
There are four files in the characters/ folder. Some information is encrypted in them.

Yuri
Let?s start with the text file yuri.chr. Get the first and the last 50 bytes.
$ head -c 50 yuri.chrSWYgeW91IGZvdW5kIHRoaXMgbm90ZSBpbiBhIHNtYWxsIHdvb2$ tail -c 50 yuri.chrFsbHkgcmVhbGx5LCByZWFsbHkgaG9wZSBzby4NCg0KfuKZpQ==
It looks like base64, so decode it:
$ cat yuri.chr | base64 -d > yuri.txt$ head -c 50 yuri.chrIf you found this note in a small wooden box with$ tail -c 50 yuri.txtis you. I actually really, really hope so. ~?
Sayori
sayori.chr is ogg audio. This can be verified by doing:
$ file sayori.chrsayori.chr: Ogg data, Vorbis audio, mono, 44100 Hz, ~110000 bps, created by: Xiph.Org libVorbis I
If you play it in ffplay, you will see a spectrogram:
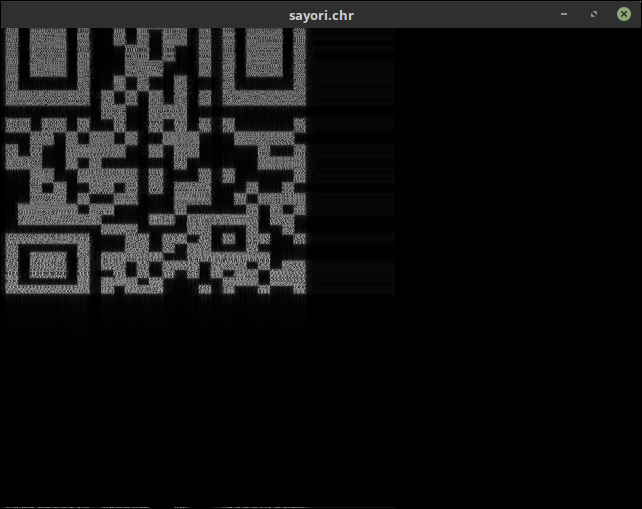
Obviously, we have a QR code. Now extract an image with ffmpeg and showspectrumpicfilter:
ffmpeg -i sayori.chr -lavfi showspectrumpic=’s=300×510:saturation=0:scale=4thrt:legend=0′,negate -y sayori_qr.png
The filter parameters can be found in the documentation. The main problem was with choosing the right size (parameter s). If aspect ratio doesn?t match, then the QR code could be truncated or stretched. saturation=0 makes the image grayscale, scale=4thrt adds contrast to the image, and legend=0 removes the legend from the resulting image. Then we need to apply negate filter. Here?s the result:

After fixing image in editor, I got:

Natsuki
natsuki.chr is jpeg image.

Let?s negate image and flip it vertically:
ffmpeg -i natsuki.chr -vf negate,vflip natsuki.jpg
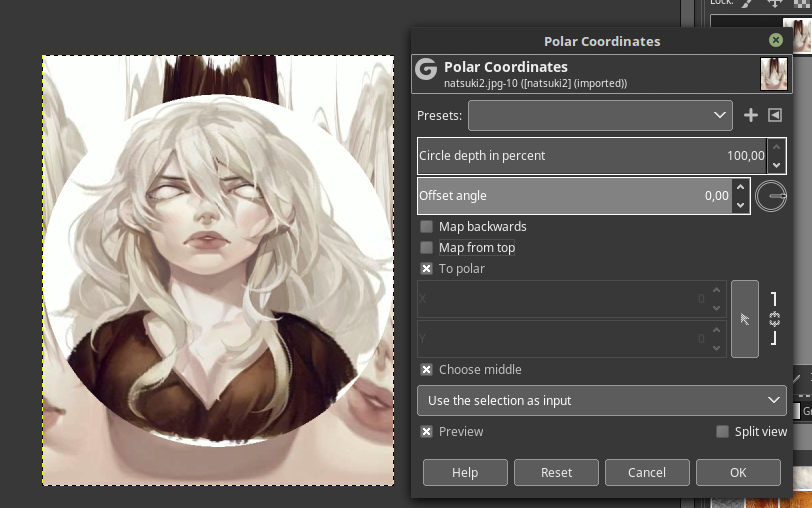
Now we need to convert the image to polar coordinates. In GIMP it?s Filters -> Distorts -> Polar Coordinates:

Monika
Finally, monika.chr.This is png image with 800×800 size.

In the center of the image is a black and white picture. Crop it:
ffmpeg -i monika.chr -vf crop=140:140:330:330 monika_code.png
Now each black pixel becomes bit 0, and each white pixel becomes bit 1. We get a sequence of zeros and ones of length 140 * 140 = 19600.
01010001001100100100011001110101010010010100100001101100011…………11001110011110100000000000000000000000000000000000000000000000000000000000000000000000000000000
Convert bits to symbols. Got 2450 bytes of text:
Q2FuIHlvdSBoZWFyIG1lPw0KDQouLi5XaG8gYXJlIHlvdT8NCg0KSSB………….Qm90aCBvZiB1cy4NCg0KDQoNCjIwMTg=
The script that does all the work:
Also I added encoder script to encode something into binary image.
It looks like we got a string in base64 again. Let?s finally decode text:
$ python3 monika_decode.py monika_code.png | base64 -d > monika.txt$ tail -n 5 monika.txtBoth of us.2018
- Russian version of this article


{kind=link}
{kind=link}