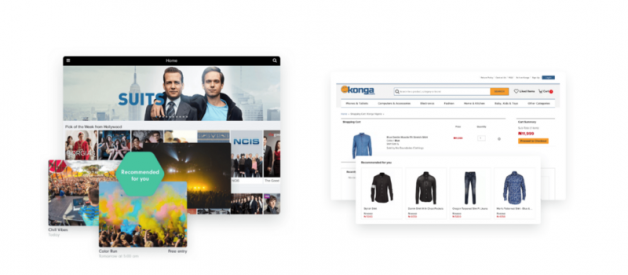
Recommender systems are one of the most successful and widespread application of machine learning technologies in business. There were many people on waiting list that could not attend our MLMU talk so I am sharing slides and comments here.

You can apply recommender systems in scenarios where many users interact with many items.
You can find large scale recommender systems in retail, video on demand, or music streaming. In order to develop and maintain such systems, a company typically needs a group of expensive data scientist and engineers. That is why even large corporates such as BBC decided to outsource its recommendation services.

Our company Recombee is based in Prague and develops an universal automated recommendation engine capable of adapting to business needs in multiple domains. Our engine is used by hundreds of businesses all over the world.

Surprisingly, recommendation of news or videos for media, product recommendation or personalization in travel and retail can be handled by similar machine learning algorithms. Furthermore, these algorithms can be adjusted by using our special query language in each recommendation request.
Algorithms

Machine learning algorithms in recommender systems are typically classified into two categories ? content based and collaborative filtering methods although modern recommenders combine both approaches. Content based methods are based on similarity of item attributes and collaborative methods calculate similarity from interactions. Below we discuss mostly collaborative methods enabling users to discover new content dissimilar to items viewed in the past.

Collaborative methods work with the interaction matrix that can also be called rating matrix in the rare case when users provide explicit rating of items. The task of machine learning is to learn a function that predicts utility of items to each user. Matrix is typically huge, very sparse and most of values are missing.
The simplest algorithm computes cosine or correlation similarity of rows (users) or columns (items) and recommends items that k ? nearest neighbors enjoyed.

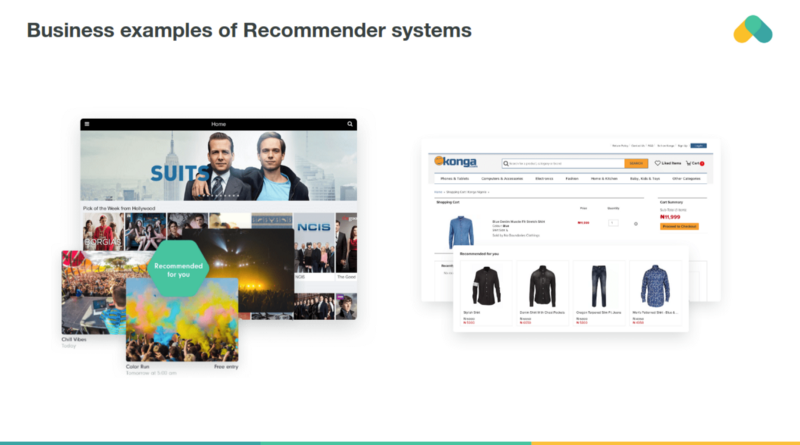
Matrix factorization based methods attempt to reduce dimensionality of the interaction matrix and approximate it by two or more small matrices with k latent components.

By multiplying corresponding row and column you predict rating of item by user. Training error can be obtained by comparing non empty ratings to predicted ratings. One can also regularize training loss by adding a penalty term keeping values of latent vectors low.

Most popular training algorithm is a stochastic gradient descent minimizing loss by gradient updates of both columns and rows of p a q matrices.

Alternatively, one can use Alternating Least Squares method that iteratively optimizes matrix p and matrix q by general least squares step.

Association rules can also be used for recommendation. Items that are frequently consumed together are connected with an edge in the graph. You can see clusters of best sellers (densely connected items that almost everybody interacted with) and small separated clusters of niche content.

