Okay, those who saw this term for the first time in their life may be in awe of this new term (like me), murmuring: ?Wow, another fancy technique in the computer science world I have to learn??
However, it?s not true. It?s actually just like the most familiar technique we?ve ever known ? Caching!
In the computer science world, caching is everywhere. From the hardware to software, caching exists almost in each layer (physical or abstraction). For example, L1, L2, L3 cache in the CPU, Database buffer (InnoDB buffer pool in MySQL), local cache in the browser (e.g local storage, IndexDB), HTTP cache control?etc.
All the goals of caching are the same ? Avoid doing the same work repeatedly to avoid spending unnecessary running time or resources! Because we, the computer science guys are ?lazy?, we don?t want to do the same expensive works repeatedly. That?s stupid! We?d rather trade some space (memory or disk) for running the code faster and more efficiently.
For memoization, it?s just the caching technique in the scope of Function!
From wikipedia, the definition of Memoization is
In computing, memoization or memoisation is an optimization technique used primarily to speed up computer programs by storing the results of expensive function calls and returning the cached result when the same inputs occur again.
Sounds pretty straightforward right? We just return the cached result if calling a function with the same parameters without recalculating (But the requirement is that the function is a pure function). Okay, code tells, so let?s see some real examples.
Memoization is a way to lower a function?s time cost in exchange for space cost
NOTE: The following examples will be written in Javascript.
Dummy Example
const dummyLookup = {};function dummy(a, b, c) { const key = `${a}-${b}-${c}`; if (key in dummyLookup) { return dummyLookup[key]; } return a + b + c;}
As you can see, we transform the parameters of dummy to string and concatenate them to be the key of the lookup table. So say, if we call 10000 times of dummy(1, 2, 3), the real calculation happens only the first time, the other 9999 times of calling just return the cached value in dummyLookup, FAST!
Easy huh? But I know you?re uncomfortable about the dummyLookup which is defined outside of dummy.
Looks like we can turn any pure function to the memoized version? Yes! Exactly! Why don?t we have some helper function to do this for us so we don?t need to write the boilerplate code of the lookup table?
So let?s write a higher-order function to return the memoized version of any pure function!
NOTE: The below example only works if arguments to f all have distinct string representations.
function memoize(f) { const cacheLookup = {}; // Value cache stored in the closure return function() { const key = Array.prototype.join.call(arguments,’-‘); if (key in cacheLookup) { return cacheLookup[key]; } else { return cacheLookup[key] = f.apply(this, arguments); } }}
So let?s use memoize to return the memoized dummy!
function dummy(a, b, c) { console.log(‘computing…’); return a + b + c;}const memoizedDummy = memoize(dummy);dummy(1, 2, 3); // 6 is returned and ‘computing’ is printeddummy(1, 2, 3); // 6 is returned but nothing is printed!
Use Cases
For now, we can easily think of 2 use cases to turn a function to its memoized version.
- If the function is pure and computation intensive and called repeatedly
- If the function is pure and is recursive
The first one is straightforward, it?s just simple caching.The second one is more interesting and remind us something??
Dynamic Programming!
Fibonacci Example
We can write a recursive function to derive Fibonacci number in a breeze.
function fibonacci(n) { if ((n === 0) || (n === 1)) { return n; } return (fibonacci(n – 1) + fibonacci(n – 2));}
The code is so clean, so neat and so beautiful right 😉 ? However, its complexity is O(2^n), bad? If we break down the code execution to the following graph (Take n = 6)
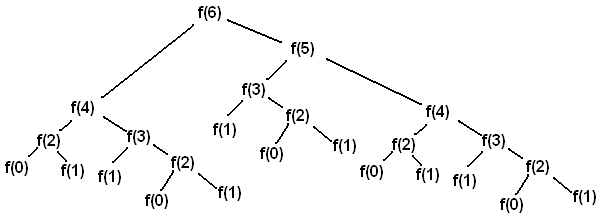
We can notice that there?re some repeated calculations. For example, fibonacci(3) is computed 3 times! If we make fibonacci memoized, then we can guarantee for a number n, it?s fibonacci number will be calculated only once.
To make fibonacci memoized, we want it to recurse to the memoized version, not the original, so it can be written like this.
const fibonacci = memoize(function (n) { if ((n === 0) || (n === 1)) { return n; } return (fibonacci(n – 1) + fibonacci(n – 2));});
As you can see in the graph below, the values in the blue boxes are values that already have been calculated and the calls can thus be skipped. And voila! The complexity turns to O(n) now! (However the space also becomes O(n))
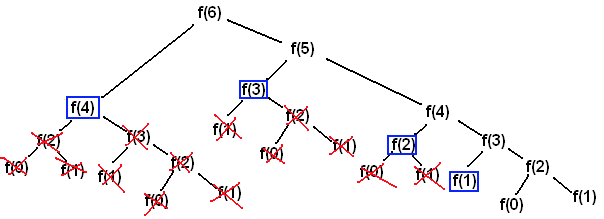
Memoziation is beneficial when there are common subproblems that are being solved repeatedly. Thus we are able to use some extra storage to save on repeated computation.
