
Understanding the significant new features of Python 3
 Photo by Hannes Wolf on Unsplash
Photo by Hannes Wolf on Unsplash
Arguably the most significant new features introduced in Python 3 are the new implementation of str as Unicode by default and the strict separation between text and binary data.
Both of them are wholeheartedly welcome changes. The Unicode-by-default decision, especially, helped remove a lot of hassles in our daily work as developers (who said UnicodeError?). Nevertheless, there is still some confusion about this change, so let?s try and shed some light on this whole new thing.
A Little Bit of History
TL;DR Computers convert characters into numbers according to a universally recognised mapping called Unicode. Unicode is a superset of an older but still actual mapping called ASCII. These numbers are saved in memory and into files according to many different standards called encodings. The most popular and of these encodings is UTF-8.
There are plenty of interesting articles on the Internet about the rationale behind ASCII and Unicode, and you may want to check them out if you want to go deeper into the whole story. Let?s do quick overview to better understand current problems.
In the old days, saving text on a computer was as easy as converting each character into a number ranging from 0 to 127, that is seven bits of space. That was enough to store all the numbers, letters, punctuation marks and control characters the average English writer needed. This mapping was an agreed standard called the ASCII table.
Most of the computers at the time were using eight bits for a byte, meaning some extra spare space was available for an additional set of 128 more characters. Problem is, this range of the spectrum above Standard ASCII was quite free, so different organizations started using it for different purposes. This ended up as a huge mess of different characters tables where the same numbers represented different letters in different alphabets. Text documents sharing became a mess, not to mention Asian alphabets with thousands of letters, which couldn?t fit into this 256 symbols space at all.
That?s where Unicode came to help. A monumental effort started to map each and every character and symbol known to mankind into a set of so-called codepoints, that is, a hexadecimal number representing that symbol. So the Unicode consortium decided that the English letter ?Q? was U+0055, the Latin letter ?? was U+00E8, the Cyrillic letter ??? was U+0439, the math symbol ??? was U+221A, and so on. You can even find a glyph for a Pile of Poo. For compatibility reason, the first 128 numbers map the very same characters as ASCII does.
Now, since we have all agreed on assigning a unique number to each and every glyph ever conceived, and given that there are thousands upon thousands of such symbols mapped, how do we store those code points in computers? Big endian or little endian? How many bytes per codepoint? Two bytes and maybe shorting on space? Four bytes and maybe wasting some? A variable number of bytes?
Long story short, different encodings were invented to convert code points into bytes, but one among them is arguably the best and most used: UTF-8. This is the current gold standard of Unicode encoding. Unless you know what you are doing, chances are you don?t want to use anything else.
There is no string without encoding
If you followed the discussion so far, you probably already picked up on a crucial point about saving and reading text on a computer:
Having a string without knowing its encoding makes no sense at all.
You simply can?t interpret and decode a string unless you know its encoding. And, although we already decided that UTF-8 is the gold standard of Unicode decoding, you might meet other encodings in your work as a programmer and will need to act accordingly.
If you have ever found weird characters in the body of an email or on a website, that?s because that email or web page didn?t declare an encoding, so your mail client or browser are trying to guess an encoding and failing at that.
