
Author?s Note: I?m greatly indebted to Marc McBride for reading a draft of this post and offering some excellent suggestions. This is the second installment in my series on testing distributed systems. The posts in this series are the following:
Testing Microservices, the sane way (published December 2017)
Testing in Production, the safe way (published March 2018)
Testing in Production: the hard parts (published in September 2019)
Testing in Production: the fate of state (published December 2020)
In this post, I hope to explore different forms of ?testing in production?, when each form of testing is the most beneficial as well as how to test services in production in a safe way.
However, before I proceed any further, I need to make it explicitly clear that the content of this post only ever applies to the testing of services whose deployment is under the control of engineers developing it. By absolutely no means whatsoever am I suggesting that this form of testing is applicable, let alone advisable, for testing other types of software, such as mobile applications or safety critical systems or embedded software.
It?s also perhaps important to state upfront that none of the forms of testing described here is easy and often requires a fundamental change in the way systems are designed, developed and tested. And despite the title, I do not believe that any form of testing in production is entirely risk-free; only that it greatly helps minimize the risk profile of the service further down the road, making the investment justifiable.
Why test in production when one can test in staging?
A staging cluster or a staging environment can mean different things to different people. At many companies, ?deploying? to staging and testing in staging is an integral precursor to the final rollout.
Most organizations I know of treat staging as a miniature replica of the production environment. In such cases, keeping the staging environment as ?in-sync? as possible with production becomes a requirement. This usually involves running a ?different? instance of stateful systems like databases, and routinely syncing production data to staging modulo certain sensitive bits of user data that might contain any personally identifiable information (PII) to comply with GDPR, PCI, HIPAA and so forth.
The problem with this approach ? at least in my experience ? is that the ?difference? isn?t just curtailed to using a different instance of the database populated with recent production data. Often the difference also extends to:
? the size of the staging cluster (if it even can be called a ?cluster? ? sometimes it?s a single machine masquerading as a cluster)? the fact that staging is usually a much smaller cluster also means that configuration options for pretty much every service is going to be different. This is applicable to the configurations of load balancers, databases and queues (like the number of open file descriptors, the number of open connections to the database, the size of the thread pool, the number of Kafka partitions and so forth). If configuration happens to be stored in either a database or a key value store like Zookeeper or Consul, these auxiliary systems need to be stood up in the staging environment as well.? the number of in-flight connections a stateless service is handling or the way a proxy is reusing TCP connections (if it?s doing it at all)? the lack of monitoring for the staging environment. And even if monitoring exists, several staging monitoring signals could end up being completely inaccurate given that one is monitoring a ?different? environment than the production environment. For example, even with monitoring in place for the MySQL query latency or the response time of an endpoint, it becomes hard to detect if new code contains a query that may trigger a full table scan in MySQL, since it?s way faster (sometimes even preferable) to do a full table scan for a small table used in a test database as opposed to against the production database where the query might have a vastly different performance profile.
While it?s fair enough to suggest that all of the aforementioned differences aren?t so much arguments against staging environments per se than anti-patterns to be avoided, it also follows that ?doing it right? often entails investing a copious amount of engineering effort to attain any semblance of parity between the environments. With production being ever changing and malleable to a wide variety of forces, trying to attain said parity might be akin to being on a hiding to nothing.
Moreover, even if the staging environment can be mimicked to be as close to production as possible, there are certain other forms of testing that are best performed with real traffic. A good example would be soak testing, which is a form of verification of a service?s reliability and stability over long period of time under a realistic level of concurrency and load, used to detect memory leaks, GC pause times, CPU utilization and so forth over a period of time.
None of this is meant to suggest that maintaining a staging environment is completely useless (as it would become evident in the section on shadowing). Only that, as often as not, it?s relied upon to a much greater degree than necessarily needed, to the point where at many organizations it remains the only form of testing that happens before a full production rollout.
The Art of Testing in Production
Testing in production has historically carried with it a certain stigma and negative connotations linked to cowboy programming, insufficient or absent unit and integration testing, as well as a certain recklessness or lack of care for the end user experience.
When done poorly or haphazardly, ?testing in production? does, in fact, very much live up to this reputation. Testing in production is by no means a substitute to pre-production testing nor is it, by any stretch, easy. In fact, I?d argue that being able to successfully and safely test in production requires a significant amount of automation, a firm understanding of the best-practices as well as designing the systems from the ground up to lend themselves well toward this form of testing.
In order to be able to craft a holistic and safe process to effectively test services in production, it becomes salient to not treat ?testing in production? as a broad umbrella term to refer to a ragbag of tools and techniques. I was guilty of this myself in my previous post where I?d introduced a not very scientific taxonomy of the testing spectrum and had grouped together a miscellany of methodologies and tools under ?testing in production?.
 From my post ?Testing Microservices, the sane way?
From my post ?Testing Microservices, the sane way?
Since the publication of that post in late December 2017, I?ve had conversations with several people about the content of the post as well as on the broader topic of ?testing in production? in general.
In light of these discussions as well as certain orthogonal discussions, it became painfully obvious to me that the topic of ?testing in production? isn?t something that can be reduced to a few bullet points on an illustration.
Instead, I now believe that ?testing in production? encompasses an entire gamut of techniques across three distinct phases.
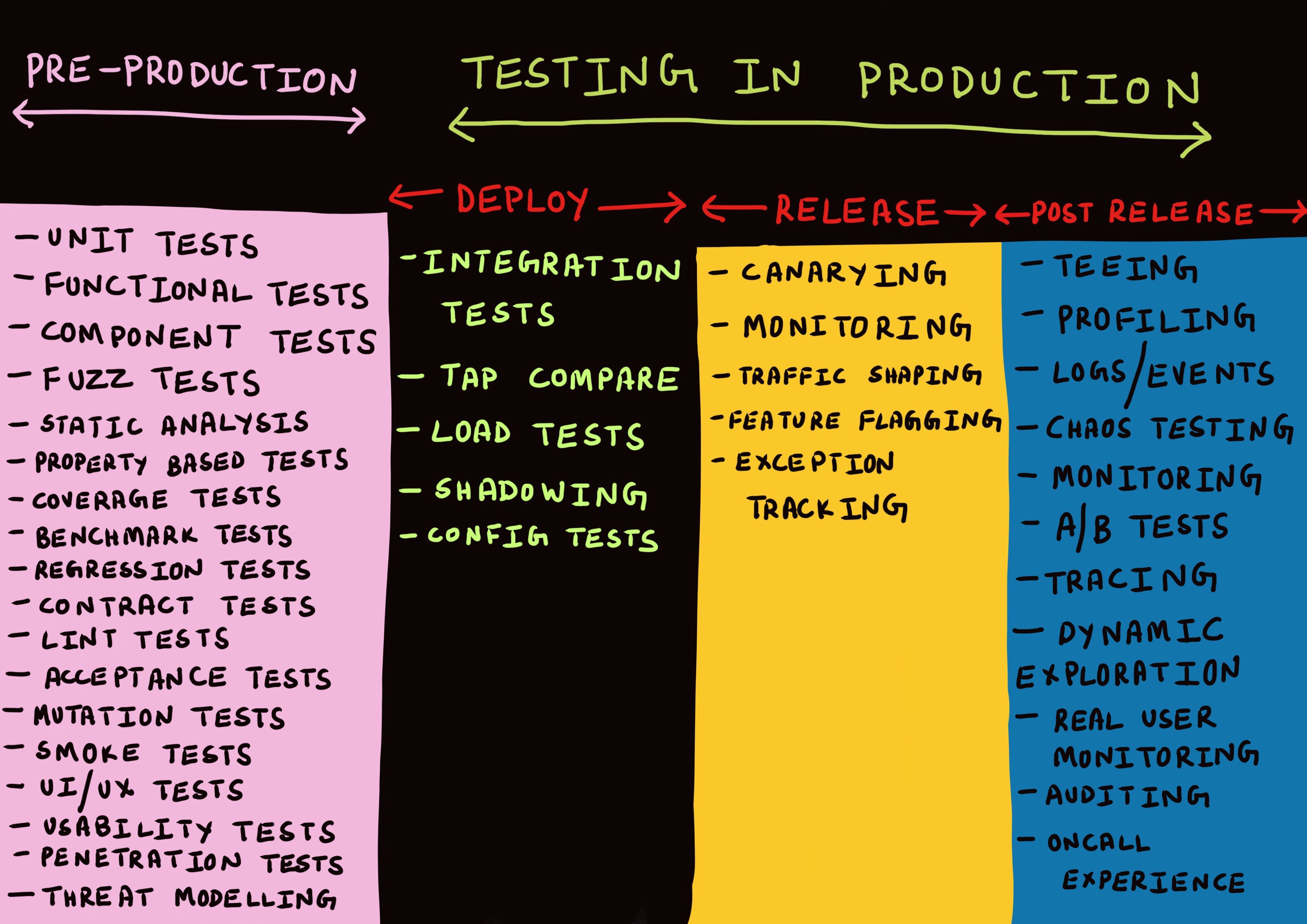
This list is by no means comprehensive nor are the boundaries set in stone. However, I feel it does provide a good starting point to begin the discussion on the topic of testing in production.