Rules mined from the interaction matrix should have at least some minimal support and confidence. Support is related to frequency of occurrence ? implications of bestsellers have high support. High confidence means that rules are not often violated.
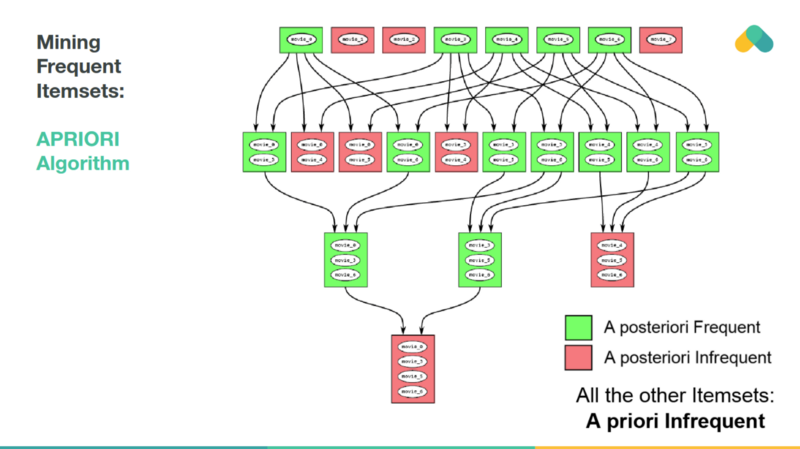
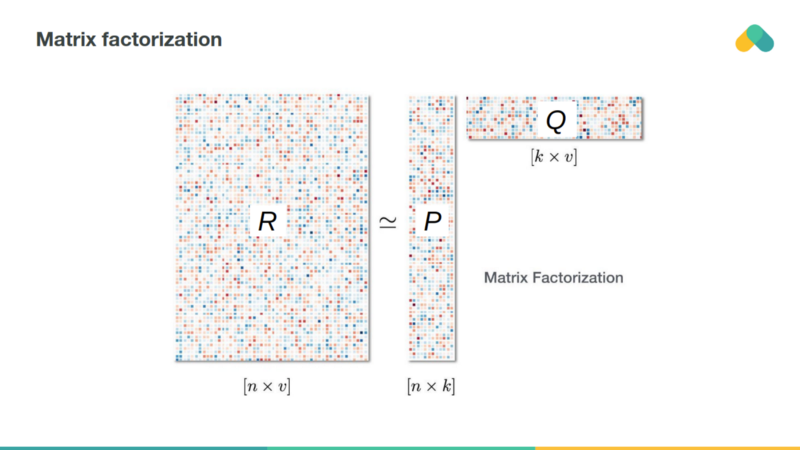
Mining rules is not very scalable. The APRIORI algorithm explores the state space of possible frequent itemsets and eliminates branches of the search space, that are not frequent.
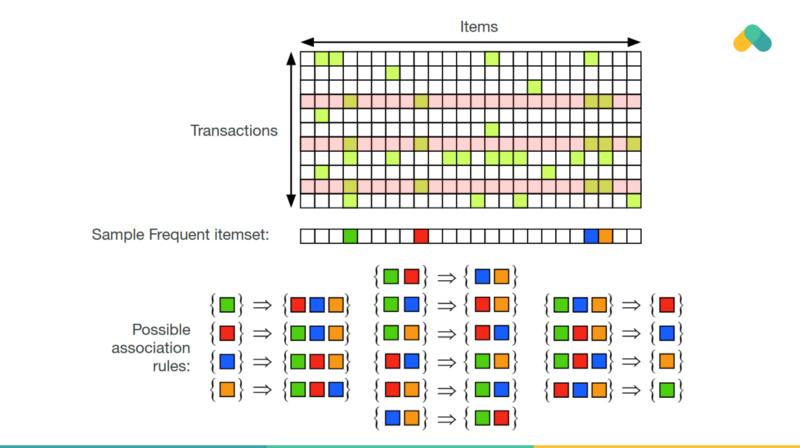
Frequent itemsets are used to generate rules and these rules generate recommendations.

As an example we show rules extracted from bank transactions in the Czech Republic. Nodes (interactions) are terminals and edges are frequent transactions. You can recommend bank terminals that are relevant based on past withdrawals / payments.

