
Achieving Performance and Simplicity in the Cloud for ORC Data Loads and Tableau Visualization
by Ed Fron, Enterprise Architect

Why the Need to Rethink?
After spending significant time recently in sizing, balancing, and tuning an on-premise data warehouse environment, performance just wasn?t where it needed to be for Tableau workbooks meant to analyze consumer device hardware data.
A maximum of 13 concurrent users could be handled at peak times. Simple queries could take as long as 5 minutes to execute with complex queries escalating to 30 minutes. Data loads were occurring only every 24 hours, but hourly loads were required. To top things off, a geographically dispersed user base across the US, Europe, and Asia wasn?t helping matters at all.
Was it time to look at replacing this data warehouse environment?
Waiting days or even weeks to analyze critical data for decision making is no longer acceptable. Most business teams want real-time insights that match the fast pace business and markets, and data scientists can become frustrated by the limitations placed on queries and an ability to load, transform and integrate both structured and semi-structured data.
You Have to Consider the Cloud
Hang on a minute ? it?s no small task to research and conduct a comprehensive assessment of all the data warehouse options out there. Where do you start? How do you select a solution that can outpace the existing platform or other traditional data warehousing solutions based on performance, scalability, elasticity, flexibility and affordability?
A key factor driving the evolution of modern data warehousing is the cloud. The cloud creates access to:
- Near infinite, low-cost storage
- As needed scale up / scale down capability
- Outsourcing the challenging operations tasks of data warehousing management and security to the cloud vendor
- Potential to pay for only the storage and computing resources actually used, when you use them
Having worked numerous times over the years with everything from Hadoop to Teradata as well as having been deeply involved on migration projects moving workloads from on premise environments to the cloud, I must say I was super-excited for the opportunity to explore the options to architect and deploy this particular data warehouse.
Rather than letting the features of an existing DW solution set limits on evaluating a new solution, I focused on an approach to explore the possibilities that are available across the spectrum of cloud data warehousing today.
Selecting Snowflake Cloud Data Warehouse
For this particular implementation, the existing data ingestion process was stable and mature. Daily, an ETL script loads the raw JSON file from the file system and inserts the file?s contents into a SQL table which is stored in ORC format with snappy compression.
In order to avoid reimplementing the ETL process, the first constraint was the cloud data warehouse needed to support the ORC file format. The second major constraint was to maintain backward compatibility with the existing Tableau workbooks.
Given the constraints, there are two cloud data warehouses that support ORC file format ? Snowflake and Amazon Redshift Spectrum. Both Snowflake and Redshift Spectrum allow queries on ORC files as external files located in Amazon S3. However, Snowflake edged out Redshift Spectrum for its ability to also load and transform ORC data files directly into Snowflake.
Meeting the Tableau constraint was a wash as Tableau can connect to a variety of data sources and data warehouses including Snowflake and Redshift Spectrum.
One bonus for shorter term POCs ? Snowflake (which runs in AWS today, but we expect it will run in other cloud providers soon) offers a $400 credit for 30 days that can be used for compute and storage.
As an update to this article, Snowflake is now available on Microsoft Azure as of June 2018 ? for more information, please see Bob Muglia?s blog post here.
Snowflake Architecture
Snowflake is a cloud data warehouse built on top of the Amazon Web Services (AWS) cloud infrastructure and is a true SaaS offering. There is no hardware (virtual or physical) for you to select, install, configure, or manage. There is no software for you to install, configure, or manage. All ongoing maintenance, management, and tuning is handled by Snowflake.
Architecturally there are 3 main components that make up the Snowflake data warehouse.