The Three Phases of ?Production?
For the most part, discussions about ?production? are only ever framed in the context of ?deploying? code to production or monitoring or firefighting production when something goes awry.
I have myself used terms such as ?deploy?, ?release?, ?ship? and so forth interchangeably until now without giving it much thought. In fact, up until a few months ago, any attempt to make any distinction between these terms would?ve been dismissed by me as immaterial.
Upon giving this more thought, I?ve come around to the idea that there does exist a legitimate need to make a distinction between different phases of production.
Phase 1 ? Deploy
With testing (even in production!) only ever being a best effort verification, the accuracy of testing (or any form of verification for that matter) is contingent on the tests being run in a manner that resembles the way in which the service might be exercised in production in the closest possible way.
The tests, in other words, need to be run in an environment that?s a best effort simulation of the production environment.
And in my opinion, the best effort simulation of the production environment is ? the production environment itself.
To run as many tests as possible in the production environment, it?s required that failure of any such test should not affect the end user.
Which, in turn, is only feasible if deploying a service in the production environment doesn?t expose users to that service immediately.
In this post, I?ve decided to go with the terminology used in the blog post ?Deploy != Release? by the folks at Turbine Labs (no affiliation). The post goes on to describe a ?deploy? as:
Deployment is your team?s process for installing the new version of your service?s code on production infrastructure. When we say a new version of software is deployed, we mean it is running somewhere in your production infrastructure. That could be a newly spun-up EC2 instance on AWS, or a Docker container running in a pod in your data center?s Kubernetes cluster. Your software has started successfully, passed health checks, and is ready (you hope!) to handle production traffic, but may not actually be receiving any. This is an important point, so I?ll repeat it? Deployment need not expose customers to a new version of your service. Given this definition, deployment can be an almost zero-risk activity.
Deployments being a zero-risk activity might be music to the ears of a good many folks who bear battle scars from bad deploys (including yours truly). The ability to safely install software in the actual production environment without exposing users to the newly installed software has numerous benefits when it comes to testing.
For one thing, it minimizes ? if not entirely eliminates ? the need to maintain separate ?dev?, ?test? and ?staging? environments which invariably then become dependencies to be kept in-sync with production.
It also applies a certain design pressure on engineers to decouple their services in a manner that the failure of a test run in production against a given instance of a service does not lead to a cascading or user-impacting failure of other services. One such design decision would be the design of data model and database schema so that non-idempotent requests (primarily writes):
? can be performed against the production database by any service?s test run in production (my preferred approach)? or be safely discarded at the application layer before it hits the persistence layer? or be distinguished or isolated at the persistence layer via some mechanism (such as storing additional metadata)
Phase 2 ? Release
The blog post Deploy != Release goes on to define ?release? as:
When we say a version of a service is released, we mean that it is responsible for serving production traffic. In verb form, releasing is the process of moving production traffic to the new version. Given this definition, all the risks we associate with shipping a new binary ? outages, angry customers, snarky write-ups in The Register ? are related to the release, not deployment, of new software. (At some companies I?ve heard this phase of shipping referred as rollout. We?ll stick to release for this post.)
The Google SRE book uses the term ?rollout? in the chapter on Release Engineering to describe the release process.
A rollout is a logical unit of work that is composed of one or more individual tasks. Our goal is to fit the deployment process to the risk profile of a given service. In development or pre-production environments, we may build hourly and push releases automatically when all tests pass. For large user-facing services, we may push by starting in one cluster and expand exponentially until all clusters are updated. For sensitive pieces of infrastructure, we may extend the rollout over several days, interleaving them across instances in different geographic regions.
A ?release? or a ?rollout? in this nomenclature refers to what the word ?deploy? usually means in common parlance, and terms frequently used to describe different deployment strategies such as ?blue-green deploys? or ?canary deploys?, again, refer to the release of new software.
Furthermore, a bad release of software is what then becomes the cause of a partial or fully blown outage. This also is the phase when a rollback or a roll forward is performed if the newly released version of the service proves to be unstable.
The release process usually works best when it?s automated and incremental. Likewise, rollback or rollforward of the service works best when automated by correlating the error rates or request rates with a baseline.
Phase 3 ? Post-Release
If the release of the service went without a hitch and the newly released service is serving production traffic without any immediate issues, we can consider the release to be successful. What follows a successful release is what I call the ?post-release? phase.
Any sufficiently complex system is going to always exist in a certain degree of degradation. These pathologies aren?t reasons to warrant a rollback or a roll forward; instead they need to be observed (for a variety of business and operational purposes) and debugged when required. As such, ?testing? in the post-release phase resembles not so much traditional testing than debugging or gathering analytics.
In fact, I?d argue that every component of the entire system ought to be built in-keeping with the reality that no large system is ever fully healthy, and that failure is to be acknowledged and embraced at the time of designing, writing, testing, deploying and monitoring the software.
With the three phases of ?production? defined, let?s explore the different testing mechanisms available at each of the different phases. Not everyone enjoys the luxury of working on greenfield projects or rewriting everything from scratch. I?ve taken care to make it explicit in this post as to when a certain technique is best suited to a greenfield development environment, and in the absence of it, what teams can do to still reap most of the benefits of the proposed techniques without requiring to make significant changes to what?s already working.
Testing in Production during the Deploy Phase
Assuming we can divorce the ?deploy? phase from the ?release? phase as outlined above, let?s explore some of the forms of testing that can be performed once the code is ?deployed? to production.
Integration Testing
Traditionally, integration testing is performed by a CI server in an isolated ?testing? environment over every git branch. A copy of the entire service topology (including databases, queues, caches, proxies and so forth) is spun up for the test suites of all the services to be run against each other.