Penalizing popular items and extracting long tail rules with lower support leads to interesting rules that diversify recommendations and help to discover new content.
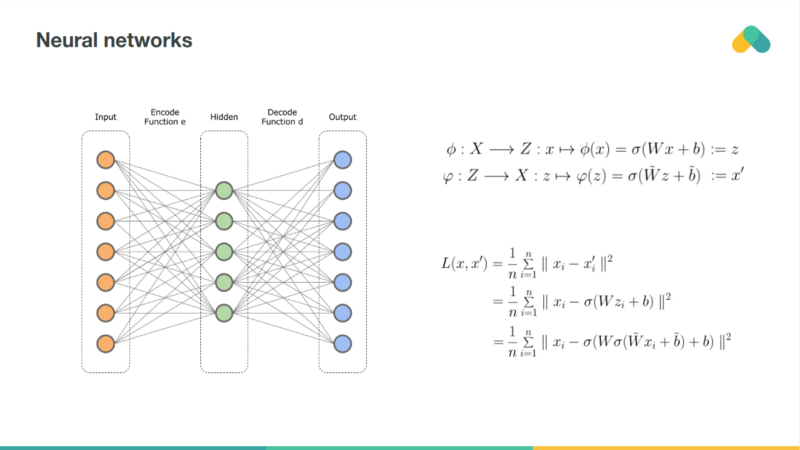
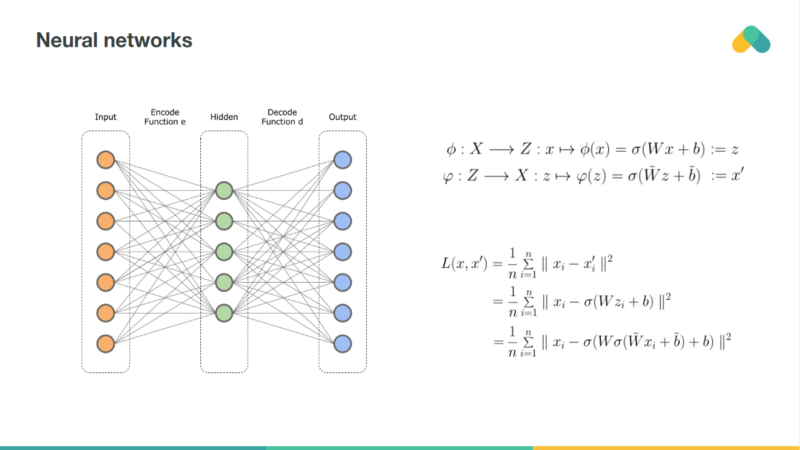
Rating matrix can be also compressed by a neural network. So called autoencoder is very similar to the matrix factorization. Deep autoencoders, with multiple hidden layers and nonlinearities are more powerful but harder to train. Neural net can be also used to preprocess item attributes so we can combine content based and collaborative approaches.
User-KNN top N recommendation pseudocode is given above.

Associations rules can be mined by multiple different algorithms. Here we show the Best-Rule recommendations pseudocode.

The pseudocode of matrix factorization is given above.

In collaborative deep learning, you train matrix factorization simultaneously with autoencoder incorporating item attributes. There are of course many more algorithms you can use for recommendation and the next part of the presentation introduces some methods based on deep and reinforcement learning.
Evaluation of recommenders

Recommenders can be evaluated similarly as classical machine learning models on historical data (offline evaluation).

Interactions of randomly selected testing users are cross validated to estimate the performance of recommender on unseen ratings.
Root mean squared error (RMSE) is still widely used despite many studies showed that RMSE is poor estimator of online performance.

More practical offline evaluation measure is recall or precision evaluating percentage of correctly recommended items (out of recommended or relevant items). DCG takes also the position into consideration assuming that relevance of items logarithmically decreases.

One can use additional measure that is not so sensitive to bias in offline data. Catalog coverage together with recall or precision can be used for multiobjective optimization. We have introduced regularization parameters to all algorithms allowing to manipulate their plasticity and penalize recommendation of popular items.
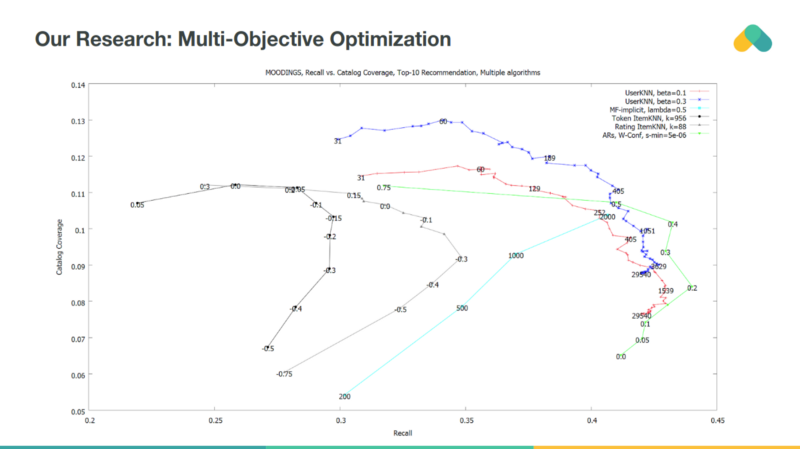
Both recall and coverage should be maximized so we drive recommender towards accurate and diverse recommendations enabling users to explore new content.
Cold start and content based recommendation