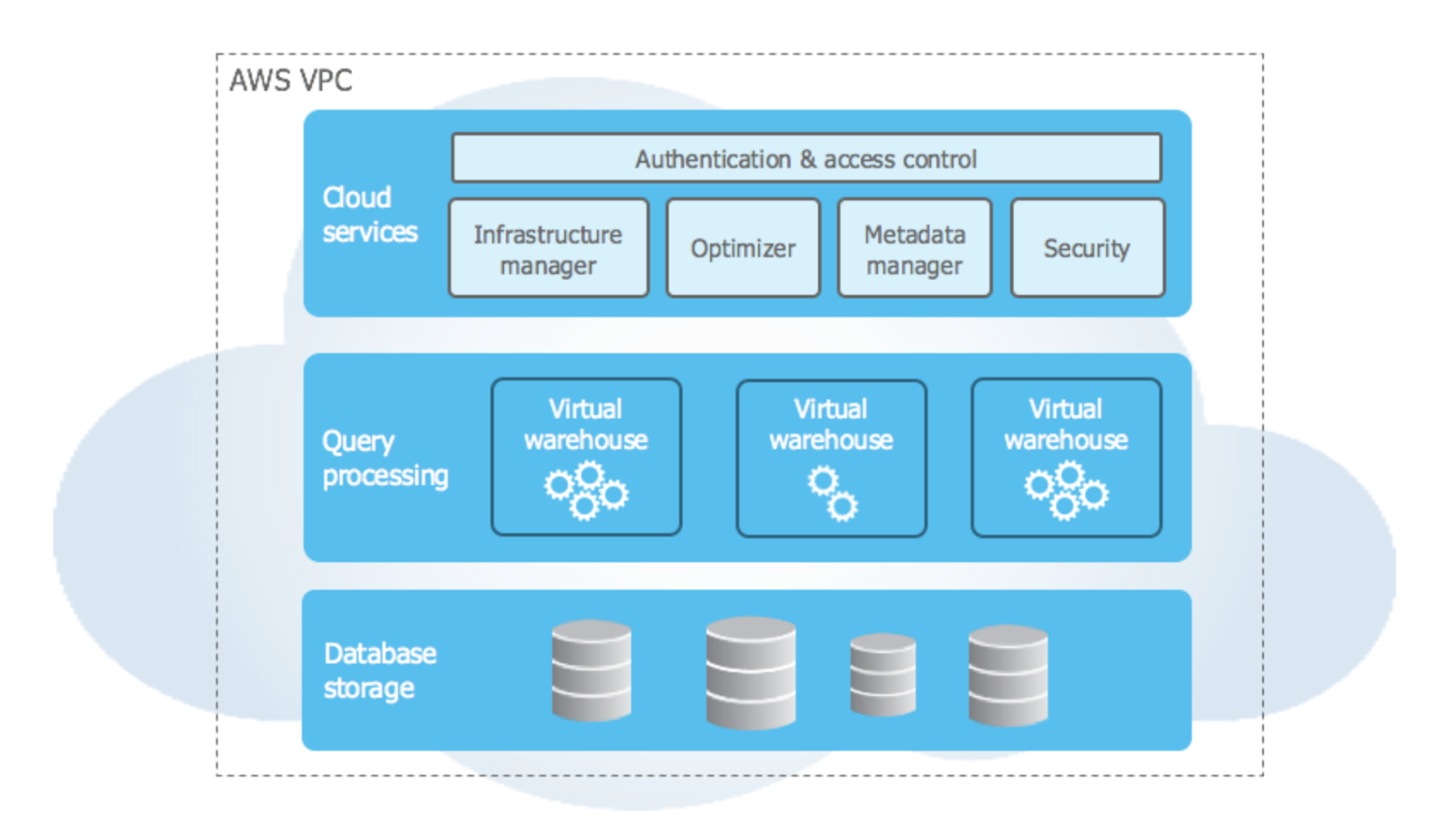
The 3 main components are:
- Database Storage ? The actual underlying file system in Snowflake is backed by S3 in Snowflake?s account, all data is encrypted, compressed, and distributed to optimize performance. In Amazon S3 the data is geo-redundant and provides excellent data durability and availability.