I believe this to be not terribly effective for several reasons. First of all, as with staging, it?s impossible for the test environment being spun up to be identical to the real production environment, even if the tests are run in the same Docker container that will be deployed to production. This is especially true when the only thing that?s running in the test environment are the tests in question.
Furthermore, irrespective of whether the test being run is spawned as a Docker container or a POSIX process, the test is most likely spawning one (or whatever level of parallelism is built into the test harness) connection to an upstream service or a database or a cache, which is rarely ever the case when the service is in production where it might be handling multiple concurrent connections at the same time, oftentimes reusing inactive TCP connections (called HTTP connection reuse).
Also somewhat problematic is that fact that most tests spawn a fresh database table or a cache keyspace often on the same host on which the test is running during each test run (isolating the tests from network failures). This form of testing can only, at best, prove that the system works correctly for a very specific request (at a previous job we called this the test snowflake), and rarely, if ever, is effective in simulating the hard, well-understood failure modes, let alone the multiple modes of partial failure. There is sufficient research to corroborate that distributed systems often times exhibit emergent behavior, which cannot be predicted through analysis at any level simpler than that of the system as a whole.
None of this is to suggest that integration testing on the whole is useless; only that performing integration tests in a completely isolated and artificial environment is, by and large, pointless. Integration testing is still pretty important in order to verify that a new version of a service does not:
? break the contract it exposes to its upstreams or downstreams? affect the SLO of any of the upstreams or downstreams in an adverse way
The first can be achieved to an extent with contract testing. By dint of only enforcing that the interfaces between services are adhered to, contract testing proves to be an effective technique to develop and test individual services in the pre-production phase without requiring to spin up the entire service topology. Consumer driven contract testing frameworks like Pact currently only support RESTful JSON RPC communication between services, though I believe support for asynchronous communication over web sockets, serverless applications and message queues is being worked on. While it might be possible that in the future protocols like gRPC and GraphQL might be supported, it doesn?t currently appear to be the case.
However, before releasing a new version, one might want to more than just verify if interfaces are adhered to. For instance, one might want to verify that the duration of the RPC call between two services falls within an acceptable threshold when the interface between them changes. Additionally, one might also want to make sure that the cache hit ratio remains consistent when, say, an additional query parameter is added to an incoming request.
Integration testing, as it turns out, isn?t optional, and in my opinion, the goal of integration testing is to ensure that the change being tested does not trigger any of the hard, well-understood failure modes of the system (typically the ones that have alerts in place for) at the time of testing.
Which begs the question ? how to safely perform integration testing in production?
Let?s work with the following example to this end. This is an architecture I worked with a couple of years ago where we had multiple web and mobile clients connect to a webserver (service C) backed by MySQL (service D)and fronted by a memcache cluster (service B) .
Though this is a fairly traditional stack (and not particularly microservicy), I feel the mix of stateful and stateless services in this architecture makes it a good candidate to be used as an example in this post.
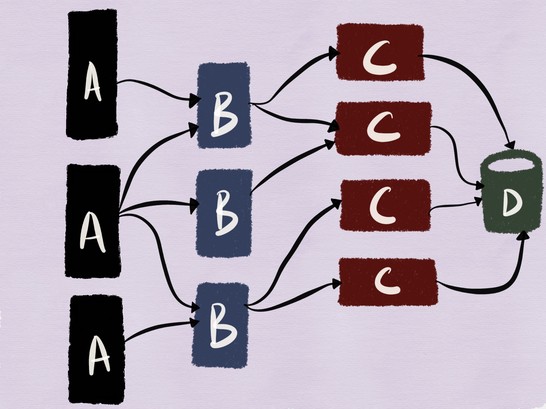
Decoupling a release from a deploy means that we can safely deploy a new instance of a service into the production environment.
Modern service discovery tools allow a service with a same name to have multiple tags (or labels) which can be used to identify a released version and a deployed version of a service with the same name so that downstreams can then try to only connect to the released versions of the service.
Let us assume in this case we?re deploying a new version of service C into production.
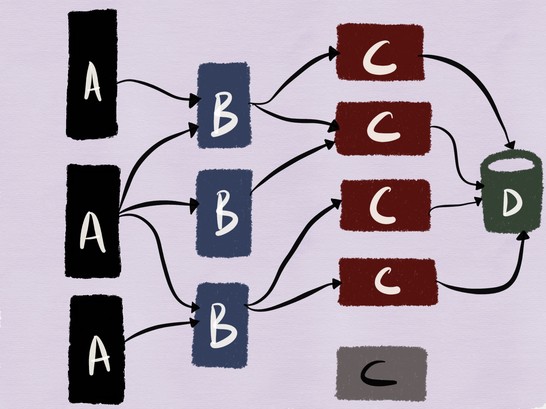
To test if the deployed version functions correctly, we need to be able to exercise it and confirm that none of the contracts it exposes are broken. The mainspring of loosely coupled services is to allow teams to develop, deploy and scale independently, and in the same spirit, it should also be possible to test independently, something I feel (paradoxically) applies to integration testing as well.
Google has a blog post on testing titled Just Say No to More End-to-End Tests, where they describe an integration test as:
An integration test takes a small group of units, often two units, and tests their behavior as a whole, verifying that they coherently work together.
If two units do not integrate properly, why write an end-to-end test when you can write a much smaller, more focused integration test that will detect the same bug? While you do need to think larger, you only need to think a little larger to verify that units work together.
It follows that integration testing in production should adhere to the same philosophy where it should be sufficient ? and perhaps beneficial ? to only test small groups of units together. If properly designed, all the upstream dependencies should be sufficiently decoupled from service under test, such that a poorly formatted request from service A should not result in a cascading failure in the architecture.
In the case of the example we?re working with, this might mean testing the deployed version of the service C and its interaction with MySQL as shown in the illustration below.
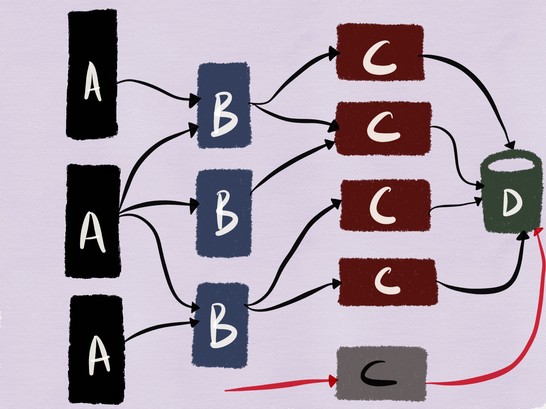
While testing reads should be mostly straightforward (unless the read traffic of the service under test ends up populating a cache leading to cache poisoning of data used by released services), testing the deployed code?s interaction with MySQL becomes more tricky when it involves non-idempotent requests that might result in modification to the data.
My personal preference is to perform integration testing against the production database. In the past I?ve maintained a whitelist of clients that were allowed to issue requests to the service under test. Certain teams maintain a dedicated set of accounts or users for tests being run against a production system, so that any concomitant change to the data is isolated to a small sample set.
If however, it is absolutely required that production data not be modified at any cost during a test run, then writes/updates need to either be:
? discarded at the application layer C or be written to a different table/collection in the database? a new entry in the database marked as one created by a test run
In the second case, if test writes need to be distinguished at the database layer, then it mandates that the schema for the database be designed upfront to support this form of testing (by having an additional field, for instance).
