
 MIT Deep Learning series of courses (6.S091, 6.S093, 6.S094). Lecture videos and tutorials are open to all.
MIT Deep Learning series of courses (6.S091, 6.S093, 6.S094). Lecture videos and tutorials are open to all.
As part of the MIT Deep Learning series of lectures and GitHub tutorials, we are covering the basics of using neural networks to solve problems in computer vision, natural language processing, games, autonomous driving, robotics, and beyond.
This blog post provides an overview of deep learning in 7 architectural paradigms with links to TensorFlow tutorials for each. It accompanies the following lecture on Deep Learning Basics as part of MIT course 6.S094:
Deep learning is representation learning: the automated formation of useful representations from data. How we represent the world can make the complex appear simple both to us humans and to the machine learning models we build.
My favorite example of the former is the publication in 1543 by Copernicus of the heliocentric model that put the Sun at the center of the ?Universe? as opposed to the prior geocentric model that put the Earth at the center. At its best, deep learning allows us to automate this step, removing Copernicus (i.e., expert humans) from the ?feature-engineering? process:
 Heliocentrism (1543) vs Geocentrism (6th century BC). Trajectory source.
Heliocentrism (1543) vs Geocentrism (6th century BC). Trajectory source.
At a high-level, neural networks are either encoders, decoders, or a combination of both:
- Encoders find patterns in raw data to form compact, useful representations.
- Decoders generate high-resolution data from those representations. The generated data is either new examples or descriptive knowledge.
