
What?s the difference?
 Photo by Mr Cup / Fabien Barral on Unsplash
Photo by Mr Cup / Fabien Barral on Unsplash
With technology changing rapidly, more and more data is being generated all the time.
It?s estimated that the amount of data generated in the entire world will grow to 175 zettabytes by 2025, according to the most recent Global Datasphere.
Companies now require improved software to manage these massive amounts of data. They?re? constantly looking for ways to process and store data, and distribute it across different servers so that they can make use of it.
In this article, we?ll discuss a specific family of data management tools that often get confused and used interchangeably when discussed. Today we?ll talk about Hadoop, HDFS, HBase, and Hive, and how they help us process and store large amounts of data.
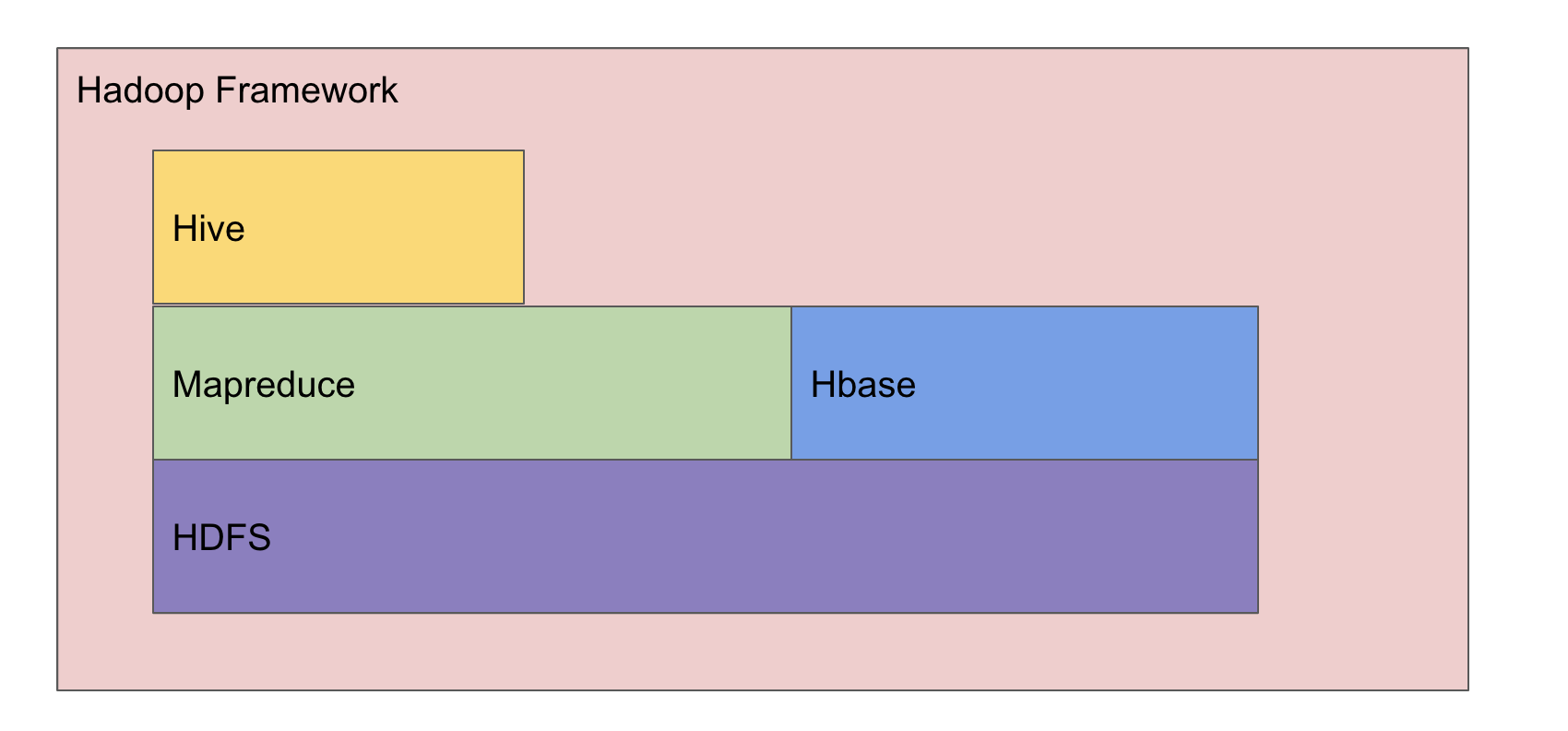
Hadoop
Hadoop is often used as a catch-all term when referring to several different technologies. However, Hadoop is also a specific software framework. It gives users the ability to manage distributed computing and storage easily. It does this by dividing documents across several stores and blocks across a cluster of machines.
To achieve fault tolerance, Hadoop replicates these stores on the cluster. It then performs distributed processing by dividing a job into several smaller independent tasks. This task is then run in parallel over the cluster of computers.
