneAdd the archives to the distributed cache. Which Hadoop unarchives and adds to the task?s classpath.
The URIs in the add and set methods must refer to the file in HDFS, which is the shared filesystem when the job runs. But in GenericOptionParser the file referred, may be on the local file system. Hence it copied to the default shared file system normally HDFS.
The key difference between Java API and GenericOptionParser is that:
Java API does not copy the file referred in add and set methods to a shared file system. On The other hand, GenericOptionParser does.
Summary
Distributed Cache is the mechanism to distribute files needed by the application to all the involved task nodes. You can specify the file you want to distribute via Java API or GenericOptionParser. We can use this method to broadcast small to medium sized files. Hadoop makes the file available to each worker node via distributed cache where the tasks for the job is running. And after the tasks have finished the file is eligible for deletion. We can control the size of distributed cache via setting the relevant property in mapred-site.xml.
It is the time to prepare for Hadoop Interview ? Check Most Asked Hadoop Interview Questions
Enjoyed reading this? Please share your valuable feedback on Hadoop Distributed Cache through comments. If you want to learn any other topic of Hadoop and Big Data, do let me know.
Recommended Articles –
Hadoop Career Opportunities
Hadoop vs Spark vs Flink

{kind=link}
{kind=link}