The rest is clever methods that help us deal effectively with visual information, language, audio (#1?6) and even act in a world based on this information and occasional rewards (#7). Here?s the big picture view:
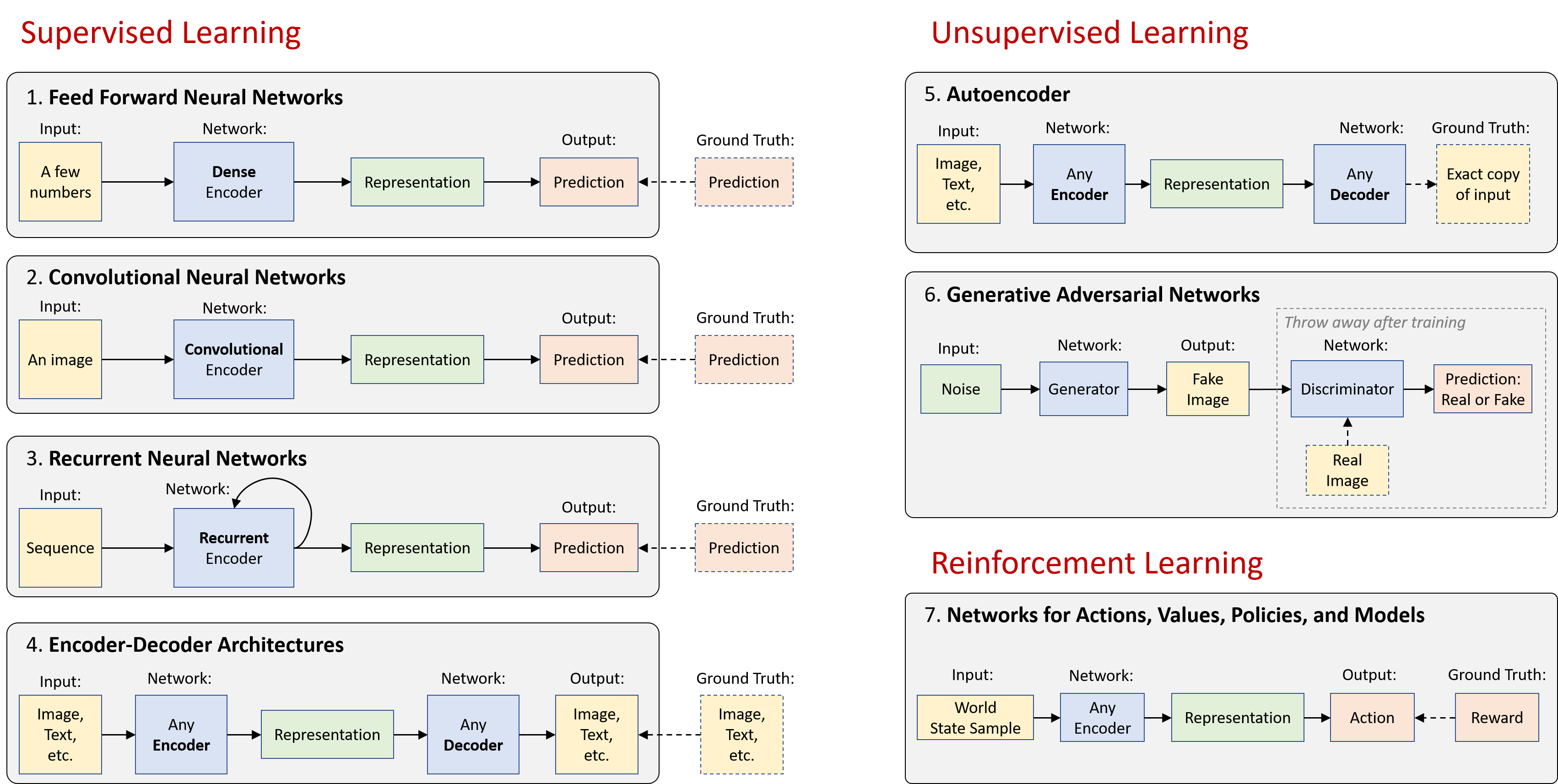
In the following sections, I?ll briefly describe each of the 7 architectural paradigms with links to illustrative TensorFlow tutorials for each. See ?Beyond the Basics? section at the end that discusses some exciting areas of deep learning that don?t cleanly fall into these seven categories.
1. Feed Forward Neural Networks (FFNNs)
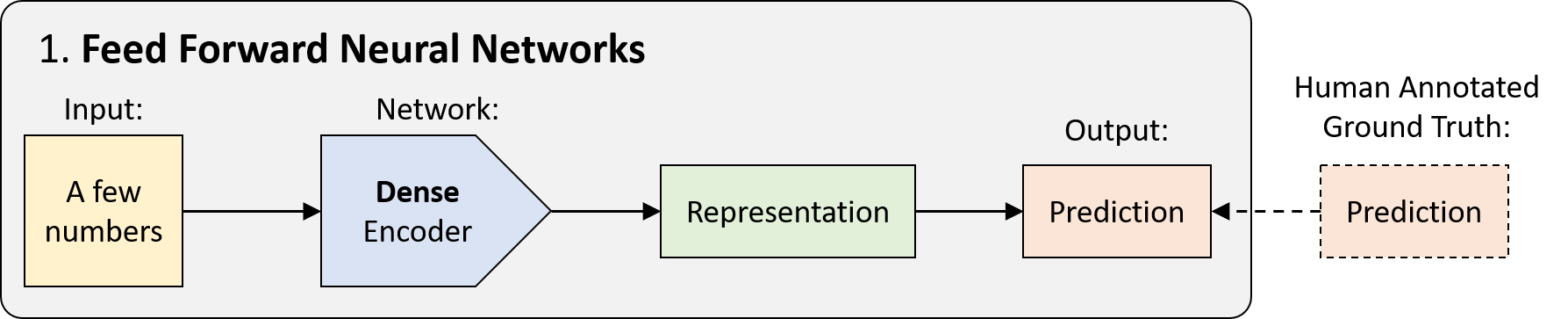
FFNNs, with a history dating back to 1940s, are simply networks that don?t have any cycles. Data passes from input to output in a single pass without any ?state memory? of what came before. Technically, most networks in deep learning can be considered FFNNs, but usually ?FFNN? refers to its simplest variant: a densely-connected multilayer perceptron (MLP).
Dense encoders are used to map an already compact set of numbers on the input to a prediction: either a classification (discrete) or a regression (continuous).
TensorFlow Tutorial: See part 1 of our Deep Learning Basics tutorial for an example of FFNNs used for Boston housing price prediction formulated as a regression problem:
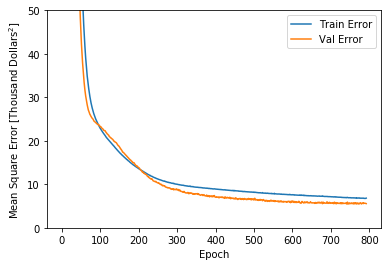 Error on the training and validation sets as the network learns.
Error on the training and validation sets as the network learns.
2. Convolutional Neural Networks (CNNs)

CNNs (aka ConvNets) are feed forward neural networks that use a spatial-invariance trick to efficiently learn local patterns, most commonly, in images. Spatial-invariance means that a cat ear in the top left of the image has the same features as a cat ear in bottom right of the image. CNNs share weights across space to make the detection of cat ears and other patterns more efficient.