Dynamic Programming
As mentioned earlier, memoization reminds us dynamic programming. Although DP typically uses bottom-up approach and saves the results of the sub-problems in an array table, while memoization uses top-down approach and saves the results in a hash table. They basically shares the same idea or we can say they?re the same thing ? They all save the results of the sub-problems in the memory and skip recalculations of those sub-problems if their answers are already in the memory.
So what?s the difference?
- Top-down v.s Bottom-up DP solves the problem ?bottom-up? by solving all related sub-problems first, typically by filling up an n-dimensional table. Based on the results in the table, the solution to the original problem is then computed. Because it?s ?bottom-up?, it?ll solve all the sub-problems even if the top problem may not need them.Memoization solves the problem ?top-down? by maintaining a map of already solved sub-problems. It solves the ?top? problem first which typically recurses down to solve the sub-problems. Because it?s ?top-down?, it?ll only solve the needed sub-problems.
- Recursive v.s IterativeDP is iterative (using loops), meaning it doesn?t have the drawback that Memoization has ?Recursion overhead and the fatal Maximum call stack size exceeded problem.
Application Example
Time to see some real world examples.
reselect ? Selector library for Redux
To hook React with Redux, people normally uses react-redux binding. This library provides an API mapStateToProps to pass the state which lives in Redux world to the React world.
In the following example from reselect Github page, we can see that every time the state tree is updated, getVisibleTodos will be called once. If the state tree is large, or the calculation expensive, repeating the calculation on every update may cause performance problems.
const mapStateToProps = (state) => { return { todos: getVisibleTodos(state.todos, state.visibilityFilter) }}
So reselect stands in to help to avoid these unnecessary recalculations by creating a ?memoized? selector. It recalculates todos when the value of state.todos or state.visibilityFilter changes, but not when changes occur in other (unrelated) parts of the state tree.
Reselect provides a function createSelector for creating memoized selectors. createSelector takes an array of input-selectors and a transform function as its arguments. If the Redux state tree is mutated in a way that causes the value of an input-selector to change, the selector will call its transform function with the values of the input-selectors as arguments and return the result. If the values of the input-selectors are the same as the previous call to the selector, it will return the previously computed value instead of calling the transform function.
The following code is the example of usage, the last function is the transform function for computing the final result, and the previous functions are selector functions.
const getVisibleTodosFilteredByKeyword = createSelector( [ getVisibleTodos, getKeyword ], (visibleTodos, keyword) => visibleTodos.filter( todo => todo.text.includes(keyword) ))
So where does the memoization lives? Let?s dive into the source code of reselect (Actually the source code is just around 100 lines of code!). The way it generates the memoized function is similar to our version.
function defaultMemoize(func, equalityCheck = defaultEqualityCheck) { let lastArgs = null let lastResult = null // we reference arguments instead of spreading them for performance reasons return function () { if (!areArgumentsShallowlyEqual(equalityCheck, lastArgs, arguments)) { // apply arguments instead of spreading for performance. lastResult = func.apply(null, arguments) } lastArgs = arguments return lastResult }}
defaultMemoize is also a higher order function to return the memoized function, but instead of maintaining a map, it saves the last arguments in lastArgs which means it can ?remember? only one last results. The wrapped function will only get called if the current arguments are different from lastArgs by checking areArgumentsShallowlyEqual.
areArgumnetsShallowlyEqual simply checks if all previous arguments and next arguments are strictly equal (===).
function areArgumentsShallowlyEqual(equalityCheck, prev, next) { if (prev === null || next === null || prev.length !== next.length) { return false } // Do this in a for loop (and not a `forEach` or an `every`) so we can determine equality as fast as possible. const length = prev.length for (let i = 0; i < length; i++) { if (!equalityCheck(prev[i], next[i])) { return false } } return true}
Looking at the createSelector([…selectors], trasnformFunction) API again, what reselect does is just making trasnformFunction memoized! The output of selectors will be the input of transformFunction, and if all the inputs are the same as the last calling, transformFunction will just return the cached result without ?computing? the inputs.
Conclusion
Memoization is a technique of caching function results ?in? the function itself to make the function have memory, and the callers won?t need to know if the function is memoized or not. If the function is get called with the same arguments as before (You can determine how big the function?s memory is), it just need to return the cached result without actually doing the computation. Although we can literally make any pure function memoized, we should consider to do so only for those possibly frequently called functions whose arguments may appear the same repeatedly.


{kind=link}
{kind=link}