Hadoop works with distributed processing on large data sets across a cluster service to work on multiple machines simultaneously. To process any data on Hadoop uses several services, which we will discuss:
- HDFS: HDFS, or Hadoop Distributed File System, is a primary-secondary topology that has two daemons running: DataNode and NameNode. More on this later.
- MapReduce: This is an algorithm that processes your big data in parallel on the distributed cluster. MapReduce can then combine this data into results.
- YARN: The function of YARN is to divide source management, job monitoring, and scheduling tasks into separate daemons. It can skill beyond just a few thousand nodes. This is because the YARN federation allows a user to via multiple clusters into one big cluster. We can use many independent clusters together in one larger job, achieved with a larger-scale system.
HDFS
As mentioned, HDFS is a primary-secondary topology running on two daemons ? DataNode and NameNode.
The name node stores the metadata where all the data is being stored in the DataNodes. Also, if your NameNode goes down and you don?t have any backup, then your whole Hadoop instance will be unreachable. It?s a bit like losing the pointer when iterating over a linked list. If you don?t know where your data is stored next, you can?t get to it.
The DataNodes, on the other hand, are where the data is actually stored. If any specific DataNode is down, this should be OK because the NameNode will often manage multiple instances of the same blocks of data across data nodes (this is somewhat dependent on configuration).
With the Hadoop Distributed File System you can write data once on the server and then subsequently read over many times. HDFS is a great choice to deal with high volumes of data needed right away.
The reason is that HDFS works with the NameNode and the DataNodes on the commodity of hardware cluster. In fact, this was one of the main reasons Hadoop became popular.
The fact that you could run HDFS across cheap hardware and easily scale horizontally (which refers to buying more machines to handle data processing) has made it a highly popular option. Previously, most companies relied on vertical scaling (buying servers that are often expensive but can individually process more data). This was expensive and had more computational limitations.
HDFS and Hadoop, combined with the other base layer components like MapReduce, have allowed businesses of all sizes and competencies to scale their data processing without purchasing expensive equipment.
HBase
HDFS and Hadoop are somewhat the same and we can understand developers using the terms interchangibly.
However, HBase is very different.
HBase is an open-source, column-oriented database that?s built on top of the Hadoop file system. This is often the layer people are a little more familiar with, in the sense that it is much more similar to a typical database.
It?s horizontally scalable. The data model of HBase is similar to that of Google?s big table design. It not only provides quick random access to great amounts of unstructured data but it also leverages equal fault tolerance as provided by HDFS.
HBase is part of the Hadoop ecosystem that provides read and write access in real-time for data in the Hadoop file system. Many big companies use HBase for their day-to-day functions for the same reason. Pinterest, for instance, works with 38 clusters of HBase to perform around 5 million operations every second!
What?s even greater is the fact that HBase provides lower latency access to single rows from A million number of records. To work, HBase uses hash tables internally and then provides random access to indexed HDFS files.
Hive
While Hadoop is very scalable reliable and great for extracting data, its learning curve is too steep to make it cost-efficient and time-effective. Another great alternative to it is Apache Hive on top of MapReduce.
Hive is a data warehouse software that allows users to quickly and easily write SQL-like queries to extract data from Hadoop.
The main purpose of this open-source framework is to process and store huge amounts of data. In the case of Hadoop, you can implement SQL queries using MapReduce Java API. In the case of Apache Hive you can easily bypass the Java and simply access data using the SQL like queries.
The working of Apache Hive is simple. It translates the input program written in HiveQL into one or more Java a MapReduce and Spark jobs.
It then organizes the data into HDFS tables and runs the jobs on a cluster to produce results. Hive is a simple way to apply structure to large amounts of unstructured data and then perform SQL based queries on them. Since it uses an interface that?s familiar with JDBC (Java Database Connectivity), it can easily integrate with traditional data center technologies.
Some of the most important components of the Hive are:
- MetaStore: This is the schema in which Hive tables are stored. The Hive Metastore is mainly used to hold all information regarding partitions and tables in the warehouse. It runs the same process as Hive service by default.
- SerDe: SerDe or Serializer/Deserializer is a function that gives instructions to the hive regarding how a record is to be processed
These Things Are Not the Same ? But They Work Together
We?ve discussed Hadoop, Hive, HBase, and HDFS. All of these open-source tools and software are designed to help process and store big data and derive useful insights from it.
They?re also often used interchangeably, even though they all play very different roles.
To summarize, Hadoop works as a file storage framework, which in turn uses HDFS as a primary-secondary topology to store files in the Hadoop environment.
HBase then sits on top of HDFS as a column-based distributed database system built like Google?s Big Table ? which is great for randomly accessing Hadoop files. Hive, on the other hand, provides an SQL-like interface based on Hadoop to bypass JAVA coding.
Hopefully, this has helped to clarify some of the differences!


{kind=link}
{kind=link}