
An easy to use Python library built especially for sentiment analysis of social media texts.
 PC:Pixabay/PDPics
PC:Pixabay/PDPics
?If you want to understand people, especially your customers?then you have to be able to possess a strong capability to analyze text. ? ? Paul Hoffman, CTO:Space-Time Insight
The 2016 US Presidential Elections were important for many reasons. Apart from the political aspect, the major use of analytics during the entire canvassing period garnered a lot of attention. During the elections, millions of Twitter data points, belonging to both Clinton and Trump, were analyzed and classified with a sentiment of either positive, neutral, or negative. Some of the interesting outcomes that emerged from the analysis were:
- The tweets that mentioned ?@realDonaldTrump? were greater than those mentioning ?@HillaryClinton?, indicating the majority were tweeting about Trump.
- For both candidates, negative tweets outnumbered the positive ones.
- The Positive to Negative Tweet ratio was better for Trump than for Clinton.
This is the power that sentiment analysis brings to the table and it was quite evident in the U.S elections. Well, the Indian Elections are around the corner too and sentiment analysis will have a key role to play there as well.
What is Sentiment Analysis?
 source
source
Sentiment Analysis, or Opinion Mining, is a sub-field of Natural Language Processing (NLP) that tries to identify and extract opinions within a given text. The aim of sentiment analysis is to gauge the attitude, sentiments, evaluations, attitudes and emotions of a speaker/writer based on the computational treatment of subjectivity in a text.
Why is sentiment analysis so important?
Businesses today are heavily dependent on data. Majority of this data however, is unstructured text coming from sources like emails, chats, social media, surveys, articles, and documents. The micro-blogging content coming from Twitter and Facebook poses serious challenges, not only because of the amount of data involved, but also because of the kind of language used in them to express sentiments, i.e., short forms, memes and emoticons.
Sifting through huge volumes of this text data is difficult as well as time-consuming. Also, it requires a great deal of expertise and resources to analyze all of that. Not an easy task, in short.
Sentiment Analysis is also useful for practitioners and researchers, especially in fields like sociology, marketing, advertising, psychology, economics, and political science, which rely a lot on human-computer interaction data.
Sentiment Analysis enables companies to make sense out of data by being able to automate this entire process! Thus they are able to elicit vital insights from a vast unstructured dataset without having to manually indulge with it.
Why is Sentiment Analysis a Hard to perform Task?
Though it may seem easy on paper, Sentiment Analysis is actually a tricky subject. There are various reasons for that:
- Understanding emotions through text are not always easy. Sometimes even humans can get misled, so expecting a 100% accuracy from a computer is like asking for the Moon!
- A text may contain multiple sentiments all at once. For instance,
?The intent behind the movie was great, but it could have been better?.
The above sentence consists of two polarities, i.e., Positive as well as Negative. So how do we conclude whether the review was Positive or Negative?
- Computers aren?t too comfortable in comprehending Figurative Speech. Figurative language uses words in a way that deviates from their conventionally accepted definitions in order to convey a more complicated meaning or heightened effect. Use of similes, metaphors, hyperboles etc qualify for a figurative speech. Let us understand it better with an example.
?The best I can say about the movie is that it was interesting.?
Here, the word ?interesting? does not necessarily convey positive sentiment and can be confusing for algorithms.
- Heavy use of emoticons and slangs with sentiment values in social media texts like that of Twitter and Facebook also makes text analysis difficult. For example a ? :)? denotes a smiley and generally refers to positive sentiment while ?:(? denotes a negative sentiment on the other hand. Also, acronyms like ?LOL?, ?OMG? and commonly used slangs like ?Nah?, ?meh?, ?giggly? etc are also strong indicators of some sort of sentiment in a sentence.
These are few of the problems encountered not only with sentiment analysis but with NLP as a whole. In fact, these are some of the Open-ended problems of the Natural Language Processing field.
VADER Sentiment Analysis
VADER (Valence Aware Dictionary and sEntiment Reasoner) is a lexicon and rule-based sentiment analysis tool that is specifically attuned to sentiments expressed in social media. VADER uses a combination of A sentiment lexicon is a list of lexical features (e.g., words) which are generally labelled according to their semantic orientation as either positive or negative.
