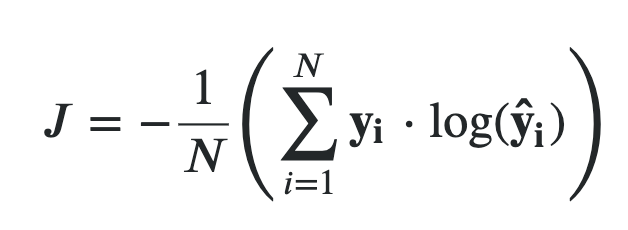
We have always wanted to write about Cross Entropy Loss. It is only a natural follow-up to our popular Softmax activation article. They are best buddies. It was so strange to write one about Softmax without mentioning cross entropy loss! We also listen to our readers in our vote for article pipeline article. Our goal is to write as many beginner friendly ML, DL, reinforcement learning and data science tutorials as possible. The next step is to write about machine learning papers and write about machine learning in Chinese and Japanese! If you like the ideas, please vote in our pipeline article. As usual, if you want, you can read this article in incognito mode. Want to be an Uniqtech student scholar? Write us [email protected] we will give you some articles for free in exchange of your feedback and/or email signup. We will assume you know what Softmax is. If not, please read our previous article. It?s the most popular on the internet.
There is binary cross entropy loss and multi-class cross entropy loss. Let?s talk about the cross entropy loss first, and the binary one will hopefully be an afterthought. So now you know your Softmax, your model predicts a vector of probabilities[0.7, 0.2, 0.1] Sum of 70% 20% 10% is 100%, the first entry is the most likely. And yes your true label says [1, 0, 0] ? definitely a cat, not a dog at entry 2, and definitely not a bird at entry 3. So how well did your model?s probability prediction do? A little linear algebra will help ? dot product in particular! The dot product is the sum of the multiplication of two vectors entry-by-entry. Pseudo code is [0.7, 0.2,0.1] dot [1,0,0].transpose that is a 1 by 3 vector dot a 3 by 1 vector = 1×1 = a number. 0.7 *1 + 0.2 * 0 + 0.1 * 0= 0.7 . Note that the incorrect entry will always be zero because anything multiplied by zero is zero. And the true label always only have one entry that is 1 [1,0,0], [0,1,0], or [0,0,1] thou can only be a cat, dog or a bird, can?t have it all!
To calculate how similar two vectors are, calculate their dot product! ? said us Uniqtech 🙂
Why are we doing random calculations? Aren?t we doing cross entropy loss? The above approach is one way to measure the similarity between two vectors. In fact it is used in movie and book recommendation systems, called collaborative filtering! More about that in a different article. Cross entropy is another way to measure how well your Softmax output is. That is how similar is your Softmax output vector is compared to the true vector [1,0,0], [0,1,0],[0,0,1] for example if there are only three classes. Just a reminder Softmax is for multi-class classification tasks. For regression tasks, you can use the mean square loss MSL. For multi-class classification tasks, cross entropy loss is a great candidate and perhaps the popular one!
See the screenshot below for a nice function of cross entropy loss. It is from an Udacity video which we will also link to. But let?s go through it together for a few minutes first. Another name for this is categorical cross entropy loss.
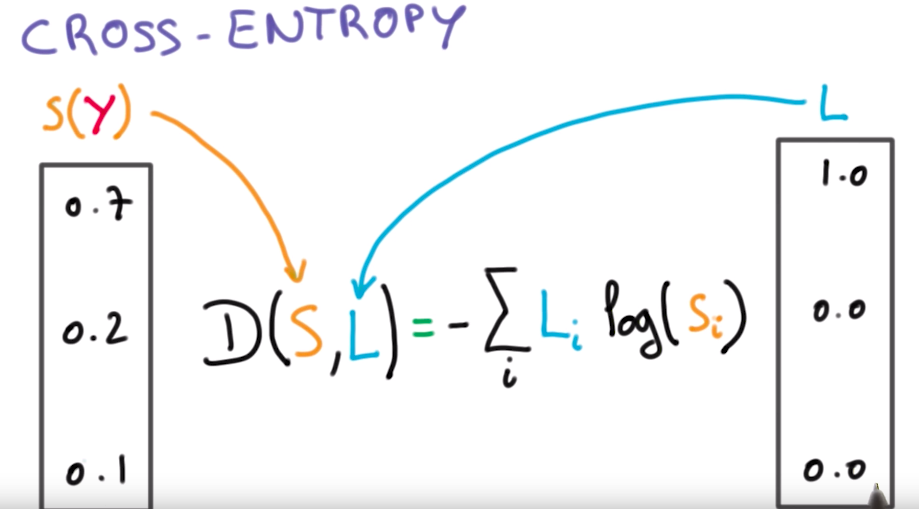
S(y) is the output of your softmax function. It is a prediction, so we can also call it y_hat. L is the ground truth! The one hot encoded label of the true class, only one entry is one, the rest are zeroes. For each entry in your output vector, Step 1 Softmax takes the log of that first entry, usually an less-than-one number, so it?s very negative for example log_base_2 of 0.7 is negative 0.5145731728297583 and 2 to the -0.5145731728297583th power is 0.7 , Step 2 the entry is multiplied by the ground truth log(0.7)*1 , and then Step 3 we do that for each of the entry log(0.2)*0 which is of course zero and then log(0.1)*0 which is also zero, then step 4 because of the big sigma summing simple in front of L_i Log(S_i) we sum all the losses up which is -0.5145731728297583, Step 5 we multiply by -1 because of the big negative sign in the front and turn the loss into a positive number 0.5145731728297583
It?s easy to remember that the log only applies to Softmax output because the one-hot-encoded ground truth almost always have zero entries, and we cannot take log of zero.