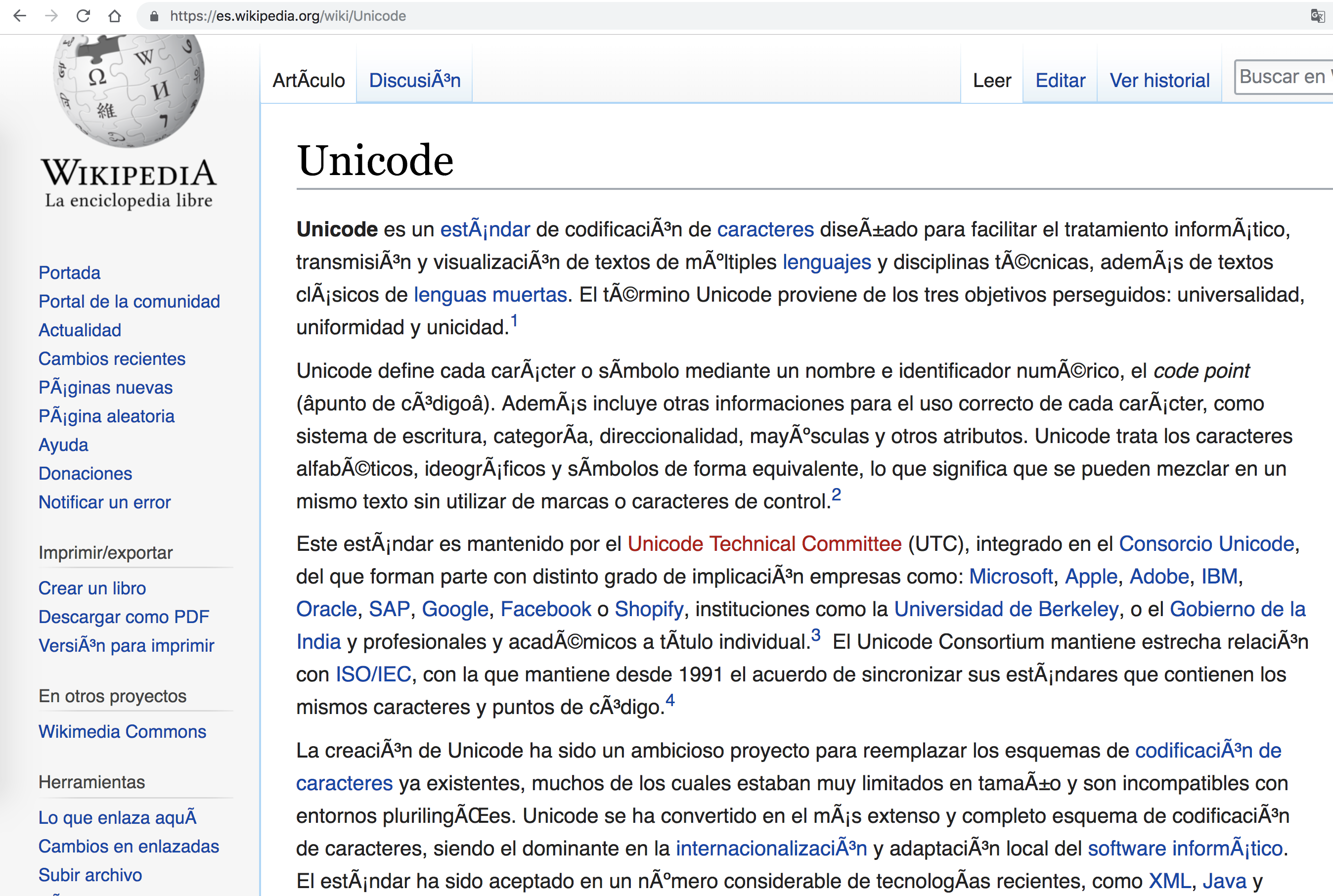 The Spanish Wikipedia page about Unicode loaded by Google Chrome with a purposely wrong encoding. Notice how accented characters are badly decoded and rendered as Chrome is trying to decode codepoints above 127 in a wrong way.
The Spanish Wikipedia page about Unicode loaded by Google Chrome with a purposely wrong encoding. Notice how accented characters are badly decoded and rendered as Chrome is trying to decode codepoints above 127 in a wrong way.
So, What About Unicode on Python 3?
Strings were quite a mess in Python 2. The default type for strings was str, but it was stored as bytes. If you needed to save Unicode strings in Python 2, you had to use a different type called unicode, usually prepending a u to the string itself upon creation. This mixture of bytes and unicode in Python 2 was even more painful, as Python allowed for coercion and implicit cast when mixing different types. That was easily doable, and it was apparently great, but most of the time it just caused headaches at runtime.
This all has gone for good with Python 3. We have two different and strictly separated types here:
- str corresponds to the former unicode type on Python 2. It is represented internally as a sequence of Unicode codepoints. You can declare a str variable without prepending the string with u, because it is default now.