- Query Processing ? Snowflake provides the ability to create ?Virtual Warehouses? which are basically compute clusters in EC2 that are provisioned behind the scenes. Virtual Warehouses can be used to load data or run queries and are capable of doing both of these tasks concurrently. These Virtual Warehouses can be scaled up or down on demand and can be paused when not in use to reduce the spend on compute.
- Cloud Services ? Coordinates and handles all other services in Snowflake including sessions, authentication, SQL compilation, encryption, etc.
By design, each one of these 3 layers can be independently scaled and are redundant. If you interested in detailed information about the underlying architecture visit Snowflake?s documentation here.
Connecting to Snowflake
Snowflake makes connecting to databases very easy and provides a few different methods to do so. One method is to use any of the supported ODBC drivers for Snowflake. Additionally, SnowSQL CLI (install instructions are found here) can be leveraged or use the web based worksheet within your Snowflake account.
For the project that I worked on, I started using the web based worksheet but quickly installed the SnowSQL CLI on my machine to use a full featured IDE with version control ? a UI that I am more accustomed to for development.
Setting Up A Virtual Warehouse
Snowflake defines a virtual warehouse as a cluster of compute resources. This warehouse provides all the required resources, such as CPU, memory, and temporary storage, to perform operations in a Snowflake session.
The first step after logging into a Snowflake account is to create a virtual warehouse. I created two warehouses, the first for ETL and the second for queries.
To create a warehouse, execute the following CREATE WAREHOUSE commands into SnowSQL CLI or the web based worksheet:
CREATE WAREHOUSE ETL_WHWITH WAREHOUSE_SIZE = ‘SMALL’WAREHOUSE_TYPE = ‘STANDARD’AUTO_SUSPEND = 600AUTO_RESUME = TRUE;CREATE WAREHOUSE QUERY_WHWITH WAREHOUSE_SIZE = ‘MEDIUM’WAREHOUSE_TYPE = ‘STANDARD’AUTO_SUSPEND = 600AUTO_RESUME = TRUE;
In the code above I set different WAREHOUSE_SIZE for each warehouse but set both to AUTO_SUSPEND and AUTO_RESUME to help save on some of my $400 free credits. For more detailed information about virtual warehouses, visit Snowflake?s documentation here.
Databases, Tables and Views within Snowflake
All data in Snowflake is maintained in databases. Each database consists of one or more schemas, which are logical groupings of database objects, such as tables and views. Snowflake does not place any hard limits on the number of databases, schemas (within a database), or objects (within a schema) that you can create.
Snowflake Databases
As we go through creating a database, keep in mind that our working project constraints were as follows:
- Load the past 6 months of existing ORC data into the cloud data warehouse
- Maintain backward compatibility with the existing Tableau workbooks
Snowflake provides two options that will impact data model design decisions needed to help meet the first constraint of loading ORC data into Snowflake.
The first option is that Snowflake reads ORC data into a single VARIANT column table. This allows querying the data in VARIANT column just as you would JSON data, using similar commands and functions.
The second option allows extraction of selected columns from a staged ORC file into separate table columns using a CREATE TABLE AS SELECT statement. I decided to explore both options and create two databases for each approach.
Execute the following command to create two databases:
CREATE DATABASE MULTI_COLUMN_DB;CREATE DATABASE SINGLE_VARIANT_DB;
The MULTI_COLUMN_DB database will be used for to create the tables with multiple columns.
The SINGLE_VARIANT_DB database will be used to store the tables with a single variant column.
Execute the following command to create a new schema in the specified database:
CREATE SCHEMA “MULTI_COLUMN_DB”.POC;CREATE SCHEMA “SINGLE_VARIANT_DB”.POC;
Multiple Column Tables
The multiple column table specifies the same columns and types as the existing DW schema.