Sometimes interactions are missing. Cold start products or cold start users do not have enough interactions for reliable measurement of their interaction similarity so collaborative filtering methods fail to generate recommendations.
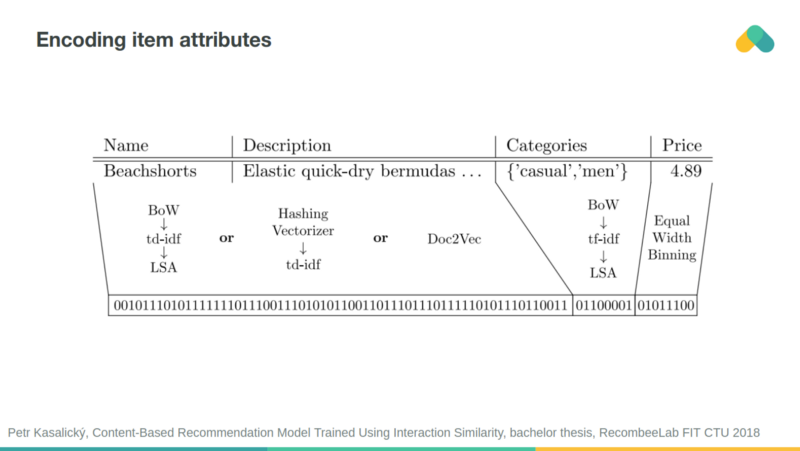
Cold start problem can be reduced when attribute similarity is taken into account. You can encode attributes into binary vector and feed it to recommender.
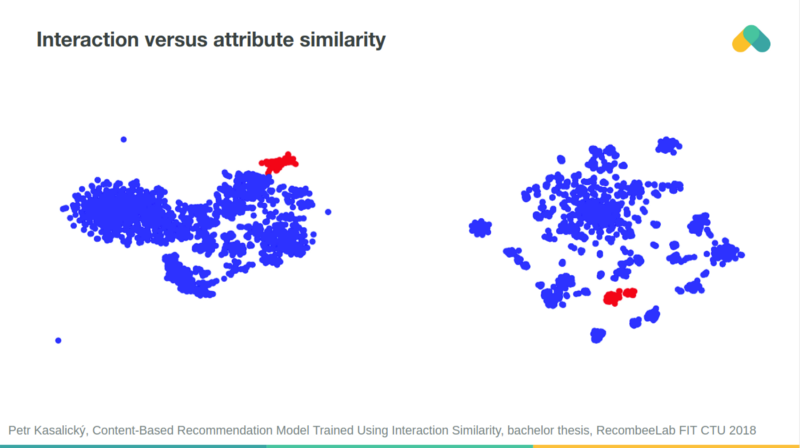
Items clustered based on their interaction similarity and attribute similarity are often aligned.
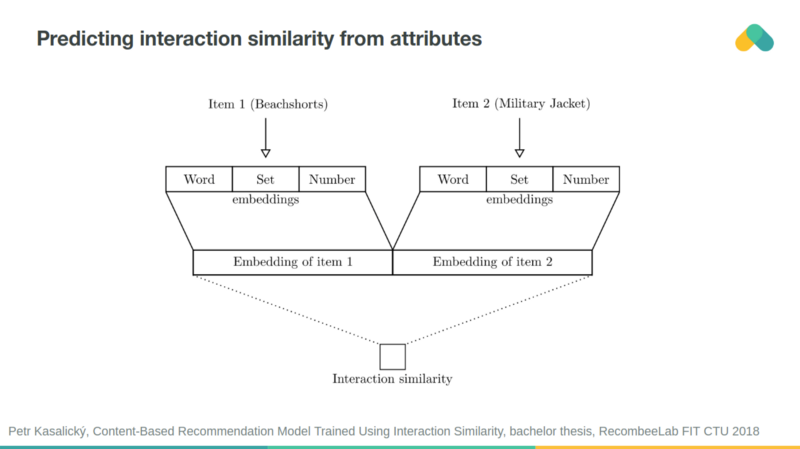
You can use neural network to predict interaction similarity from attributes similarity and vice versa.

There are many more approaches enabling us to reduce the cold start problem and improve the quality of recommendation. In the second part of our talk we discussed session based recommendation techniques, deep recommendation, ensembling algorithms and AutoML that enables us to run and optimize thousands of different recommendation algorithms in production.
Continue to the second part of the presentation discussing Deep Recommendation, Sequence Prediction, AutoML and Reinforcement Learning in Recommendation.
Or check our recent updates in Recombee in 2019: New Features and Improvements.


){kind=link}
){kind=link}