- bytes roughly corresponds to the former str type (for the bytes part) on Python 2. It is a binary serialization format represented by a sequence of 8-bits integers that is fit for storing data on the filesystem or sending it across the Internet. That is why you can only create bytes containing ASCII literal characters. To define a bytes variable, just prepend a b to the string.
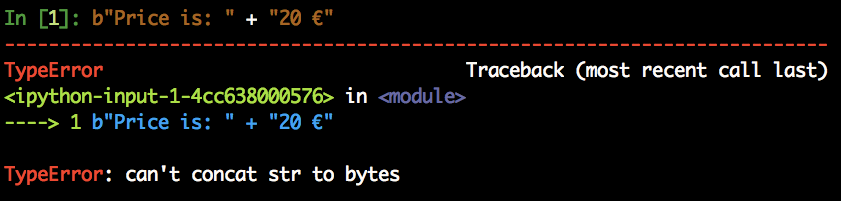
str and bytes have a completely different set of methods. You just can?t concatenate or mix them in any way:
You are forced to keep things straight, and that?s a really good thing. In Python 3, code fails immediately if you are doing things badly, and that saves a lot of debugging sessions later on. Nevertheless, there is a close relationship between str and bytes, so Python allows you to switch type with two dedicated methods:
- str can be encoded into bytes using the encode() method.
- bytes can be decoded to str using the decode() method.
Both methods accept a parameter, which is the encoding used to encode or decode. The default for both is UTF-8.
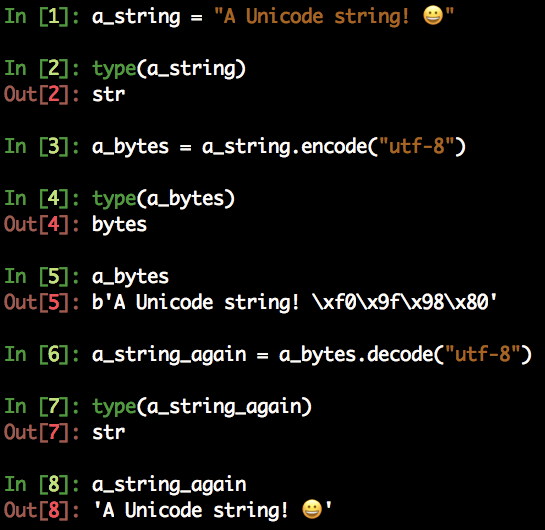 Notice how bytes strings are prepended with a b when printed on the Python interpreter
Notice how bytes strings are prepended with a b when printed on the Python interpreter
A picture is worth a thousand words, so:
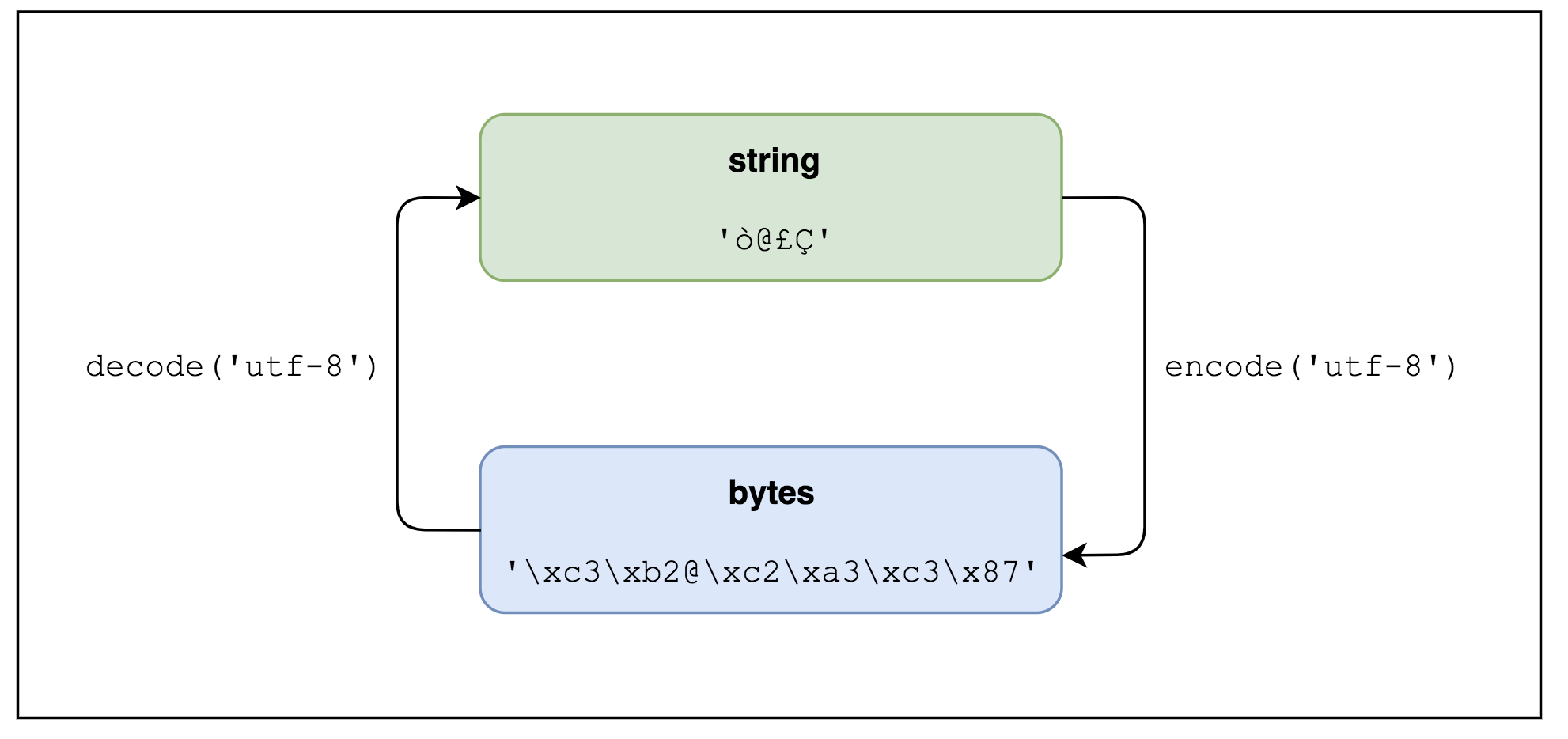