Just like Mean Square Loss we can take the advantage of the losses, see the 1/N in the screenshot below. This makes the loss function work nicely even if the number of data points is large. In the screenshot below, y is the ground truth and y_hat is the prediction. Same thing as above, just with a 1/N to calculate the average.
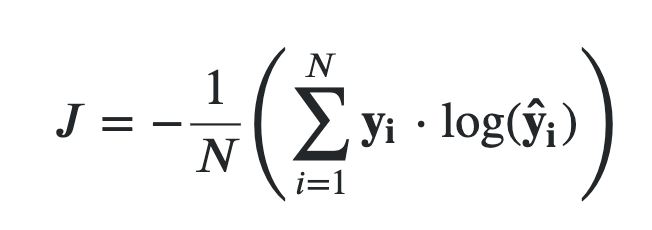
Binary Cross Entropy (Log Loss)
Binary cross entropy loss looks more complicated but it is actually easy if you think of it the right way.
Remember there can only be two state of the world in binary classification, either y the ground truth is one or zero.
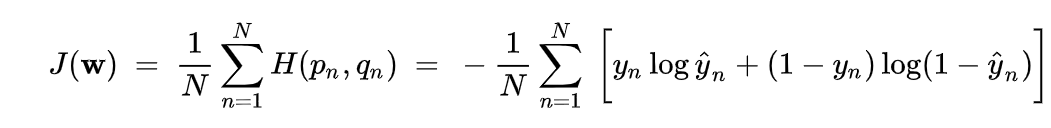
If y=0, the first term is zero, so we only calculate (1- y) * log(1-y_hat). Because y is zero, (1-y) = 1?0 = 1. So this term is just log(1?y_hat).
If y =1, then second term is zero, only the first term take effect.
See below for an image of binary cross entropy in the wild. Example is the ChexNet paper by Stanford.

Cross Entropy Loss in Deep Learning
Where does the cross entropy function fit in my deep learning pipeline? It sits right after the Softmax function, and it takes in the input from the Softmax function output and the true label.
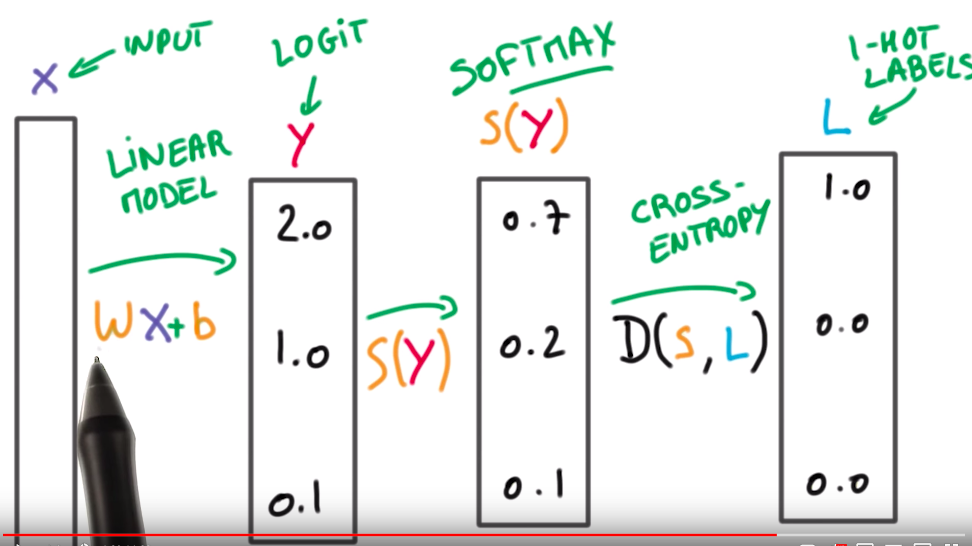
Now that you know a lot about Cross Entropy Loss you can easily understand this video below by a Google Deep Learning practitioner.
Remember the goal for cross entropy loss is to compare the how well the probability distribution output by Softmax matches the one-hot-encoded ground truth label of the data. One hot encoded just means in each column vector only one entry is 1 the rest are zeroes. It is usually used in encoding categoric data where all the classes or categories are independent ? an object cannot simultaneously be a cat, dog and a bird for example.
Follow us for more articles like this!
Why the log in the formula? Intuition tells us that to measure the similarity between two vectors we can take the dot product of the two. Cross entropy formula is rooted in information theory, measures how fast information can be passed around efficiently for example, specifically encoding that encodes more frequent information with small number of bits. It turns out that it is calculated using a log. log(1/y) for example.


{kind=link}
{kind=link}