So I study attractiveness as part of my PhD, and some people recently asked me for my take on ?hotness algorithms?, or websites where you can upload your face and it tells you how hot you are. The 2 that are most popular seem to be http://hotness.ai/ and https://www.prettyscale.com/. They look fairly sciency, with hotness.ai stating ?Let Artificial Intelligence decide if you are Hot or Not?. So I thought, let?s put these algorithms to the test!
You see, we have the perfect data to validate these algorithms. ?we? ? yes we! As in you and I! Ben Jones and Lisa DeBruine who lead the University of Glasgow Facelab (where I did my MSc degree) have made a set of 102 facial photos of people of varying ethnicity freely available on figshare. Crucially, they have had these faces rated for attractiveness by as many as 1000 raters ! So we know fairly well how attractive actual humans find these faces. I ran 79 of these faces (well, 80 but 1 got such weird ratings I discarded it) through both Hotness.ai and prettyscale and compared their scores to ratings from real people:
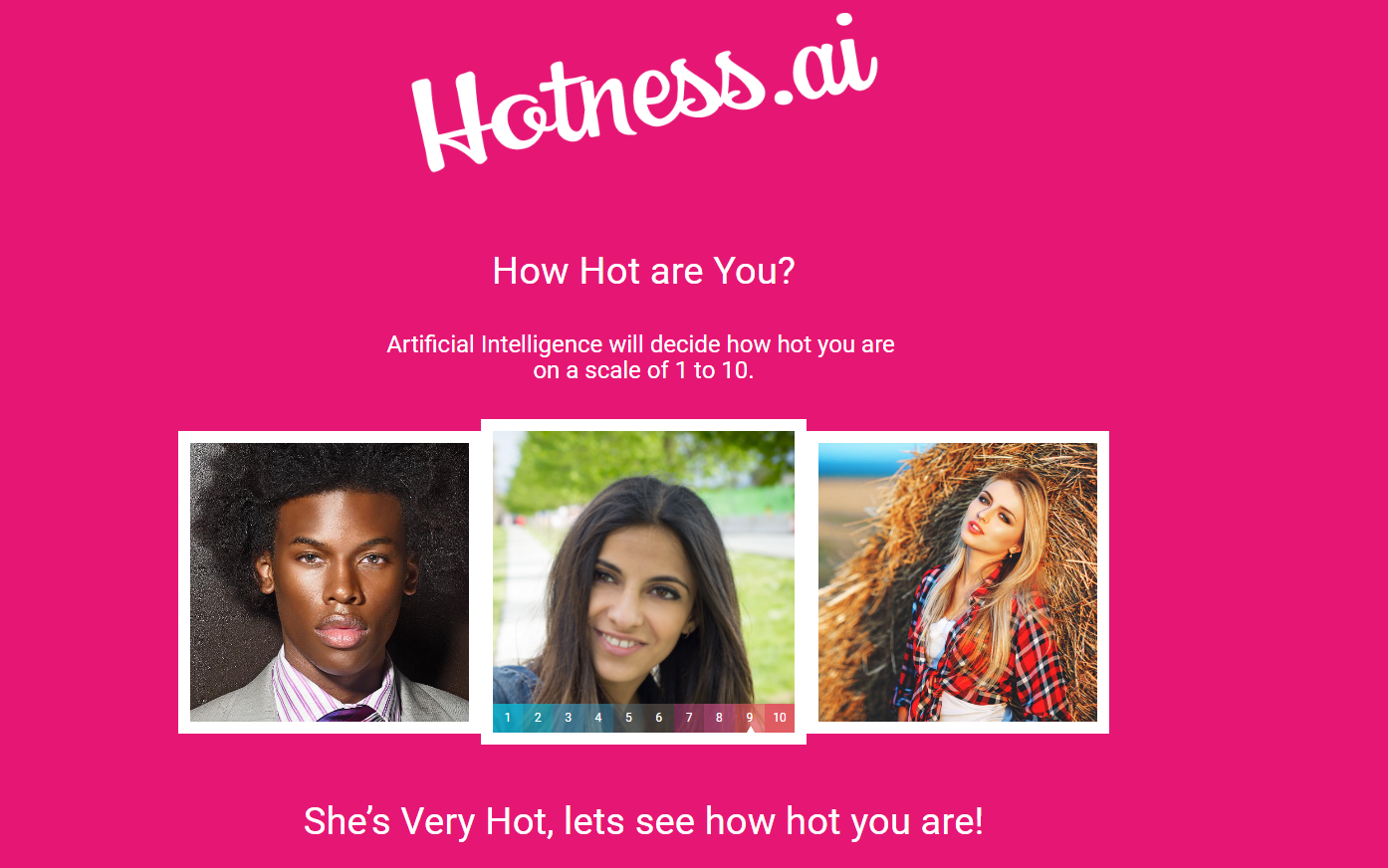
first up: Hotness.ai. The Spearman?s correlation between this one and the Facelab ratings is r(77)= +0.53. Not bad, as a social scientist you dream of correlations so high! But that?s not very high a correlation for 2 methods that are supposed to be capturing the same thing!