The bytes type has no inherent encoding, so you must know the encoding if you want to try and decode it, as we saw a few paragraphs above. Again: you can?t pretend to decode something unless you know its encoding.
Further, there is no way to infer what encoding a bytes has. This is something you must take into account when working with data coming to you from the Internet, or from a file you didn?t create. Indeed, weird things happen when you decode a bytes with an encoding which is different from the one you used to encode from str, just like we saw with the Spanish Wikipedia page:
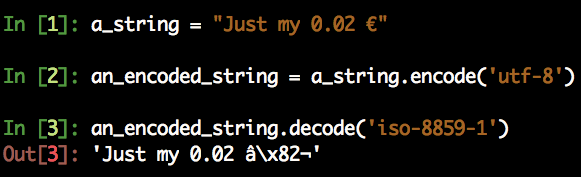 The ? symbol encoded in UTF-8 is wrongly converted back if you decode with a different encoding
The ? symbol encoded in UTF-8 is wrongly converted back if you decode with a different encoding
Accessing Files on Python 3
As you might imagine, this has huge consequences on the process of writing and reading files (or other forms of input) on Python 3.
In Python 3, reading files in r mode means decoding the data into Unicode and getting a str object. Reading files in rb mode means reading the data as is, with no implicit decoding, and saving it as bytes.
For this very same reason, the open() method interface has changed since Python 2, and it now accepts an encoding parameter. If you read along carefully, you already understand that this parameter is only worthwhile when using the r mode, where Python decodes the data into Unicode, and that it is useless in rb.