Execute the following command to create a table with a multiple column:
CREATE TABLE “MULTI_COLUMN_DB”.”POC”.DEVICEINFO (id string,manufacturer string,serialNumber string,etimestamp timestamp,model string,accuracy int,batch_id bigint,event_date date)cluster by (event_date);
To best utilize Snowflake tables, particularly large tables, it is helpful to have an understanding of the physical structure behind the logical structure. Refer to the Snowflake documentation Understanding Snowflake Table Structures for complete details on micro-partitions and data clustering.
Single Variant Column Tables
Execute the following command to create a table with a single variant column:
CREATE TABLE ?SINGLE_VARIANT_DB?.?POC?.DEVICEINFO_VAR (V VARIANT);
Views
A view is required to meet the constraint of providing backward compatibility with the existing queries to access the single variant tables.
Execute CREATE VIEW to create a view:
CREATE “SINGLE_VARIANT_DB”.”POC?.VIEW DEVICEINFO asSELECT$1:_col0::string as id,$1:_col1::string as manufacturer,$1:_col2::string as serialNumber ,$1:_col3::timestamp as etimestamp ,$1:_col4::string as model ,$1:_col5::number as accuraccy,$1:_col6::number as batch_id ,$1:_col4::date as event_date,FROM DEVICEINFO_VAR;
Loading Data
Now that the database and table have been created, it?s time to load the 6 months of ORC data. Snowflake assumes that the ORC files have already been staged in an S3 bucket. I used the AWS upload interface/utilities to stage the 6 months of ORC data which ended up being 1.6 million ORC files and 233GB in size.
So the ORC data has been copied into an S3 bucket ? the next step is to set up our external stage in Snowflake.
Create Stage Object
When setting up a stage you have a few choices including loading the data locally, using a Snowflake staging storage, or providing info from you own S3 bucket. I have chosen that latter as this will provide long term retention of data for future needs.
Execute CREATE STAGE to create a named external stage. An external stage references data files stored in a S3 bucket. In this case, we are creating a stage that references the ORC data files. The following command creates an external stage named ORC_SNOWFLAKE:
CREATE STAGE MULTI_COLUMN_DB”.”POC”.ORC_SNOWFLAKEURL = ‘s3://ntgr-snowflake’CREDENTIALS = (AWS_KEY_ID = ‘xxxxxx’ AWS_SECRET_KEY = ‘******’);
You will need to provide the S3 URL as well as AWS API keys. Once you?ve done this, your stage will show up in Snowflake.
Create File Format Objects
A named file format object provides a convenient means to store all of the format information required for loading data from files into tables.
Execute CREATE FILE FORMAT to create a file format
CREATE FILE FORMAT “MULTI_COLUMN_DB”.”POC”.ORC_AUTOTYPE = ‘ORC’COMPRESSION = ‘AUTO’;
Copy Data Into the Target Table
Execute COPY INTO table to load your staged data into the target table. Below is a code sample for both a Multiple Column Table and a Single Variant Column Table.
Multiple Column Table
copy into “MULTI_COLUMN_DB”.”POC”.DEVICEINFO FROM(SELECT$1:_col0::string, –id string$1:_col1::string, –manufacturer string$1:_col2::string, –serialnumber string$1:_col3:: timestamp, –etimestamp string$1:_col4:: string, –model string$1:_col5:: number, –accuraccy string$1:_col6::number, –batch_id bigintdate_trunc(‘DAY’,$1:_col3::timestamp) –event_date datefrom @ORC_SNOWFLAKE/tblorc_deviceinfo(FILE_FORMAT=>ORC_AUTO) ON_ERROR = ‘continue’);
Single Variant Column Table
COPY INTO “SINGLE_VARIANT_DB”.”POC?.DEVICEINFO_VARfrom @ORC_SNOWFLAKE/tblorc_deviceinfoFILE_FORMAT = ORC_AUTOON_ERROR = ‘continue’;
The previous examples include the ON_ERROR = ?continue? parameter value. If the command encounters a data error on any of the records, it continues to run the command. If an ON_ERROR value is not specified, the default is ON_ERROR = ?abort_statement?, which aborts the COPY command on the first error encountered on any of the records in a file.