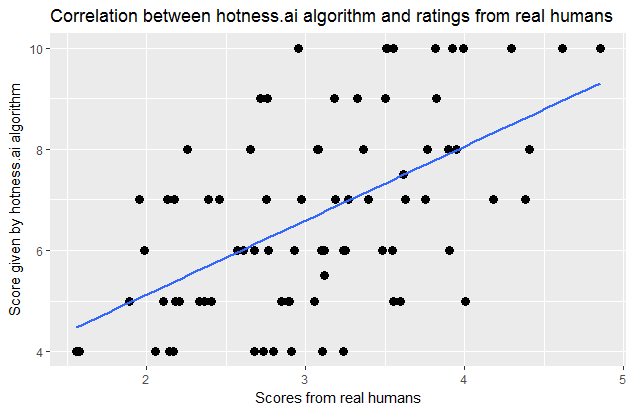
Prettyscale does about the same: r(77)=+0.52:
So perhaps these algorithms are using basically the same features to make their (not so great) predictions? Well here it gets more interesting, because the correlation between hotness.ai?s score and that of prettyscale is low: r(77)=0.19, the p value is 0.09, so not even significant by the traditional criteria of significance. The algorithms are both doing ok at guessing the attractiveness of a face, but don?t seem to agree with each other at all! Perhaps they are using different information to come to their decisions?
Anyway, this gave me an interesting idea: would they do better if they were averaged? So i threw them both into a multiple regression to predict the facelab scores:
So in a linear regression on their own, hotness.ai and prettyscale explained 30% and 25% respectively of the variation in the real human score, but together they explain 46% of the variance. Both are significant, indicating that they explain unique proportions of the variance in scores. We can kinda visualise this by plotting the scores from actual humans against a simple average of both algorithms:
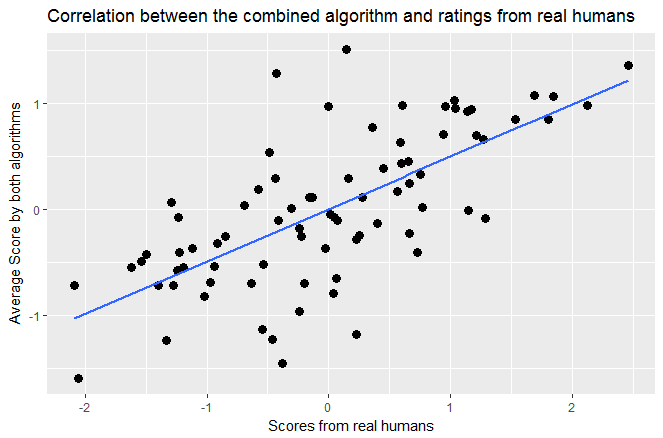
Just eyeballing it, it seems a bit better!
I could do more with this, and may do some time, but in conclusion: neither algorithm is very good, and you?d be better off taking an average!

{kind=link}
{kind=link}