Instead of using only densely-connected layers, they use convolutional layers (convolutional encoder). These networks are used for image classification, object detection, video action recognition, and any data that has some spatial invariance in its structure (e.g., speech audio).
TensorFlow Tutorial: See part 2 of our Deep Learning Basics tutorial for an example of CNNs used for classifying handwritten digits in the MNIST dataset with a beautiful dream-like twist where we test our classifier on high-resolution generated, morphing hand-written digits from outside the dataset:
 Classification predictions (right) of the morphing, generated handwritten digits (left).
Classification predictions (right) of the morphing, generated handwritten digits (left).
3. Recurrent Neural Networks (RNNs)

RNNs are networks that have cycles and therefore have ?state memory?. They can be unrolled in time to become feed forward networks where the weights are shared. Just as CNNs share weights across ?space?, RNNs share weights across ?time?. This allows them to process and efficiently represent patterns in sequential data.
Many variants of RNNs modules have been developed, including LSTMs and GRUs, to help learn patterns in longer sequences. Applications include natural language modeling, speech recognition, speech generation, etc.
TensorFlow Tutorial: Recurrent neural networks can be challenging to train but at the same time allow us to do some fun and powerful modeling of sequential data. The tutorial on Text Generation with TensorFlow is one of my favorites because it accomplishes something remarkable in very few lines of code: generate reasonable text on a character by character basis:
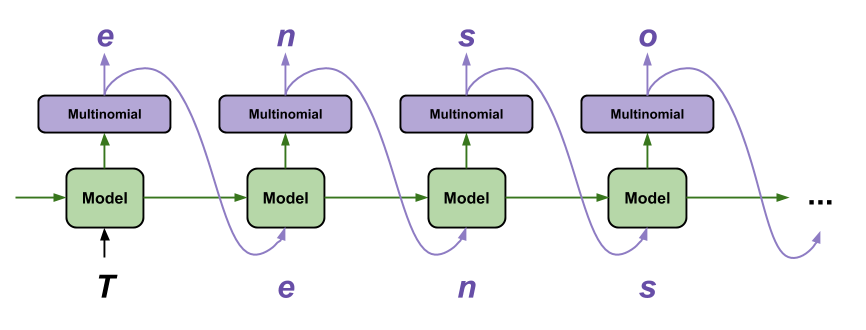 Source: Text Generation with TensorFlow
Source: Text Generation with TensorFlow
4. Encoder-Decoder Architectures

FFNNs, CNNs, and RNNs presented in first 3 sections are simply networks that make a prediction using either a dense encoder, convolutional encoder, or a recurrent encoder, respectively. These encoders can be combined or switched depending on the kind of raw data we?re trying to form a useful representation of. ?Encoder-Decoder? architecture is a higher level concept that builds on the encoding step to, instead of making a prediction, generate a high-dimensional output via a decoding step by upsampling the compressed representation.
Note that the encoder and decoder can be very different from each other. For example an image captioning network may have a convolutional encoder (for an image input) and a recurrent decoder (for a natural language output). Applications include semantic segmentation, machine translation, etc.
TensorFlow Tutorial: See our tutorial on Driving Scene segmentation that demonstrates a state-of-the-art segmentation network for the problem of autonomous vehicle perception:
 Tutorial: Driving Scene Segmentation with TensorFlow
Tutorial: Driving Scene Segmentation with TensorFlow
5. Autoencoders
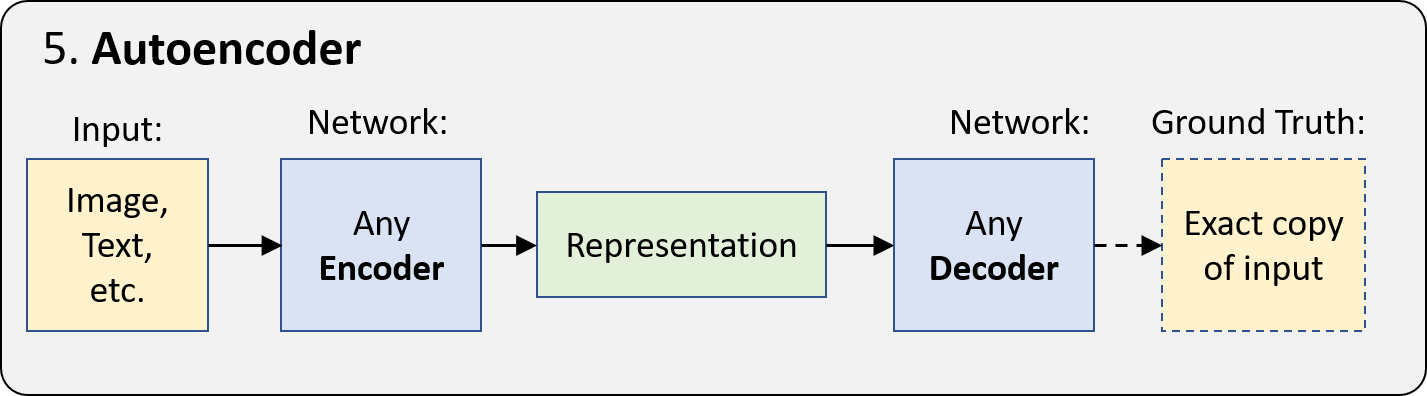
Autoencoders are one of the simpler forms of ?unsupervised learning? taking the encoder-decoder architecture and learning to generate an exact copy of the input data. Since the encoded representation is much smaller than the input data, the network is forced to learn how to form the most meaningful representation.