In the first case, discarding writes at the application layer can happen if the application is able to detect that the request is to not to be acted upon ? this could be done by inspecting the IP address of client issuing the test request or by the user ID of the incoming request or by checking for the presence of a header in the request the client is expected to set while in the test mode.
If what I?m suggesting sounds like mocking or stubbing but at a service level, then that?s not too wide off the mark. And this approach isn?t without its fair share of problems. As Facebook?s whitepaper on Kraken goes on to state:
An alternate design choice is to use shadow traffic where an incoming request is logged and replayed in a test environment. For the web server use case, most operations have side-effects that propagate deep into the system. Shadow tests must not trigger these side effects, as doing so can alter user state. Stubbing out side effects for shadow testing is not only impractical due to frequent changes in server logic, but also reduces the fidelity of the test by not stressing dependencies that would have otherwise been affected.
While greenfield projects can be designed in a manner such that such side-effects are minimized or warded off or possibly even eliminated entirely, retrofitting such stubbing into a pre-existing infrastructure can prove to be more trouble than its worth.
Service mesh architectures can help to an extent with this form of stubbing. In a service mesh architecture, services are unaware of the network topology and listen on localhost for connections. All communication between services happens through a sidecar proxy. The same architecture described above would look like the following when there?s a proxy added to every hop.
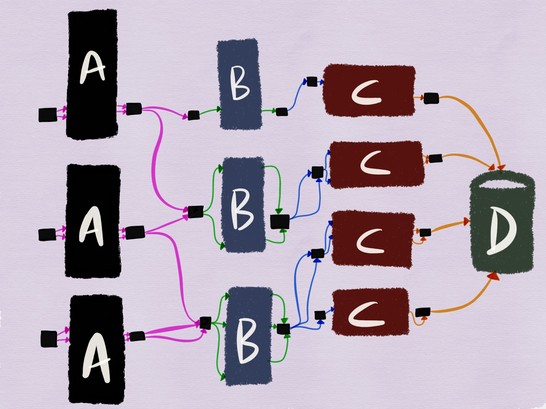
If we?re testing service B, the egress proxy of service B can be configured to inject a custom header X-ServiceB-Test for every test request, and the ingress proxy of the upstream C can:
? detect the header and send back a canned response to service B? signal to service C that the request is a test request
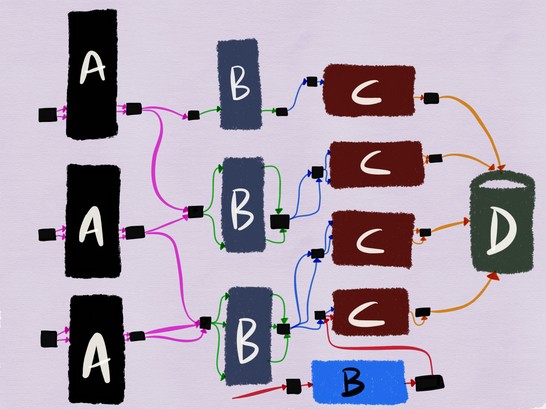 Integration test for a deployed version of service B run against a released version of service C where the writes never make it to the database
Integration test for a deployed version of service B run against a released version of service C where the writes never make it to the database
Performing integration testing in this manner also ensures that service B?s test is run against its upstreams while the upstreams are serving normal production traffic, which is likely to be a closer simulation of how the service B will behave when released to production.
It?d also be great if every service in the architecture also supported making real API calls but in a test or dummy mode, paving the way for downstreams to be tested against the latest contract exposed by the service but without incurring any modification to real data. This is tantamount to contract testing but at the network level.
Shadowing (also known as Dark Traffic Testing or Mirroring)
I find shadowing (also known as a dark launch according to a blog post from Google or in istio parlance called mirroring) to be more beneficial than integration testing in many cases.
As the Principles of Chaos Engineering puts it:
Systems behave differently depending on environment and traffic patterns. Since the behavior of utilization can change at any time, sampling real traffic is the only way to reliably capture the request path.
Shadowing is the technique by which production traffic to any given service is captured and replayed against the newly deployed version of the service. This can happen either in real time where incoming production traffic is bifurcated and routed to both the released and deployed version, or it could happen asynchronously when a copy of the previously captured production traffic is replayed against the deployed service.
When I worked at imgix (a startup with 7 engineers, only 4 of whom were systems engineers), dark traffic testing was extensively used to test changes to our image rendering infrastructure. We captured a certain percentage of all incoming requests and sent it to a Kafka cluster by shipping the HAProxy access logs to a heka pipeline which then fed the parsed request stream into Kafka. Prior to the release of any new version of our image processing software, it was tested against the captured dark traffic to ensure it correctly handled the requests. However, our image rendering stack was also largely a stateless service which lent itself especially well to this form of testing.
Certain companies prefer not to capture a percentage of traffic but to subject their new software to an entire copy of the incoming production traffic. Facebook?s McRouter (a memcached proxy) supports this form of shadowing of memcache traffic.
When testing new cache hardware, we found it extremely useful to be able to route a complete copy of production traffic from clients. McRouter supports flexible shadowing configuration. It?s possible to shadow test a different pool size (re-hashing the key space), shadow only a fraction of the key space, or vary shadowing settings dynamically at runtime.
The downside to shadowing the entire traffic against a deployed service in the production environment is that if such shadowing is done at the time of peak traffic, one might end up requiring 2X the capacity to perform such testing.
Proxies like Envoy support real time shadowing of traffic to a different cluster in a fire-and-forget manner. As per the docs:
The router is capable of shadowing traffic from one cluster to another. The current implementation is ?fire and forget,? meaning Envoy will not wait for the shadow cluster to respond before returning the response from the primary cluster. All normal statistics are collected for the shadow cluster making this feature useful for testing. During shadowing, the host/authority header is altered such that -shadow is appended. This is useful for logging. For example, cluster1 becomes cluster1-shadow.
Oftentimes however, it might not be possible or practical to maintain a replica test cluster that?s kept ?in-sync? with production (for the same reasons why trying to maintain an in-sync ?staging? cluster is problematic). Shadowing, when used to test a newly deployed service with a tangle of dependencies, can end up triggering unintended state changes to the test service?s upstreams. Shadowing a day?s worth of user sign-ups against a deployed version of the service that writes to the production database can lead to the error-rate shooting up to 100% due to to the shadow traffic being perceived as duplicate sign-ups and being rejected.
In my experience, shadowing works best for testing idempotent requests or testing stateless services with any stateful backend being stubbed out. Such form of testing then becomes more about testing load, impact and configuration. In such cases, testing of the service?s interaction with the stateful backend for non-idempotent requests can be done with the help of integration testing or in a staging environment.
Tap Compare
I first heard the word ?tap-compare? during a discussion with Matt Knox at the Testing in Production meetup this January. The only reference to the term I?ve been able to find has been in Twitter?s blog post on the topic of productionizing a high SLA service.
To verify the correctness of a new implementation of an existing system, we used a technique we call ?tap-compare.? Our tap-compare tool replays a sample of production traffic against the new system and compares the responses to the old system. Using the output of the tap-compare tool, we found and fixed bugs in our implementation without exposing end customers to the bugs.
