This blog post is also part of the series of Deep Learning posts. I wrote two other posts before ? one on Weight Initialization and another one on Language Identification of Text. All the posts are self contained, so you can go ahead and read this one and check-out the others if you like to.
In this post, I will primarily discuss the concept of dropout in neural networks, specifically deep nets, followed by an experiments to see how does it actually influence in practice by implementing a deep net on a standard dataset and seeing the effect of dropout.
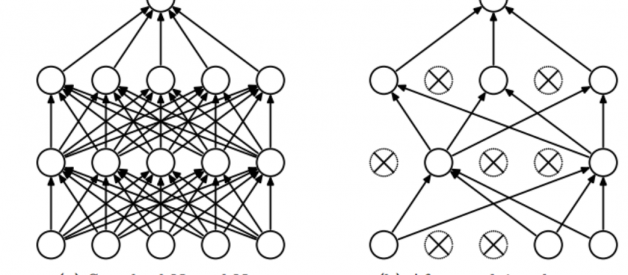
What is Dropout in Neural Networks?
According to Wikipedia ? The term ?dropout? refers to dropping out units (both hidden and visible) in a neural network.
Simply put, dropout refers to ignoring units (i.e. neurons) during the training phase of certain set of neurons which is chosen at random. By ?ignoring?, I mean these units are not considered during a particular forward or backward pass.
More technically, At each training stage, individual nodes are either dropped out of the net with probability 1-p or kept with probability p, so that a reduced network is left; incoming and outgoing edges to a dropped-out node are also removed.
Why do we need Dropout?
Given that we know a bit about dropout, a question arises ? why do we need dropout at all? Why do we need to literally shut-down parts of a neural networks?
The answer to these questions is ?to prevent over-fitting?.
A fully connected layer occupies most of the parameters, and hence, neurons develop co-dependency amongst each other during training which curbs the individual power of each neuron leading to over-fitting of training data.
Dropout ? Revisited
Now that we know a little bit about dropout and the motivation, let?s go into some detail. If you just wanted an overview of dropout in neural networks, the above two sections would be sufficient. In this section, I will touch upon some more technicality.
In machine learning, regularization is way to prevent over-fitting. Regularization reduces over-fitting by adding a penalty to the loss function. By adding this penalty, the model is trained such that it does not learn interdependent set of features weights. Those of you who know Logistic Regression might be familiar with L1 (Laplacian) and L2 (Gaussian) penalties.
Dropout is an approach to regularization in neural networks which helps reducing interdependent learning amongst the neurons.
Training Phase:
Training Phase: For each hidden layer, for each training sample, for each iteration, ignore (zero out) a random fraction, p, of nodes (and corresponding activations).
Testing Phase:
Use all activations, but reduce them by a factor p (to account for the missing activations during training).
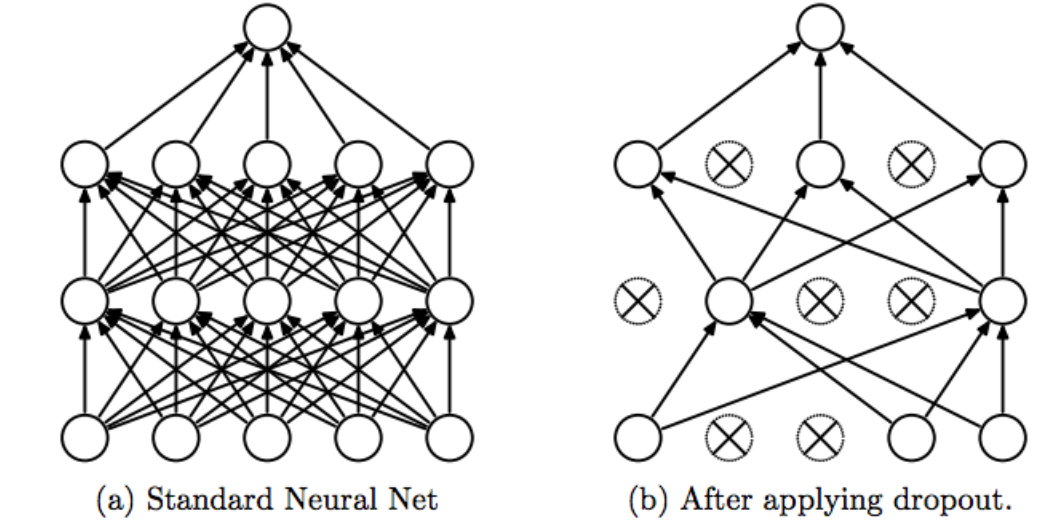 Srivastava, Nitish, et al. ?Dropout: a simple way to prevent neural networks fromoverfitting?, JMLR 2014
Srivastava, Nitish, et al. ?Dropout: a simple way to prevent neural networks fromoverfitting?, JMLR 2014
Some Observations:
- Dropout forces a neural network to learn more robust features that are useful in conjunction with many different random subsets of the other neurons.