It is important to understand that Python does not try to guess the encoding. Rather it uses the encoding returned from locale.getpreferredencoding(). If you don?t pass a parameter and just rely on the default and find weird things, chances are that that method is returning the wrong encoding for your data. Again: no encoding, no party.
Best Practices and Fixing Problems With Unicode on Python3
The Unicode Sandwich
The great Ned Batchhelder delivered a great talk/article I wholeheartedly recommend if you frequently need to work with strings in Python 3. In this talk, he coined the term Unicode Sandwich to name an excellent practice when dealing with text strings in Python. Using his own words, the suggested approach is:
?Bytes on the outside, unicode on the inside, encode/decode at the edges.?
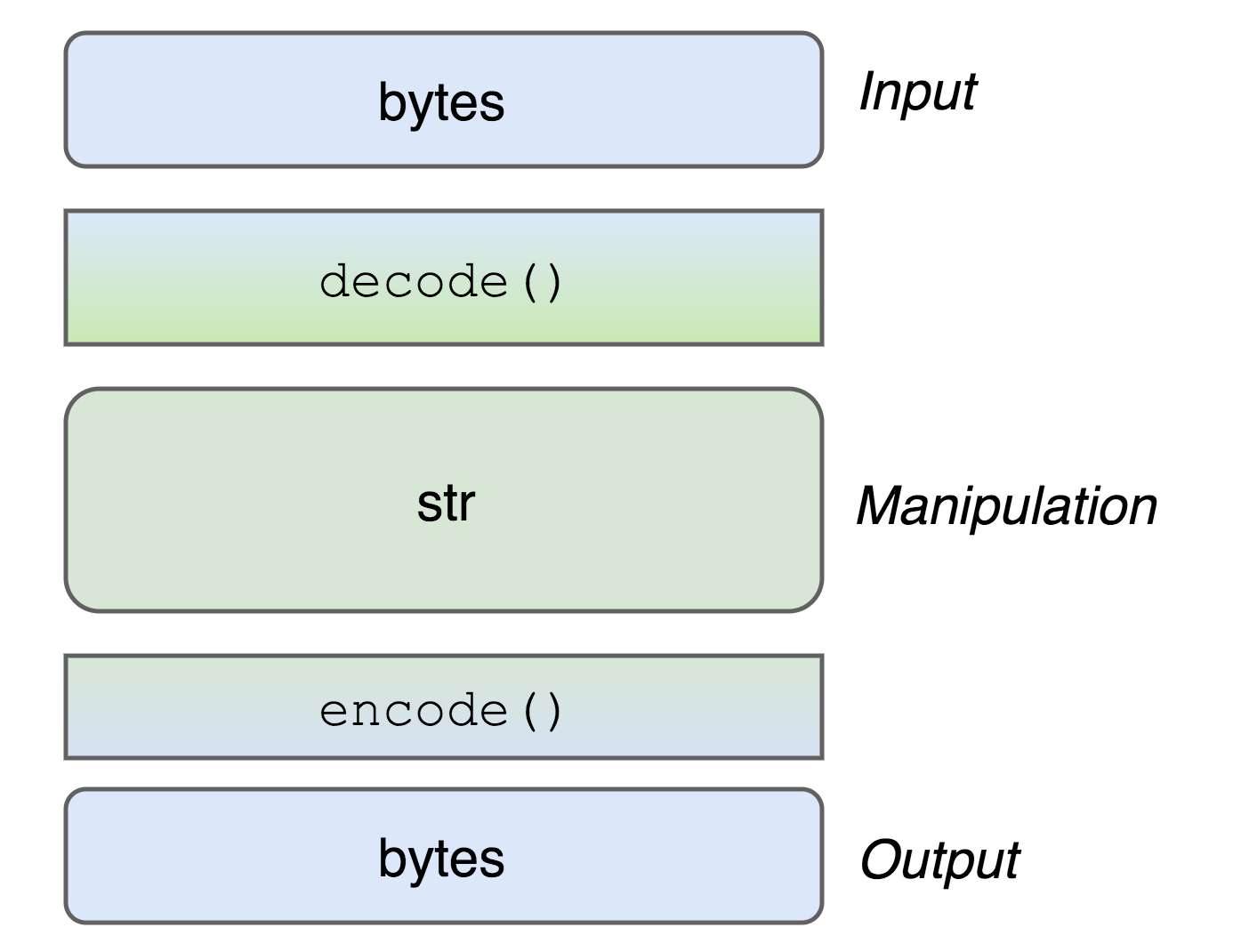
The idea is to use a str object when processing text, thus getting access to the wide range of methods Python makes available for strings processing. But, when you are dealing with external stuff like an API, go for bytes. This approach is so excellent that some libraries might even abstract the whole process from you and allow to input/output Unicode, converting it all into str internally.