A separate blog post from Twitter describes tap compare as:
Sending production requests to instances of a service in both production and staging environments and comparing the results for correctness and evaluating performance characteristics.
The difference between tap compare and shadowing appears to be that in the former case, the response returned by the released version is compared with the response returned by the deployed version, whereas in the latter, the request is mirrored to the deployed version in a fire-and-forget manner.
Another tool in this space is GitHub?s scientist. Scientist was built to test Ruby code but has since been ported over to a number of different languages. While useful for certain types of verification, scientist isn?t without it?s share of unsolved problems. According to a GitHub engineer on a Slack I?m a member of:
It just runs two code paths and compares the results. You?d have to be a bit careful with what those two paths are, e.g. not double the database queries you?re sending if that?d hurt things. I think that?d apply generally to anything where you?re doing something twice and comparing though, nothing specific to scientist. Scientist was built to make sure a new permissions system matched the old one and at points was running comparing things that essentially happen on every Rails request. Guess things will take longer because it does them serially, but that?s a Ruby problem, that it don?t thread.
Most of the use cases I?ve seen have been reads rather than writes, like for example scientist is used to answer questions like does the new and improved permissions query and schema get the same answer as the old one. So both are going against production (replicas). If there are side effects of what you?re wanting to test I think you?d pretty much have to do that at the application level.
Diffy is a Scala based tool open sourced by Twitter in 2015. The blog post titled Testing without Writing Tests is probably the best resource to understand how tap compare works in practice.
Diffy finds potential bugs in your service by running instances of your new and old code side by side. It behaves as a proxy and multicasts whatever requests it receives to each of the running instances. It then compares the responses, and reports any regressions that surface from these comparisons. The premise for Diffy is that if two implementations of the service return ?similar? responses for a sufficiently large and diverse set of requests, then the two implementations can be treated as equivalent and the newer implementation is regression-free. Diffy?s novel noise cancellation technique distinguishes it from other comparison-based regression analysis tools.
Tap compare is a great technique to reach for when we?re testing if two versions return similar results. According to Mark McBride:
A big use case for Diffy was in system rewrites. In our case we were splitting a Rails code base into multiple Scala services, with a broad number of API consumers using things in ways we didn?t anticipate. Things like date formatting were especially pernicious.
Tap compare is less useful for testing user engagement or testing if two versions of the service behaves similarly under peak load. As with shadowing, side-effects still remain an unsolved problem, especially if both the deployed version and the version in production are writing to the same database, and as with integration testing, limiting the tap compare tests to use a subset of accounts is one way to get around this problem.
Load Testing
For those unfamiliar with what load testing is, this article should be a great starting point. There?s no dearth of open source load testing tools and frameworks, the most popular ones being Apache Bench, Gatling, wrk2, Erlang based Tsung, Siege, Scala based Twitter?s Iago (which scrubs the logs of an HTTP server or a proxy or a network sniffer and replays it against a test instance). I?ve also heard from an acquaintance that mzbench really is the best in class for generating load, and supports a wide variety of protocols such as MySQL, Postgres, Cassandra, MongoDB, TCP etc. Netflix?s NDBench is another open source tool for load testing data stores and comes with support for most of the usual suspects.
Twitter?s official blog on Iago sheds more light on the yardsticks of a good load generator:
Non-blocking requests are generated at a specified rate, using an underlying, configurable statistical distribution (the default is to model a Poisson Process). The request rate can be varied as appropriate ? for instance to warm up caches before handling full production load.
In general the focus is on the arrival rate aspect of Little?s Law, instead of concurrent users, which is allowed to float as appropriate given service latency. This greatly enhances the ability to compare multiple test runs and protects against service regressions inducing load generator slow down.
In short, Iago strives to model a system where requests arrive independently of your service?s ability to handle them. This is as opposed to load generators which model closed systems where users will patiently handle whatever latency you give them. This distinction allows us to closely mimic failure modes that we would encounter in production.
Another form of load testing takes the form of stress testing by means of traffic shifting. An Uber SRE first mentioned this form of testing to me where all of the production traffic was directed to a cluster smaller than the one provisioned for the service, and if things didn?t look good, traffic was shifted back to a larger cluster. This technique is also used by Facebook as per one of their official blog posts:
We intentionally redirect more traffic to individual clusters or hosts, measure the resource usage on those hosts, and find the boundaries of the service. This method of testing is particularly useful for establishing the CPU needed to support the peak number of concurrent Facebook Live broadcasts.
Per an ex-LinkedIn engineer on a Slack I?m a part of:
LinkedIn also used to do production ?redline? tests by removing backends from the load balancer until load reaches certain thresholds, or errors appear.
Indeed, a bit of Googling unearthed an entire white paper and a blog post on this topic from LinkedIn:
Referred to as ?Redliner?, it uses live traffic in production environments to drive the measurement, hence avoiding many pitfalls that prevent capacity measurement from obtaining accurate values in synthetic lab environment.
Redliner works by intelligently redirecting a portion of production traffic to the SUT (Service Under Test) and realtime analyzing the performance. It has been adopted by hundreds of services inside LinkedIn and is executed for various types of capacity analysis on a daily basis.
Redliner supports running tests side-by-side for canary and production instances. This allows engineers to run the same level of traffic on two different service instances: 1) a service instance that contains new changes, that is, configurations/properties or new code, and 2) a service instance with the current production version.
The load-testing results are used as part of deployment decisions and have successfully prevented deployment of code with a potential performance regression.
Facebook takes load testing using live traffic to a completely different level with a system called Kraken and the whitepaper on Kraken is well worth a read. This is primarily achieved with the help of traffic shifting where Proxygen?s (Facebook?s load balancer) configuration is reloaded with new values (read off a distributed configuration store) for the edge and cluster weights, which determines how much live traffic will be routed to each cluster and region respectively inside a given POP (point of presence).
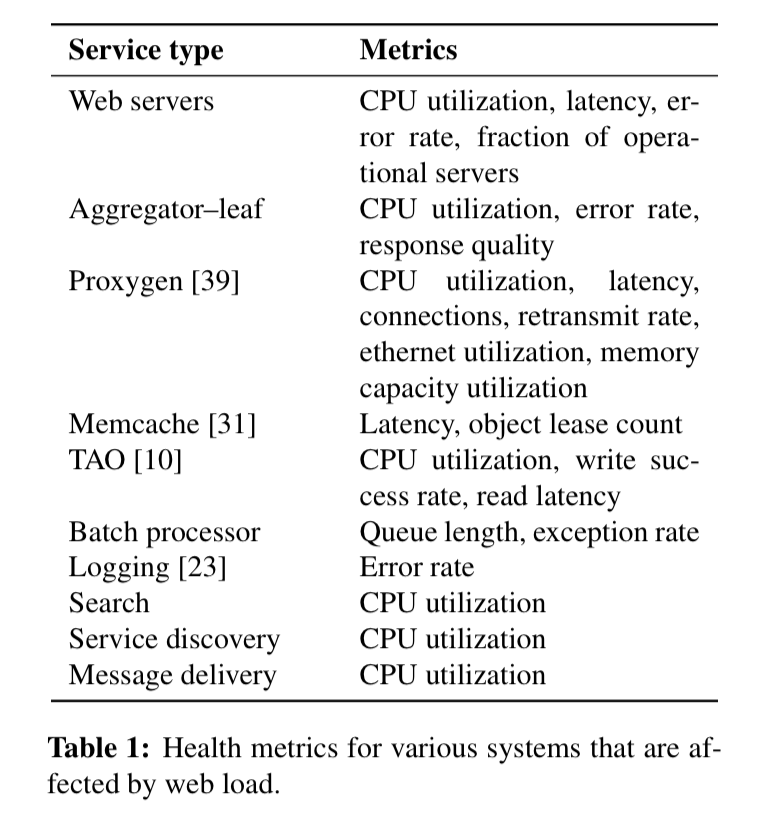 From the whitepaper on Kraken
From the whitepaper on Kraken
The monitoring system (Gorilla) reports metrics for various services (as detailed in the table above) and decisions on whether to further continue routing traffic per the weights or whether to reduce or completely abort routing traffic to a specific cluster are made based on the monitoring data reported and the threshold for these values.
