
 Photo by Joshua Eckstein on Unsplash
Photo by Joshua Eckstein on Unsplash
Once you have built a classification model, you need evaluate how good the predictions made by that model are. So, how do you define ?good? predictions?
There are some performance metrics which help us improve our models. Let us explore the differences between them for a binary classification problem:
Consider the following Confusion Matrix for a classification problem which predicts whether a patient has Cancer or not for 100 patients:
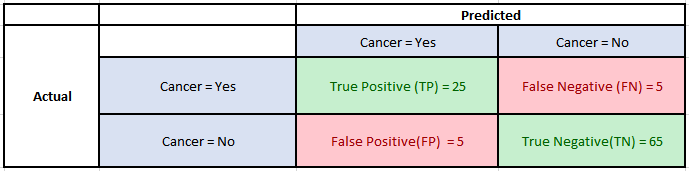 Confusion Matrix
Confusion Matrix
Now, the following are the fundamental metrics for the above data:
1 ? Precision: It is implied as the measure of the correctly identified positive cases from all the predicted positive cases. Thus, it is useful when the costs of False Positives is high.
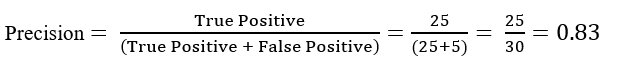 Precision
Precision
2 ? Recall: It is the measure of the correctly identified positive cases from all the actual positive cases. It is important when the cost of False Negatives is high.
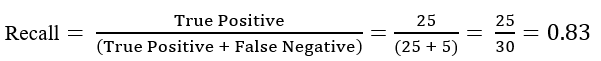 Recall
Recall
3 ? Accuracy: One of the more obvious metrics, it is the measure of all the correctly identified cases. It is most used when all the classes are equally important.
 Accuracy
Accuracy
Now for our above example, suppose that there only 30 patients who actually have cancer. What if our model identifies 25 of those as having cancer?
The accuracy in this case is = 90% which is a high enough number for the model to be considered as ?accurate?. However, there are 5 patients who actually have cancer and the model predicted that they don?t have it. Obviously, this is too high a cost. Our model should try to minimize these False Negatives.
For these cases, we use the F1-score.
4 ? F1-score: This is the harmonic mean of Precision and Recall and gives a better measure of the incorrectly classified cases than the Accuracy Metric.
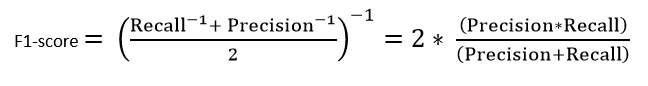 F1-Score
F1-Score
We use the Harmonic Mean since it penalizes the extreme values.
To summarise the differences between the F1-score and the accuracy,
- Accuracy is used when the True Positives and True negatives are more important while F1-score is used when the False Negatives and False Positives are crucial
- Accuracy can be used when the class distribution is similar while F1-score is a better metric when there are imbalanced classes as in the above case.
- In most real-life classification problems, imbalanced class distribution exists and thus F1-score is a better metric to evaluate our model on.

{kind=link}
{kind=link}