VADER has been found to be quite successful when dealing with social media texts, NY Times editorials, movie reviews, and product reviews. This is because VADER not only tells about the Positivity and Negativity score but also tells us about how positive or negative a sentiment is.
It is fully open-sourced under the MIT License. The developers of VADER have used Amazon?s Mechanical Turk to get most of their ratings, You can find complete details on their Github Page.
 methods and process approach overview
methods and process approach overview
Advantages of using VADER
VADER has a lot of advantages over traditional methods of Sentiment Analysis, including:
- It works exceedingly well on social media type text, yet readily generalizes to multiple domains
- It doesn?t require any training data but is constructed from a generalizable, valence-based, human-curated gold standard sentiment lexicon
- It is fast enough to be used online with streaming data, and
- It does not severely suffer from a speed-performance tradeoff.
The source of this article is a very easy to read paper published by the creaters of VADER library.You can read the paper here.
Enough of talking. Let us now see practically how does VADER analysis work for which we will have install the library first.
Installation
The simplest way is to use the command line to do an installation from [PyPI] using pip. Check their Github repository for the detailed explanation.
> pip install vaderSentiment
Once VADER is installed let us call the SentimentIntensityAnalyser object,
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzeranalyser = SentimentIntensityAnalyzer()
Working & Scoring
Let us test our first sentiment using VADER now. We will use the polarity_scores() method to obtain the polarity indices for the given sentence.
def sentiment_analyzer_scores(sentence): score = analyser.polarity_scores(sentence) print(“{:-<40} {}”.format(sentence, str(score)))
Let us check how VADER performs on a given review:
sentiment_analyzer_scores(“The phone is super cool.”)The phone is super cool—————– {‘neg’: 0.0, ‘neu’: 0.326, ‘pos’: 0.674, ‘compound’: 0.7351}
Putting in a Tabular form:
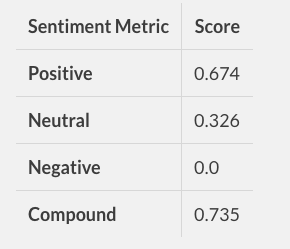
- The Positive, Negative and Neutral scores represent the proportion of text that falls in these categories. This means our sentence was rated as 67% Positive, 33% Neutral and 0% Negative. Hence all these should add up to 1.
- The Compound score is a metric that calculates the sum of all the lexicon ratings which have been normalized between -1(most extreme negative) and +1 (most extreme positive). In the case above, lexicon ratings for andsupercool are 2.9and respectively1.3. The compound score turns out to be 0.75 , denoting a very high positive sentiment.
 compound score metric
compound score metric
read here for more details on VADER scoring methodology.
VADER analyses sentiments primarily based on certain key points:
- Punctuation: The use of an exclamation mark(!), increases the magnitude of the intensity without modifying the semantic orientation. For example, ?The food here is good!? is more intense than ?The food here is good.? and an increase in the number of (!), increases the magnitude accordingly.
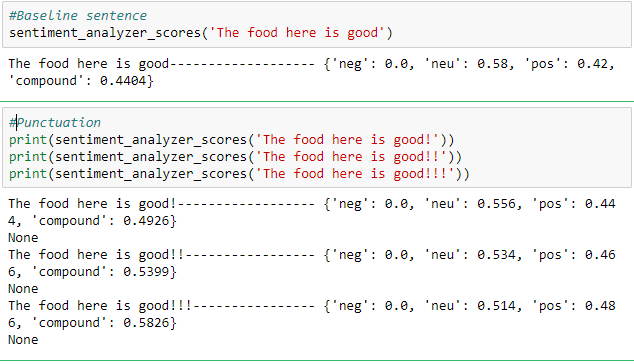
See how the overall compound score is increasing with the increase in exclamation marks.