Config Tests
The new wave of open source infrastructure tooling has made it not just possible but also relatively easy to capture all infrastructural changes as code. It?s also possible to varying degrees to test these changes, even if most pre-production tests for infrastructure as code only assert if the specifications and the syntax is correct.
However, not testing new configuration before the release of code has been the cause of a significant number of outages.
In order to test configuration changes holistically, it becomes important to draw the distinction between different forms of configuration. Fred Hebert, in a conversation with me, came up with the following quadrant:
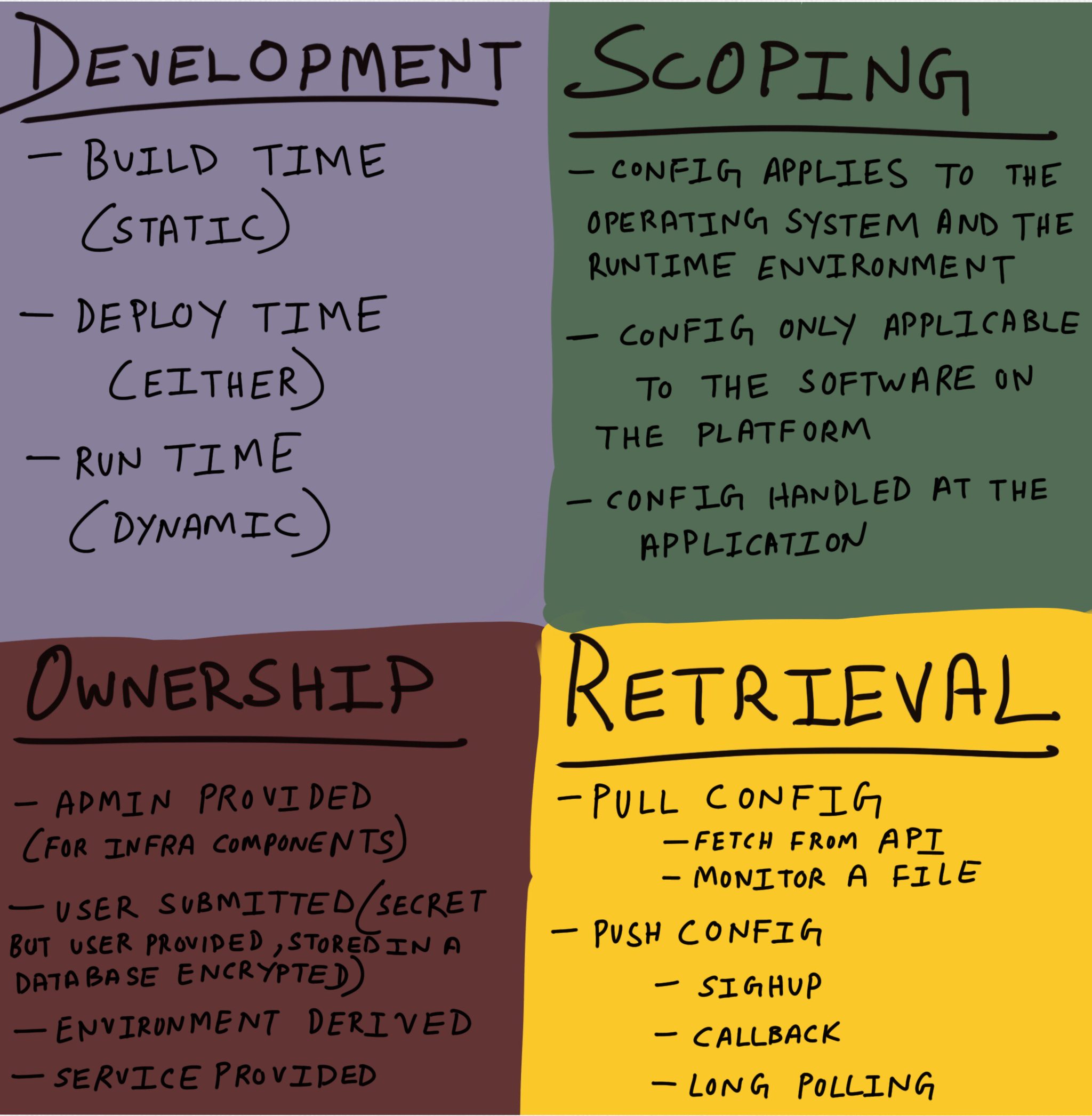
Again, this is by no means comprehensive, but having this demarcation unlocks the ability to decide how best to test each configuration and at what phase. Build time configuration makes sense if truly reproducible builds are possible. Not all configuration is static and on modern platforms dynamic configuration changes are inevitable (even when dealing with ?immutable infrastructure?).
Testing configuration changes with the same rigor as code changes is something I?ve rarely seen done. Techniques like integration testing, shadowing peak production traffic and blue-green deploys for configuration changes can greatly minimize the risk of rolling out new configurations. As Jamie Wilkinson, an SRE at Google put it:
Config pushes need to be treated with at least the same care as you do with program binaries, and I argue more because unit testing config is difficult without the compiler. You need integration tests. You need to do canaried and staged rollouts of config changes because the only good place to test your config change is in the theatre of production, in the face of the actual users exercising the code paths enabled by your config. Global synchronised config change = outage.
For this reason, deploy features disabled and release config enabling them on a separate schedule. Package up config just as you do for binaries, in a nice little hermetic, transitive closure.
An article from Facebook from a couple of years ago had some good insights into risk management for rolling out configuration changes:
Configuration systems tend to be designed to replicate changes quickly on a global scale. Rapid configuration change is a powerful tool that can let engineers quickly manage the launch of new products or adjust settings. However, rapid configuration change means rapid failure when bad configurations are deployed. We use a number of practices to prevent configuration changes from causing failure.
? Make everybody use a common configuration system.
Using a common configuration system ensures that procedures and tools apply to all types of configuration. At Facebook we have found that teams are sometimes tempted to handle configurations in a one-off way. Avoiding these temptations and managing configurations in a unified way has made the configuration system a leveraged way to make the site more reliable.
? Statically validate configuration changes. Many configuration systems allow loosely typed configuration, such as JSON structures. These types of configurations make it easy for an engineer to mistype the name of a field, use a string where an integer was required, or make other simple errors. These kinds of straightforward errors are best caught using static validation. A structured format (for example, at Facebook we use Thrift) can provide the most basic validation. It is not unreasonable, however, to write programmatic validation to validate more detailed requirements.
? Run a canary. First deploying your configuration to a small scope of your service can prevent a change from being disastrous. A canary can take multiple forms. The most obvious is an A/B test, such as launching a new configuration to only 1 percent of users. Multiple A/B tests can be run concurrently, and you can use data over time to track metrics.
