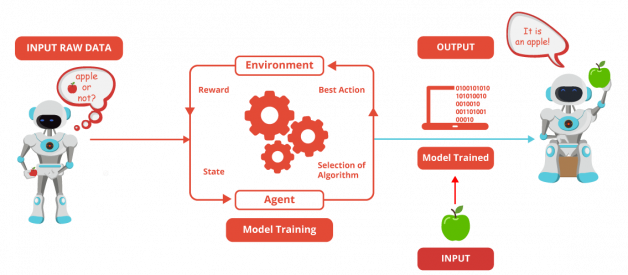
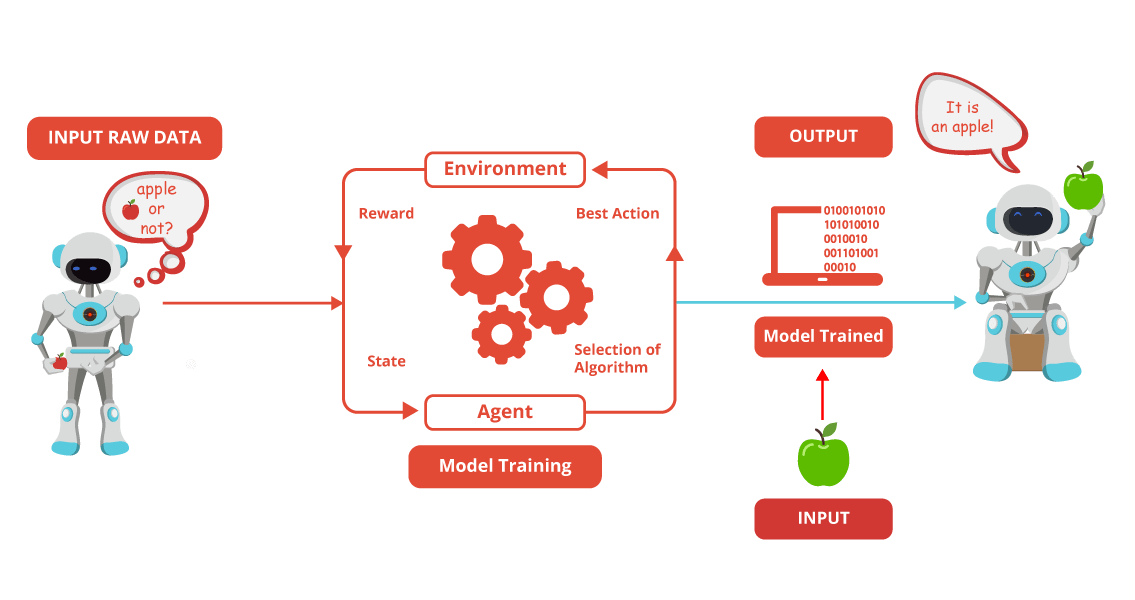
This is a complementary article related to my data science articles bringing more understanding for my readers.
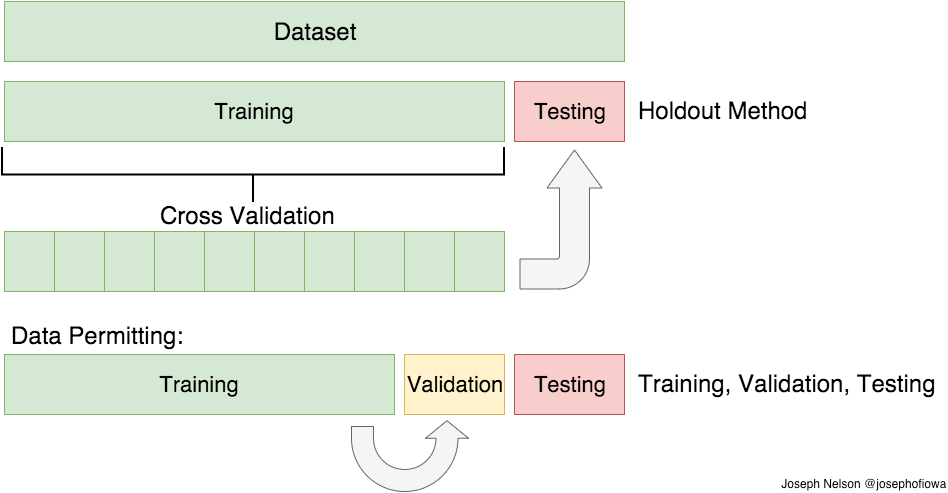
In a dataset, a training set is implemented to build up a model, while a test (or validation) set is to validate the model built. Data points in the training set are excluded from the test (validation) set. Usually, a dataset is divided into a training set, a validation set (some people use ?test set? instead) in each iteration, or divided into a training set, a validation set and a test set in each iteration.
In Machine Learning, we basically try to create a model to predict the test data. So, we use the training data to fit the model and testing data to test it. The models generated are to predict the results unknown which is named as the test set. As you pointed out, the dataset is divided into train and test set in order to check accuracies, precisions by training and testing it on it.
The proportion to be divided is completely up to you and the task you face. It is not essential that 70% of the data has to be for training and rest for testing. It completely depends on the dataset being used and the task to be accomplished. For example, a simple dataset like Reuters. So, assume that we trained it on 50% data and tested it on rest 50%, the precision will be different from training it on 90% or so. This is mostly because, in Machine Learning, the bigger the dataset to train is better. You can refer to this paper, which tells the precision values based on the dataset size. It now depends on you, what precision or accuracy you need to achieve based on your task.
This said so, how would you predict the results for which you do not have the answer? (The model is ultimately being trained to predict results for which we do not have the answer). I would like to add on about validation dataset here.
Sets:
- Training Set: Here, you have the complete training dataset. You can extract features and train to fit a model and so on.
- Validation Set: This is crucial to choose the right parameters for your estimator. We can divide the training set into a train set and validation set. Based on the validation test results, the model can be trained(for instance, changing parameters, classifiers). This will help us get the most optimized model.
- Testing Set: Here, once the model is obtained, you can predict using the model obtained on the training set.
If you want to know more about algorithmic trading, you can have more information following this class.


{kind=link}
{kind=link}