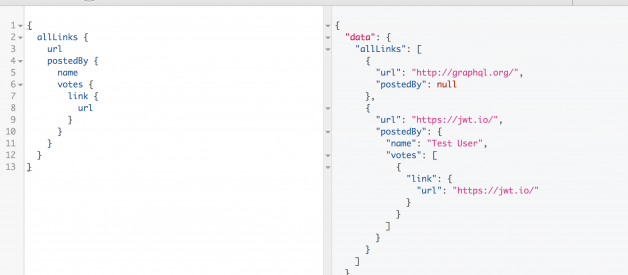
GraphQL is one of the most modern ways of building and querying APIs.

GraphQL is a syntax that describes how to ask for data, and is generally used to load data from a server to a client. GraphQL has three main characteristics:
- It lets the client specify exactly what data it needs.
- It makes it easier to aggregate data from multiple sources.
- It uses a type system to describe data.
With GraphQL, the user is able to make a single call to fetch the required information rather than to construct several REST requests to fetch the same.
GitHub uses GraphQL as it offers more flexibility for the developers. The option to precisely generate the information that a user wants is a great advantage over sending multiple REST calls to receive the same. To generate the information using REST calls would require a two stage process ? One to gather the information of the user and the other to fetch the information about the organization the user is associated with. GraphQL helps alleviate this two-step process.
So What is GraphQL?
A GraphQL query is a string that is sent to a server to be interpreted and fulfilled, which then returns JSON back to the client.
Defines a data shape: The first thing you?ll notice is that GraphQL queries mirror their response. This makes it easy to predict the shape of the data returned from a query, as well as to write a query if you know the data your app needs. More important, this makes GraphQL really easy to learn and use. GraphQL is unapologetically driven by the data requirements of products and of the designers and developers who build them.
Hierarchical: Another important aspect of GraphQL is its hierarchical nature. GraphQL naturally follows relationships between objects, where a RESTful service may require multiple round-trips (resource-intensive on mobile networks) or a complex join statement in SQL. This data hierarchy pairs well with graph-structured data stores and ultimately with the hierarchical user interfaces it?s used within.
Strongly typed: Each level of a GraphQL query corresponds to a particular type, and each type describes a set of available fields. Similar to SQL, this allows GraphQL to provide descriptive error messages before executing a query.
Protocol, not storage: Each GraphQL field on the server is backed by any arbitrary function. GraphQL had to leverage all this existing work to be useful, and so does not dictate or provide any backing storage. Instead, GraphQL takes advantage of your existing code.
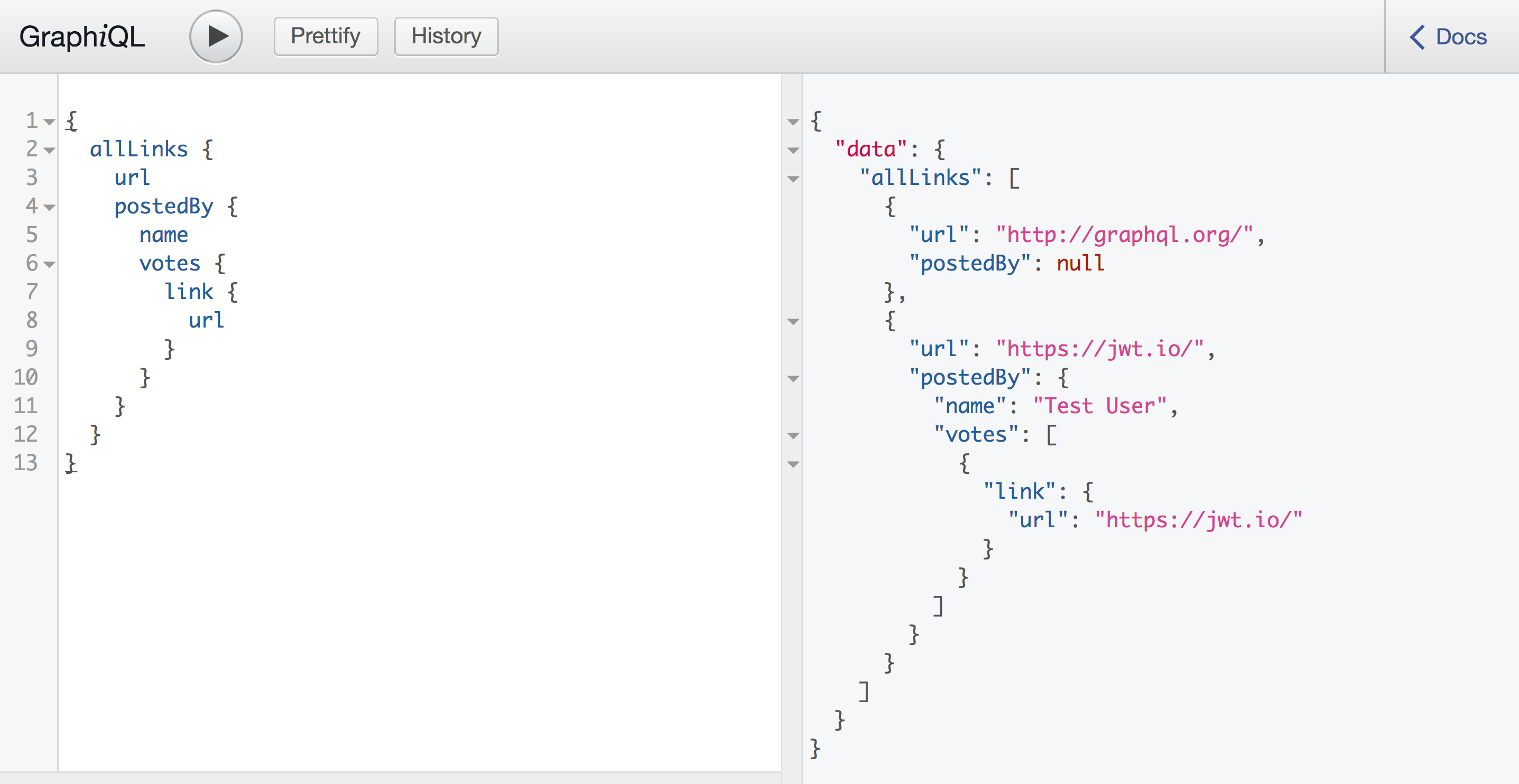
Introspective: A GraphQL server can be queried for the types it supports. This creates a powerful platform for tools and client software to build atop this information like code generation in statically typed languages, Relay, or IDEs like GraphiQL (pictured below). GraphiQL helps developers learn and explore an API quickly without grepping the codebase or wrangling with cURL.
Version free: The shape of the returned data is determined entirely by the client?s query, so servers become simpler and easy to generalize. When you?re adding new product features, additional fields can be added to the server, leaving existing clients unaffected. When you?re sunsetting older features, the corresponding server fields can be deprecated but continue to function. This gradual, backward-compatible process removes the need for an incrementing version number.
Coming next week:
- GraphQL basics
- REST vs GraphQL
- Running a GraphQL endpoint with Serverless?
What Is Serverless?
Although the cloud has revolutionized the way we manage applications, many companies still view their systems in terms?
medium.com
Like to learn?
Follow me on twitter where I post all about the latest and greatest AI, DevOps, VR/AR, Technology, and Science! Connect with me on LinkedIn too!


{kind=link}
{kind=link}