For reliability purposes, however, A/B tests do not satisfy all of our needs. A change that is deployed to a small number of users, but causes implicated servers to crash or run out of memory, will obviously create impact that goes beyond the limited users in the test. A/B tests are also time consuming. Engineers often wish to push out minor changes without the use of an A/B test. For this reason, Facebook infrastructure automatically tests out new configurations on a small set of servers. For example, if we wish to deploy a new A/B test to 1 percent of users, we will first deploy the test to 1 percent of the users that hit a small number of servers (a technique called sticky canary). We monitor these servers for a short amount of time to ensure that they do not crash or have other highly visible problems. This mechanism provides a basic ?sanity check? on all changes to ensure that they do not cause widespread failure.
? Hold on to good configurations. Facebook?s configuration system is designed to retain good configurations in the face of failures when updating those configurations. Developers tend naturally to create configuration systems that will crash when they receive updated configurations that are invalid. We prefer systems that retain old configurations in these types of situations and raise alerts to the system operator that the configuration failed to update. Running with a stale configuration is generally preferable to returning errors to users.
? Make it easy to revert. Sometimes, despite all best efforts, a bad configuration is deployed. Quickly finding and reverting the change is key to resolving this type of issue. Our configuration system is backed by version control, making it easy to revert changes.
Testing in Production ? Release
Once a service has been tested after it?s deployed, it needs to be released.
It?s important here to stress that in this phase, a rollback happens only when there are hard failure modes, such as:
? a service crash looping? an upstream timing out a significant number of connections leading to a spike in error rate? a wrong config change such as a missing secret in an environment variable taking down the service (as an aside, environment variables are best avoided, but that?s a different discussion for a different blog post)
Ideally, if testing in the deploy phase was thorough, any surprises in the release phase would ideally be minimal to non-existent. However, there still exist a set of best practices to safely release new code.
Canarying
Canarying refers to a partial release of a service to production. A subset of production now consists of the canaries which are then sent a small percentage of actual production traffic after they pass a basic health check. The canary population is monitored as it serves traffic, the metrics being monitored for are compared with the non-canary metrics (the baseline), and if the canary metrics aren?t within the acceptable threshold, a rollback ensues. While canarying is a practice generally discussed in the context of releasing server-side software, canarying client-side software is increasingly common as well.
As to what traffic is directed at the canary is determined by a variety of factors. At several companies, the canaries first only get internal user traffic (also known as dogfooding). If things look good, a small percentage of production traffic is directed at the canary followed by a full rollout. Rollback of a bad canary is best automated and tools like Spinnaker come with built-in support for automated canary analysis and rollback.
Canaries aren?t without their fair share of problems and this article provides a good rundown of the trouble with canaries.
Monitoring
Monitoring is a must-have at every phase of the production rollout, but is especially important during the release phase. ?Monitoring? is best suited to report the overall health of systems. Aiming to ?monitor everything? can prove to be an anti-pattern. For monitoring to be effective, it becomes salient to be able to identify a small set of hard failure modes of a system or a core set of metrics. Examples of such failure modes are:
? an increase in the error rate? a decrease in the overall request rate to the service as a whole or a specific endpoint or worse, a complete outage? increase in latency
Any of these hard failure modes warrant an immediate rollback or rollforward of the newly released software. The one important thing to bear in mind is that monitoring at this stage doesn?t have to be elaborate and comprehensive. Some believe that the ideal number of signals to be ?monitored? is anywhere between 3?5, and certainly no more than 7?10. As Facebook?s white paper on Kraken suggests:
We accomplish this goal with a light-weight and configurable monitoring compo- nent seeded with two topline metrics, the web server?s 99th percentile response time and HTTP fatal error rate, as reliable proxies for user experience.
The set of system and application metrics to monitor during a release is best decided during system design time.
Exception Tracking
I put exception tracking under the release phase though to be fair, I think it has equal utility during the deploy phase and during the post-release phase as well. Exception trackers often don?t get the same scrutiny or hype as some of the other Observability tooling, but in my experience I?ve found exception trackers enormously useful.
Open source tools like Sentry furnish rich detail about the incoming requests, stack traces and local variables, all of which makes debugging a lot easier than plainly looking at logs. Exception tracking can also help with the triaging of issues that need fixed but don?t warrant a full rollback (such as an edge case triggering an exception).
Traffic Shaping
Traffic shaping or traffic shifting really isn?t so much a standalone form of testing than something to assist with canarying and the gradual release of the new code. In essence, traffic shifting is achieved by updating the configuration of the load balancer to gradually route more traffic to the newly released version.
Traffic shifting is also a useful technique to assist with the gradual rollout of new software separate from a normal deploy. At my previous company imgix, in June 2016 a completely new rearchitecture of our infrastructure required to be rolled out. After first testing the new infrastructure with a certain percent of dark traffic, we embarked on a production rollout by routing around 1% of production traffic to the new stack initially. This was followed by gradually scaling up traffic to the new stack (while fixing certain issues that cropped up along the way) over the course of several weeks until 100% of our production traffic was being served by the new stack.
The popularity of the service mesh architecture has led to a renewed interest in proxies, with proxies both old (nginx, HAProxy) and new (Envoy, Linkerd) releasing support for new functionality to pip each other at the post. A future with automated traffic shifting from 0 to 100% during a production release doesn?t seem very far-fetched to me.
Testing in Production ? Post-Release
Post-release testing takes the form of verification that happens once we?ve satisfactorily released code. At this stage, we?re confident that the code is largely correct, was successfully released to production and is handling production traffic as expected. The code deployed is in real use either directly or indirectly, serving real customers or doing some form of work that has some meaningful impact for the business.
The goal of any verification at this stage largely boils down to validating that the system works as intended given the different workloads and traffic patterns it might be subject to. This is best achieved by capturing a paper trail of what?s happening in production and using that for both debugging purposes as well as general understandability of the system.
Feature Flagging or Dark Launch
The oldest blog post I can find about a company successfully using feature flags dates back to almost a decade ago. There?s a website featureflags.io to serve as a comprehensive guide to all things feature flagging.
Feature flagging is a method by which developers wrap a new feature in an if/then statement to gain more control over its release. By wrapping a feature with a flag, it?s possible to isolate its effect on the system and to turn that flag on or off independent from a deployment. This effectively separates feature rollout from code deployment.
Once new code is deployed to production behind a feature flag, it can then be tested for correctness and performance as and when required in the production environment. Feature flagging is also one of the more accepted forms of testing in production, and as such is well-known and has been extensively written about. What?s perhaps less known is that feature flagging can be extended to testing database migrations or desktop software as well.
What?s probably not written about much are the best practices for developing and shipping feature flags. Feature flag explosion has been a problem at a previous company I worked at. Not being disciplined about pruning feature flags not in use after a certain period of time led us to go down the path of a massive clean-up of months (and sometimes years) old feature flags.
A/B Testing
A/B testing often falls under the experimental analysis and isn?t necessarily seen as a form of testing in production. As such it?s not only widely (sometimes controversially) used but also extensively researched and written about (including what makes good metrics for online experiments). What?s possibly less common is A/B testing being used for testing different hardware or VM configurations, but these are often referred to as ?tuning? (for example, JVM tuning) as opposed to being seen as an A/B test (even if in principle, tuning can very much be seen as a form of A/B test to be undertaken with the same level of rigor when it comes to measurement).