Since the ground truth data comes from the input data, no human effort is required. In other words, it?s self-supervised. Applications include unsupervised embeddings, image denoising, etc. But most importantly, its fundamental idea of ?representation learning? is central to the generative models in the next section and all of deep learning.
TensorFlow Tutorial: You can explore the ability of autoencoders to both (1) denoise input data and (2) form embeddings on the MNIST dataset in this TensorFlow Keras tutorial.
6. Generative Adversarial Networks (GANs)
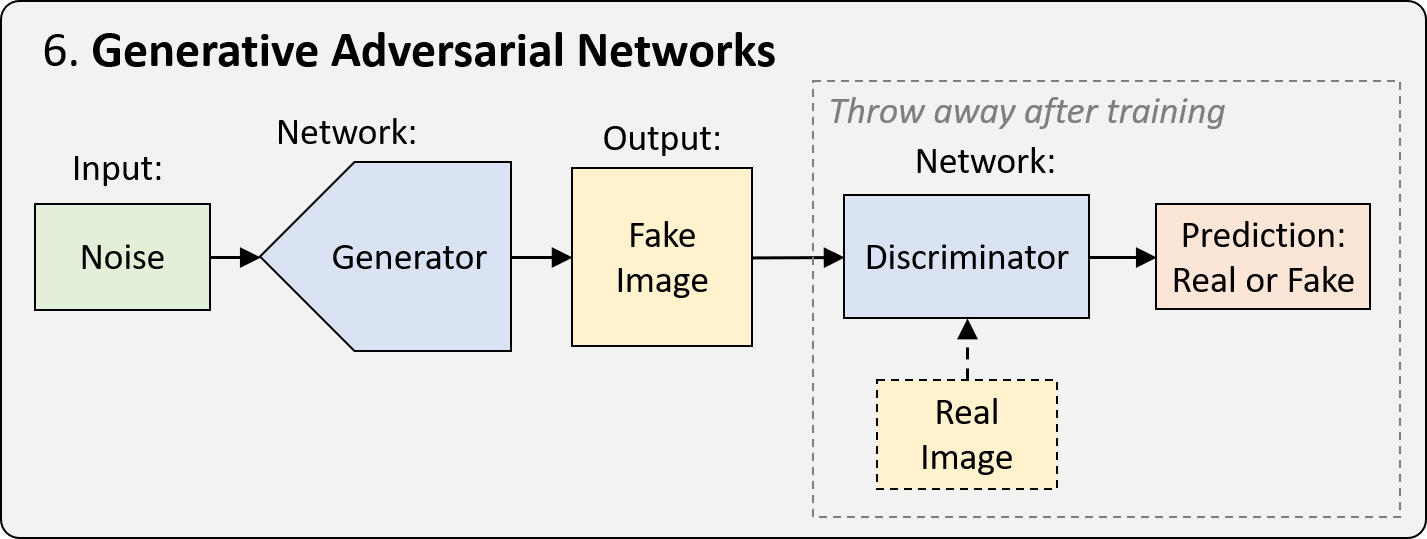
GANs are a framework for training networks optimized for generating new realistic samples from a particular representation. In its simplest form, the training process involves two networks. One network, called the generator, generates new data instances, trying to fool the other network, the discriminator, that classifies images as real or fake.
