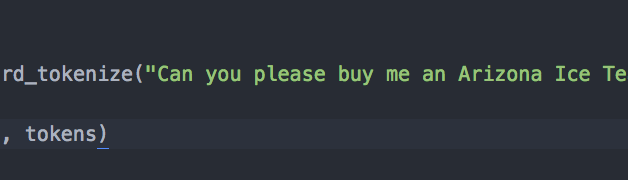
Python?s NLTK library features a robust sentence tokenizer and POS tagger. Python has a native tokenizer, the .split() function, which you can pass a separator and it will split the string that the function is called on on that separator. The NLTK tokenizer is more robust. It tokenizes a sentence into words and punctuation. Given the following code:

It will tokenize the sentence Can you please buy me an Arizona Ice Tea? It’s $0.99.” as follows:
[?Can?, ?you?, ?please?, ?buy?, ?me?, ?an?, ?Arizona?, ?Ice?, ?Tea?, ???, ?It?, ??s?, ?$?, ?0.99?, ?.?]
Note that the tokenizer treats ‘s , ‘$’ , 0.99 , and . as separate tokens. This is important because contractions have their own semantic meaning as well has their own part of speech which brings us to the next part of the NLTK library the POS tagger. The POS tagger in the NLTK library outputs specific tags for certain words. The list of POS tags is as follows, with examples of what each POS stands for.
- CC coordinating conjunction
- CD cardinal digit
- DT determiner
- EX existential there (like: ?there is? ? think of it like ?there exists?)
- FW foreign word
- IN preposition/subordinating conjunction
- JJ adjective ?big?
- JJR adjective, comparative ?bigger?
- JJS adjective, superlative ?biggest?
- LS list marker 1)
- MD modal could, will
- NN noun, singular ?desk?
- NNS noun plural ?desks?
- NNP proper noun, singular ?Harrison?
- NNPS proper noun, plural ?Americans?
- PDT predeterminer ?all the kids?
- POS possessive ending parent?s
- PRP personal pronoun I, he, she
- PRP$ possessive pronoun my, his, hers
- RB adverb very, silently,
- RBR adverb, comparative better
- RBS adverb, superlative best
- RP particle give up
- TO, to go ?to? the store.
- UH interjection, errrrrrrrm
- VB verb, base form take
- VBD verb, past tense took
- VBG verb, gerund/present participle taking
- VBN verb, past participle taken
- VBP verb, sing. present, non-3d take
- VBZ verb, 3rd person sing. present takes
- WDT wh-determiner which
- WP wh-pronoun who, what
- WP$ possessive wh-pronoun whose
- WRB wh-abverb where, when

As you can see on line 5 of the code above, the .pos_tag() function needs to be passed a tokenized sentence for tagging. The tagging is done by way of a trained model in the NLTK library. The included POS tagger is not perfect but it does yield pretty accurate results. Using the same sentence as above the output is:
[(?Can?, ?MD?), (?you?, ?PRP?), (?please?, ?VB?), (?buy?, ?VB?), (?me?, ?PRP?), (?an?, ?DT?), (?Arizona?, ?NNP?), (?Ice?, ?NNP?), (?Tea?, ?NNP?), (???, ?.?), (?It?, ?PRP?), (??s?, ?VBZ?), (?$?, ?$?), (?0.99?, ?CD?), (?.?, ?.?)]
Parts of speech tagging can be important for syntactic and semantic analysis. So, for something like the sentence above the word can has several semantic meanings. One being a modal for question formation, another being a container for holding food or liquid, and yet another being a verb denoting the ability to do something. Giving a word such as this a specific meaning allows for the program to handle it in the correct manner in both semantic and syntactic analyses.


 Tagging in Python’s NLTK library){kind=link}
 Tagging in Python’s NLTK library){kind=link}