NOTE: At the time this post was published, there is a known issue with the execution of the ON_ERROR = ?continue? statement when accessing external files on S3 and the default value ?abort_statement? is run. A bug has been submitted to Snowflake and a fix is pending.
Verify the Loaded Data
Execute a SELECT query to verify that the data was loaded successfully.
select * from “MULTI_COLUMN_DB”.”POC”.DEVICEINFO;select * from “SINGLE_VARIANT_DB”.”POC”.DEVICEINFO;
Tableau Workbook Results
Once the the data was all loaded, I started Tableau and created a connection to Snowflake, and then set data source to point to the correct Snowflake database, schemas, and tables.
Next, I was ready run some sanity tests. I identified 8 existing queries and then made 5 runs of each query/Tableau dashboard and captured the times using the Snowflake history web page.
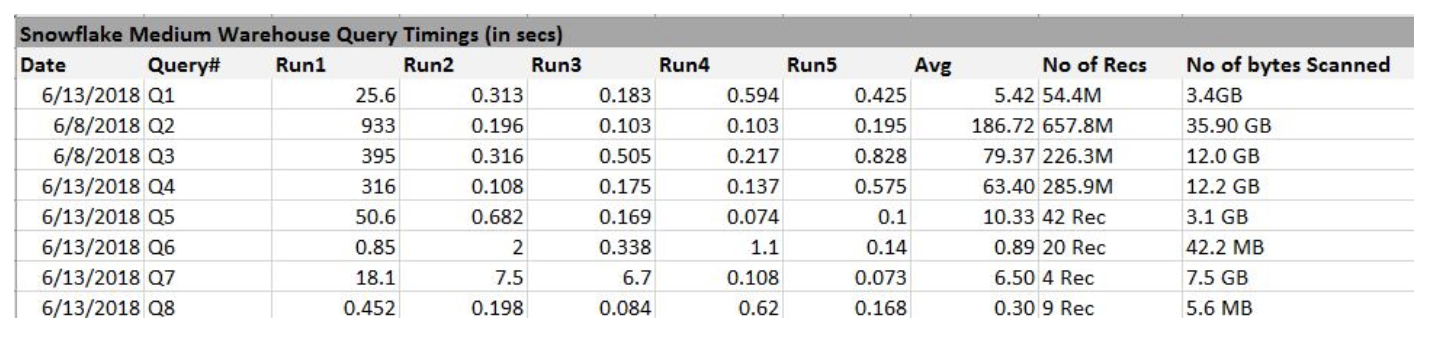
The Snowflake environment is now ready for Tableau side-by-side testing. For side-by-side testing, end users will compare the performance of the Tableau datasource configured to connect to the existing data warehouse against another Tableau datasource configured to connect to the new Snowflake Cloud Data Warehouse.
Establishing a Baseline
To establish a baseline for the query performance benchmarks, I?m using a medium sized warehouse for the first round of testing. It will be interesting to see how the initial query benchmarks compare to the current DW using that size. I expect the results to be similar.
But this is where the fun begins!
I can then quickly experiment with the different types of queries and different Snowflake warehouse sizes to determine the combinations that best meet the end user queries and workload. Snowflake claims linear performance improvements as you increase the warehouse size, particularly for larger, more complex queries.
So when increasing our warehouse from medium to large, I would expect Run 1 times cut in half for the larger, more complex queries. It also helps to reduce the queuing that occurs if a warehouse does not have enough servers to process all the queries that are submitted.
Concurrency with Snowflake
In terms of concurrency testing for a warehouse, resizing alone will not address concurrency issues. For that, Snowflake?s multi-cluster warehouses are designed specifically for handling queuing and performance issues related to large numbers of concurrent users and/or queries.
Again, for the initial round of testing, multi-cluster warehouses will not be used to establish a baseline. To address any concurrency issues, I will configure the warehouse for multi-cluster and specify it to run in auto-scale mode, effectively enabling Snowflake to automatically start and stop clusters as needed.
