Let?s review the YOLO (You Only Look Once) real-time object detection algorithm, which is one of the most effective object detection algorithms that also encompasses many of the most innovative ideas coming out of the computer vision research community. Object detection is a critical capability of autonomous vehicle technology. It?s an area of computer vision that?s exploding and working so much better than just a few years ago. At the end of this article, we?ll see a couple of recent updates to YOLO by the original researchers of this important technique.
YOLO came on the computer vision scene with the seminal 2015 paper by Joseph Redmon et al. ?You Only Look Once: Unified, Real-Time Object Detection,? and immediately got a lot of attention by fellow computer vision researchers. Here is a TED talk by University of Washington researcher Redmon in 2017 highlighting the state of the art in computer vision.
What is YOLO?
Object detection is one of the classical problems in computer vision where you work to recognize what and where ? specifically what objects are inside a given image and also where they are in the image. The problem of object detection is more complex than classification, which also can recognize objects but doesn?t indicate where the object is located in the image. In addition, classification doesn?t work on images containing more than one object.
YOLO uses a totally different approach. YOLO is a clever convolutional neural network (CNN) for doing object detection in real-time. The algorithm applies a single neural network to the full image, and then divides the image into regions and predicts bounding boxes and probabilities for each region. These bounding boxes are weighted by the predicted probabilities.
YOLO is popular because it achieves high accuracy while also being able to run in real-time. The algorithm ?only looks once? at the image in the sense that it requires only one forward propagation pass through the neural network to make predictions. After non-max suppression (which makes sure the object detection algorithm only detects each object once), it then outputs recognized objects together with the bounding boxes.
With YOLO, a single CNN simultaneously predicts multiple bounding boxes and class probabilities for those boxes. YOLO trains on full images and directly optimizes detection performance. This model has a number of benefits over other object detection methods:
- YOLO is extremely fast
- YOLO sees the entire image during training and test time so it implicitly encodes contextual information about classes as well as their appearance.
- YOLO learns generalizable representations of objects so that when trained on natural images and tested on artwork, the algorithm outperforms other top detection methods.
Here is an impressive video demonstration that shows YOLO?s success in object detection:
A YOLO Update
Further research was conducted resulting in the December 2016 paper ?YOLO9000: Better, Faster, Stronger,? by Redmon and Farhadi, both from the University of Washington, that provided a number of improvements to the YOLO detection method including the detection of over 9,000 object categories by jointly optimizing detection and classification.
Even more recently, the same researchers wrote another paper in April 2018 on their progress with evolving YOLO even further, ?YOLOv3: An Incremental Improvement? with code available on a GitHub repo.
As with a lot of research work in deep learning, much of the effort is trial and error. In pursuit of YOLOv3, this effect was in force as the team tried a lot of different ideas, but many of them didn?t work out. A few of the things that stuck include: a new network for performing feature extraction consisting of 53 convolutional layers, a new detection metric, predicting an ?objectness? score for each bounding box using logistic regression, and using binary cross-entropy loss for the class predictions during training. The end result is that YOLOv3 runs significantly faster than other detection methods with comparable performance. In addition, YOLO no longer struggles with small objects.
I found it interesting that at the end of the YOLOv3 paper the authors, who are top-notch researchers actively pushing the envelope of this technology, reflect on how object detection is destined to be used:
?What are we going to do with these detectors now that we have them?? A lot of the people doing this research are at Google and Facebook. I guess at least we know the technology is in good hands and definitely won?t be used to harvest your personal information and sell it to ? wait, you?re saying that?s exactly what it will be used for?? Oh. Well the other people heavily funding vision research are the military and they?ve never done anything horrible like killing lots of people with new technology, oh wait ??
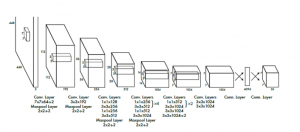
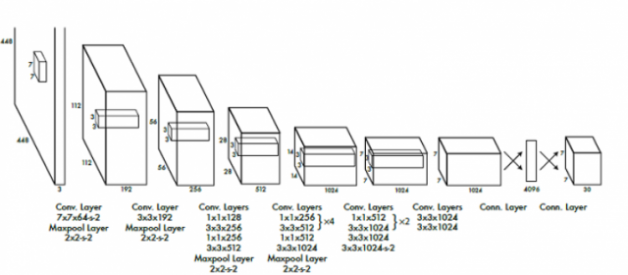
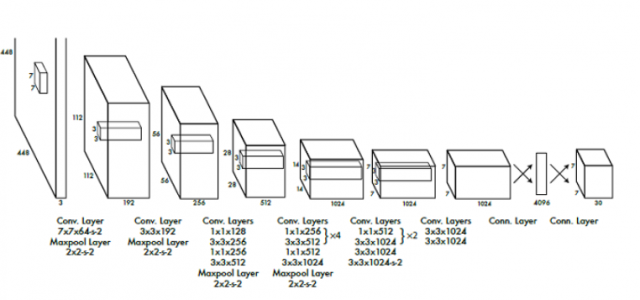
Source: ?You Only Look Once: Unified, Real-Time Object Detection,? by Redmon et al.
The above image contains the CNN architecture for YOLO which is inspired by the GoogLeNet model for image classification. It is rather complex. If you want to truly understand the theoretical foundation and underlying mathematics of this area of deep learning, I highly recommend Andrew Ng?s new specialization program.
Read more data science articles on OpenDataScience.com, including tutorials and guides from beginner to advanced levels! Subscribe to our weekly newsletter here and receive the latest news every Thursday.

{kind=link}
{kind=link}