- Capitalization: Using upper case letters to emphasize a sentiment-relevant word in the presence of other non-capitalized words, increases the magnitude of the sentiment intensity. For example, ?The food here is GREAT!? conveys more intensity than ?The food here is great!?

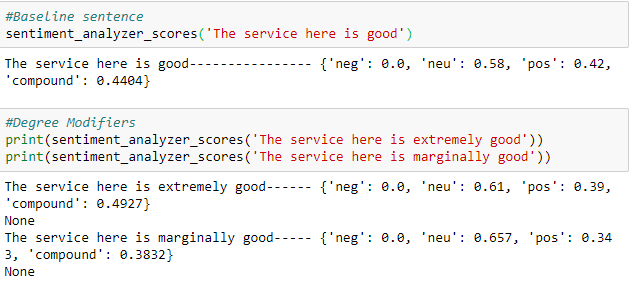
- Degree modifiers: Also called intensifiers, they impact the sentiment intensity by either increasing or decreasing the intensity. For example, ?The service here is extremely good? is more intense than ?The service here is good?, whereas ?The service here is marginally good? reduces the intensity.
- Conjunctions: Use of conjunctions like ?but? signals a shift in sentiment polarity, with the sentiment of the text following the conjunction being dominant. ?The food here is great, but the service is horrible? has mixed sentiment, with the latter half dictating the overall rating.

- Preceding Tri-gram: By examining the tri-gram preceding a sentiment-laden lexical feature, we catch nearly 90% of cases where negation flips the polarity of the text. A negated sentence would be ?The food here isn?t really all that great?.
Handling Emojis, Slangs, and Emoticons.
VADER performs very well with emojis, slangs, and acronyms in sentences. Let us see each with an example.
- Emojis
print(sentiment_analyzer_scores(‘I am ? today’))print(sentiment_analyzer_scores(‘?’))print(sentiment_analyzer_scores(‘?’))print(sentiment_analyzer_scores(‘??’))#OutputI am ? today—————————- {‘neg’: 0.0, ‘neu’: 0.476, ‘pos’: 0.524, ‘compound’: 0.6705}?————————————— {‘neg’: 0.0, ‘neu’: 0.333, ‘pos’: 0.667, ‘compound’: 0.7184}?————————————— {‘neg’: 0.275, ‘neu’: 0.268, ‘pos’: 0.456, ‘compound’: 0.3291}??————————————– {‘neg’: 0.706, ‘neu’: 0.294, ‘pos’: 0.0, ‘compound’: -0.34}?————————————— {‘neg’: 0.0, ‘neu’: 1.0, ‘pos’: 0.0, ‘compound’: 0.0}
- Slangs
print(sentiment_analyzer_scores(“Today SUX!”))print(sentiment_analyzer_scores(“Today only kinda sux! But I’ll get by, lol”))#outputToday SUX!—————————— {‘neg’: 0.779, ‘neu’: 0.221, ‘pos’: 0.0, ‘compound’: -0.5461}Today only kinda sux! But I’ll get by, lol {‘neg’: 0.127, ‘neu’: 0.556, ‘pos’: 0.317, ‘compound’: 0.5249}
- Emoticons
print(sentiment_analyzer_scores(“Make sure you 🙂 or 😀 today!”))Make sure you 🙂 or 😀 today!———– {‘neg’: 0.0, ‘neu’: 0.294, ‘pos’: 0.706, ‘compound’: 0.8633}
We saw how VADER can easily detect sentiment from emojis and slangs which form an important component of the social media environment.
Conclusion
The results of VADER analysis are not only remarkable but also very encouraging. The outcomes highlight the tremendous benefits that can be attained by the use of VADER in cases of micro-blogging sites wherein the text data is a complex mix of a variety of text.
Additional Resources
Here are some additional resources worth mentioning for in-depth Sentiment Analysis
- Sentiment Analysis by MonkeyLearn: A comprehensive guide to Sentiment Analysis which covers almost everything in this field; what it is, how it works, algorithms, limitations, how accurate it is, tutorials, datasets, lexicons, libraries, use cases and applications, and more!


){kind=link}
){kind=link}