Over the past few years, many variants and improvements for GANs have been proposed, including the ability generate images from a particular class, the ability to map images from one domain to another, and an incredible increase in realism of generated images. See the lecture on Deep Learning State of the Art that touches on and contextualizes the rapid development of GANs. For example, take a look at three samples generated from a single category (fly agaric mushroom) by BigGAN (arXiv paper):


 Images generated by BigGAN.
Images generated by BigGAN.
TensorFlow Tutorial: See tutorials on conditional GANs and DCGANs for examples of early variants of GANs. We?ll be releasing a tutorial on the state-of-the-art in GANs on our GitHub as the course progresses.
7. Deep Reinforcement Learning (Deep RL)
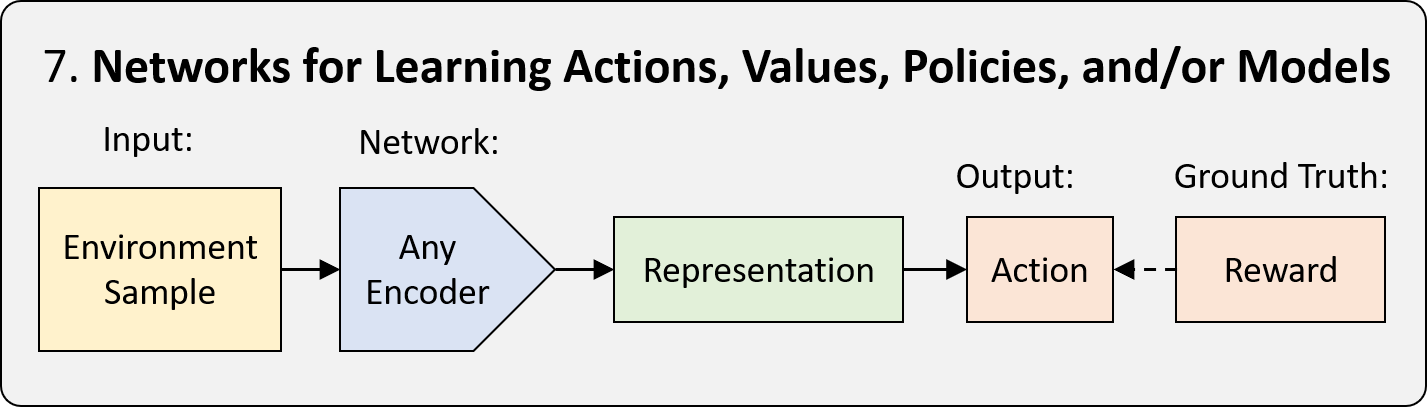
Reinforcement learning (RL) is a framework for teaching an agent how to act in the world in a way that maximizes reward. When the learning is done by a neural network, we refer to it as Deep Reinforcement Learning (Deep RL). There are three types of RL frameworks: policy-based, value-based, and model-based. The distinction is what the neural network is tasked with learning. See the Introduction to Deep RL lecture for MIT course 6.S091 for more details. Deep RL allows us to apply neural networks in simulated or real-world environments when sequences of decisions need to be made. This includes game playing, robotics , neural architecture search, and much more.
Tutorial: Our DeepTraffic environment provides a tutorial and code samples for a quick way to explore, train, and evaluate Deep RL agents in the browser, and we will shortly be releasing TensorFlow tutorials for GPU-enabled training on GitHub:
 MIT DeepTraffic: Deep Reinforcement Learning Competition
MIT DeepTraffic: Deep Reinforcement Learning Competition
Beyond the Basics
Several important concepts in deep learning are not directly represented by architectures above. Examples include Variational Autoencoders (VAE), ideas of ?memory? either in LSTM/GRU or Neural Turing Machine context, Capsule Networks, and in general, ideas of attention, transfer learning, meta-learning, and the distinction of model-based, value-based, policy-based methods, and actor-critic methods in RL. Finally many deep learning systems combine these architectures in complex ways to jointly learn from multi-modal data or jointly learn to solve multiple tasks. Many of these concepts are covered in the other lectures for the course with more coming soon:



On a personal note, as I said in the comments, it?s humbling for me to have the opportunity to teach at MIT and exciting to be part of the AI and TensorFlow community. Thank you all for the support and great discussions over the past few years. It?s been an amazing ride. If you have suggestions for topics I should cover in future lectures, let me know (on Twitter or LinkedIn).


{kind=link}
{kind=link}