Snowflake?s Unique Advantages
Working on this Snowflake project was a great experience. The Snowflake architecture was designed foundationally to take advantage of the cloud, but then adds some unique benefits for a very compelling solution and addresses the .
First, Snowflake leverages standard SQL query language. This will be an advantage for organizations who are already use SQL (pretty much everyone) in that teams will not need to be ?re-skilled?.
Importantly, Snowflake supports the most popular data formats like JSON, Avro, Parquet, ORC and XML. The ability to easily store structured, unstructured, and semi-structured data will help address the common problem of handling all the incongruent data types that exist in a single data warehouse. This is a big step towards providing more value on the data as a whole using advanced analytics.
Snowflake has a unique architecture for taking advantage of native cloud benefits. While most traditional warehouses have a single layer for their storage and compute, Snowflake takes a more subtle approach by separating data storage, data processing, and data consumption. Storage and compute resources are completely different and need to be handled separately. It?s really nice to ensure very cheap storage and more compute per dollar, while not drive up costs by mixing the two essential components of warehousing.
Snowflake provides two distinct user experiences for interacting with data for both a data engineer and a data analyst. The data engineer/s load the data and work from the application side, and is effectively the admin and owner of the system.
Data analysts consume the data and derive business insights from the data after it is loaded in the system by a data engineer. Here again, Snowflake separates the two roles by enabling a data analyst to clone a data warehouse and edit it to any extent without affecting the original data warehouse.
Lastly, Snowflake provides instant data warehouse scaling to handle concurrency bottlenecks during high demand periods. Snowflake scales without the need for redistributing data which can be a major disruption to end users.
Final Thoughts
Data warehousing is rapidly moving to the cloud and solutions such as Snowflake provide some distinct advantages over legacy technologies as outlined above.
In my opinion, traditional data warehousing methods and technologies are faced with a big challenge to provide the kind of service, simplicity, and value that rapidly changing businesses need and, quite frankly, are demanding, not to mention ensuring that initial and ongoing costs are manageable and reasonable.
Based on my testing, Snowflake certainly addressed the 2 key constraints for this project, namely, support for the ORC file format and maintaining backward compatibility with the existing Tableau workbooks.
Beyond addressing those constraints though, Snowflake delivered significant performance benefits, a simple and intuitive way for both admins and users to interact with the system, and lastly, a way to scale to levels of concurrency that weren?t previously possible ? all at a workable price point.
Snowflake was super fun and easy to work with and is an attractive proposition as a Cloud Data Warehousing solution. I look forward to sharing more thoughts on working with Snowflake in future posts.
Need Snowflake Cloud Data Warehousing and Migration Assistance?
If you?d like additional assistance in this area, Hashmap offers a range of enablement workshops and consulting service packages as part of our consulting service offerings, and would be glad to work through your specifics in this area.
Feel free to share on other channels and be sure and keep up with all new content from Hashmap by following our Engineering and Technology Blog including other Snowflake stories.
SnowAlert! Data Driven Security Analytics using Snowflake Data Warehouse
This is Worth Trying Out ? An Open Source Project for Security Analytics with Snowflake
medium.com
6 Steps to Secure PII in Snowflake?s Cloud Data Warehouse
How to Use Built-In Snowflake Security Features to Secure Personally Identifiable Information (PII)
medium.com
Quick Tips for Using Snowflake with AWS Lambda
A Working Example Using AWS Lambda Serverless Compute and Snowflake?s Cloud Data Warehouse Together
medium.com
Ed Fron is an Enterprise Architect at Hashmap working across industries with a group of innovative technologists and domain experts accelerating high value business outcomes for our customers. Connect with Ed on LinkedIn and be sure to catch Hashmap?s Weekly IoT on Tap Podcast for a casual conversation about IoT from a developer?s perspective.


{kind=link}
{kind=link}