Logs/Events, Metrics and Tracing
Known as the ?three pillars of Observability?, logs, metrics and distributed traces are something I?ve written about extensively in the past.
Profiling
Profiling applications in production is sometimes required to diagnose performance related problems. Depending on the language and runtime support, profiling can be as easy as adding a single line of code to an application (import _ “net/http/pprof ” in the case of Go) or might require significant instrumentation to applications or by means of blackbox inspection of a running process and inspecting the output with a tool like flamegraphs.
Teeing
A lot of people perceive teeing as similar to shadowing, since in both cases production traffic is replayed against a non-production cluster or process. The difference, the way I see it, comes down to the fact that replaying production traffic for testing purposes is slightly different from replaying traffic for debugging purposes.
Etsy blogged about using teeing as a technique for verification (this use case seems similar to shadowing)
You can think of ?tee? in this sense like tee on the command line. We wrote an iRule on our F5 load balancer to clone HTTP traffic destined for one pool and send it to another. This allowed us to take production traffic that was being sent to our API cluster and also send it onto our experimental HHVM cluster, as well as an isolated PHP cluster for comparison.
This proved to be a powerful tool. It allowed us to compare performance between two different configurations on the exact same traffic profile.
However, in some cases, being able to tee production traffic against an off-line system is required for debugging purposes. In such cases, the offline system might be modified to emit more diagnostics information or be compiled differently (with the thread sanitizer, for instance) to help with troubleshooting. In such cases, teeing becomes more of a debugging tool than a verification tool.
When I worked at imgix, such forms of debugging was fairly infrequent but not unheard of, especially when it came to debugging issues with our latency sensitive applications. For instance, cited below is a post mortem of one such incident from 2015 (reproduced here with the permission of my ex-coworker Jeremy who debugged this). We were ever-so-rarely issuing a 400-level error that seemed to disappear any time we attempted to reproduce the problem. This was very infrequent (i.e. a few requests for every billion served). We?d only see a handful a day. It turned out to be impossible to reproduce reliably, so we needed to debug with production traffic to get the chance to observe it happening.
TL;DR; I switched to a library that was intended to be internal, but ended up building against a system provided library. The system version had an occasional issue that didn?t present itself until enough traffic was applied. But the real problem was a truncated header name.
Over the past 2 days I?ve been digging through an issue with an increased occurrence of incorrect 400 errors. This issue was present in a very small number of overall requests, and these are the types of issues that can often be very difficult to diagnose. These can often be the proverbial needle in a haystack: in our case this was on the order of a once in a billion problem.
The first step to finding this problem was to capture the full raw HTTP request that resulted in the incorrect response. I had implemented a unix socket endpoint on the rendering server to tee incoming traffic to a connection on the socket. The intention of this is to allow us to easily and cheaply turn on and off dark traffic for testing directly into a developer?s machine. In an effort to avoid production problems, the connection would be closed if any socket back-pressure was observed. That is, if the duplication could not keep up, it was evicted. This socket proved useful for several development conditions. In this case, though, it was used to collect all the incoming traffic for a selection of servers with the hope of capture enough incoming requests to identify a pattern resulting in erroneous 4xx errors. Using dsh and netcat I could easily capture the incoming traffic to an offline file.
Most of Wednesday afternoon was spent collecting this data. With a good number of these, I could then use netcat to replay them on a local system reconfigured to spew a massive amount of debugging information. And nothing went wrong. Next step: replay them at as high rate as possible. In this case, a while loop sending each raw request in succession. After about 2 hours, I?d finally made a hit. The logging data showed a header was missing!
I?m using a red-black to pass the headers on. These structures treat comparison as identity, which is a great quality when you have special requirements on keys: in this case, http headers are not case sensitive. My first thought was the possibility of a leaf-node problem in the library I was using. Insertion order does influence the pattern in which the underlying tree is constructed, and red-black rebalancing is pretty complicated, so while unlikely it?s not impossible. So I swapped to a different red-black tree implementation. A fix had been made to it a few years back, so I opted to embed directly in our source with the intention of providing the exact version I wanted. However, the build picked up the wrong version, and with a reliance on the on the newer version, I was now triggering some incorrect behavior.
That was causing the rendering system to issue 500s resulting in the machine getting cycled out. This is why it was building over time. After a few were getting cycled, their traffic was re-routed which increased the problem surface for that server. So my assumption that the library was at fault was unfounded, and switching that back out addressed the 500s.
Back to the 400 error fix, I still had the problem of an error that took ~2 hours to surface. The library change obviously didn?t fix the problem, but I felt reasonably confident that the library I had chosen would be solid, and without realizing the library selection was incorrect, I wasn?t concerned about the choice to stick with it. After digging in more detail, I realized the correct value was being stored in a single character header (i.e. ?h: 12345?). It finally clicked that the ?h? was the tail end of the Content-Length header. Looking back through I found that I had an empty header for ?Content-Lengt?.
It all ended up being an off-by-one error when reading off the headers. Basically, the nginx/joyent http parser will issue partial data, and any time the partial header field was one character short, I?d send down the header with no value, and I?d subsequently receive an single character header field with the correct value. This is pretty rare combination, which is why it took so long to trigger. So, I threw in some extra logging any time I had a single character header, applied a proposed fix, and ran the script for a few hours with success!
Of course there was a possible snake in the grass with the mentioned library problem, but both issues are now resolved.
Engineers working on latency sensitive applications need to be comfortable degugging using captured live traffic, since these are often bugs that cannot be reproduced by a unit test or even surfaced by any Observability tool (especially when logging is latency-prohibitive).
Chaos Engineering
Chaos Engineering is the discipline of experimenting on a distributed system in order to build confidence in the system?s capability to withstand turbulent conditions in production.
Chaos Engineering, first popularized by Netflix?s Chaos Monkey, is now a discipline in its own right. The term ?chaos engineering? might be new, but fault injection testing has been around for a long time.
Chaos testing refers to techniques such as:
? killing random nodes to see if the system is resilient to node failure? injecting error conditions (such as latency) to verify their proper handling? forcing a misbehaving network to see how the service reacts
The vast majority of organizations lack the operational sophistication to be able to embark on chaos testing. It?s important to state that the injection of faults in a system is best undertaken once a baseline of resilience is established. This whitepaper by Gremlin (no affiliation) should provide a good primer on chaos testing as well as guidelines on how to get started.
Critical to chaos engineering is that it is treated as a scientific discipline. It uses precise engineering processes to work.
The goal of chaos engineering is to teach you something new about your systems? vulnerabilities by performing experiments on them. You seek to identify hidden problems that could arise in production prior to them causing an outage. Only then will you be able to address systemic weaknesses and make your systems fault- tolerant.
Conclusion
The goal of testing in production isn?t to completely eliminate all manner of system failures. To quote John Allspaw:
While any increase in confidence in the system?s resiliency is positive, it?s still just that: an increase, not a completion of perfect confidence. Any complex system can (and will) fail in surprising ways.
Testing in production might seem pretty daunting at first, way above the pay grade of most engineering organizations. While it?s not easy or entirely risk-free, undertaken meticulously, it can greatly help build confidence in the reliability of the sort of complex distributed systems that are becoming increasingly more ubiquitous in this day and age.


{kind=link}
{kind=link}