2 * 3 = six
There is a large codebase of Python 2 programs yet, and some libraries still support both Py2 and Py3 in a different way, even in the very same version.
Benjamin Peterson developed an excellent compatibility library called six that provides functions to wrap differences between the two major Python versions. As you might imagine, it has plenty of stuff for strings management too. You may want to check it out and see how it can help you develop cross-compatible code.
Don?t mix str and bytes
Most of the errors that arise when dealing with strings are caused by trying to mix str and bytes. This is probably more typical if you matured your Python experience in the 2.x world, where the boundaries between the two types are way more blurred. If you still get errors like:
TypeError: a bytes-like object is required, not ‘str’
and the like, check that you are using the right method on the right object. Also, check that you opened your file properly according to your needs. It?s easy to fail a containment test that worked for years on Python 2:
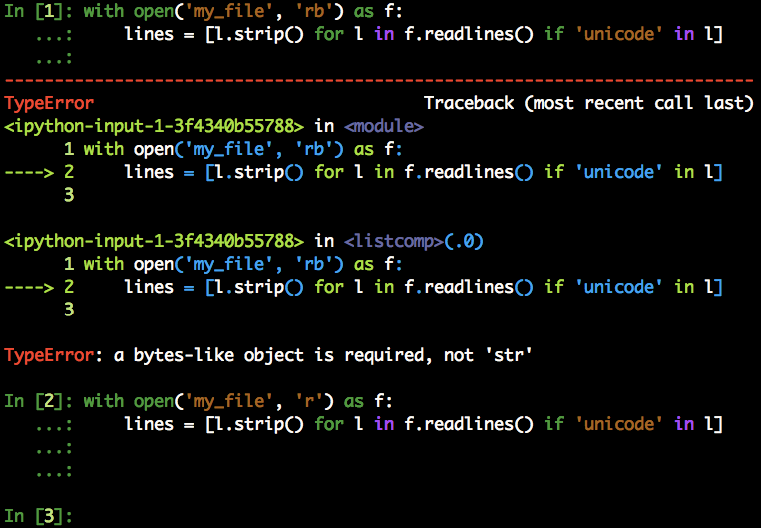
The if <string> in <object> condition on line one fails because we opened the file in binary mode and then asked Python to confront a string with a bytes object. Opening the file in read mode, or even decoding the bytes to str, would work fine.
Know your encoding
Let me stress this concept again: you can?t pretend to decode bytes if you don?t know the encoding. This information can?t be reliably inferred from the bytes itself, and you need to get or share it if you are doing I/O with files or APIs you don?t control. As we have seen before, chances are Python will decode your bytes anyway if you pass it the wrong encoding, but you will likely get garbage.
Bonus Paragraph: io.stringIO and io.bytesIO
Closely related to the major changes about strings we have just seen is another change involving the former Python2 StringIO and cStringIO modules.
Apart from small differences in APIs and performance between the two modules, StringIO and cStringIO were based on Py2?s approach to string management, accepting either Unicode or bytes string. As Py3 has a radically different approach, these two modules have been deleted and replaced by two new classes inside the io module. Their usage is quite simple:
- io.BytesIO() accepts a bytes string as an argument.
- io.StringIO() accepts a Unicode string and an encoding as arguments.
Simple as that. They return two file-like objects you can use as usual and according to the sandwich model. You can read more about the two in the official documentation.

{kind=link}
{kind=link}