- Dropout roughly doubles the number of iterations required to converge. However, training time for each epoch is less.
- With H hidden units, each of which can be dropped, we have2^H possible models. In testing phase, the entire network is considered and each activation is reduced by a factor p.
Experiment in Keras
Let?s try this theory in practice. To see how dropout works, I build a deep net in Keras and tried to validate it on the CIFAR-10 dataset. The deep network is built had three convolution layers of size 64, 128 and 256 followed by two densely connected layers of size 512 and an output layer dense layer of size 10 (number of classes in the CIFAR-10 dataset).
I took ReLU as the activation function for hidden layers and sigmoid for the output layer (these are standards, didn?t experiment much on changing these). Also, I used the standard categorical cross-entropy loss.
Finally, I used dropout in all layers and increase the fraction of dropout from 0.0 (no dropout at all) to 0.9 with a step size of 0.1 and ran each of those to 20 epochs. The results look like this:
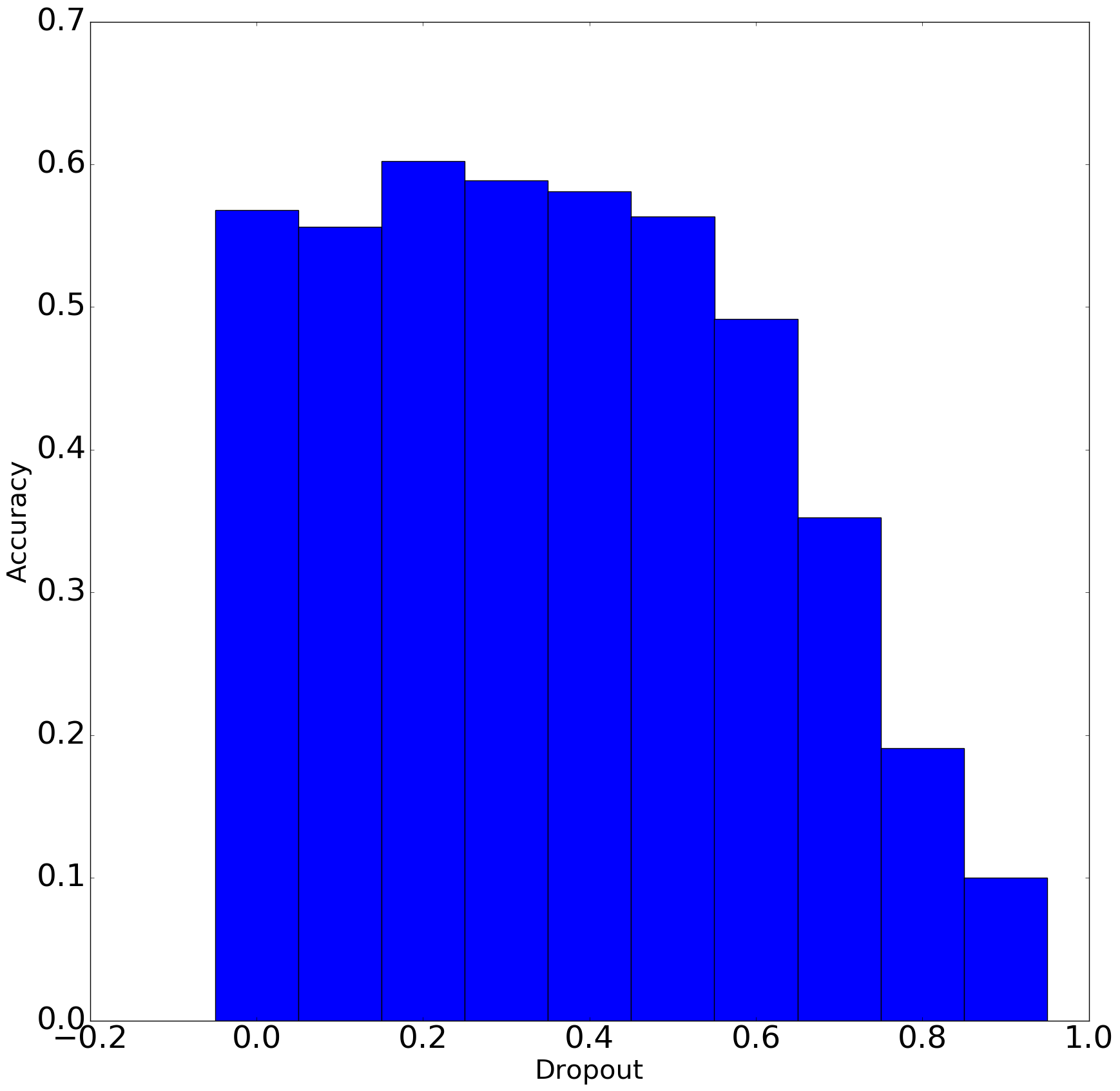
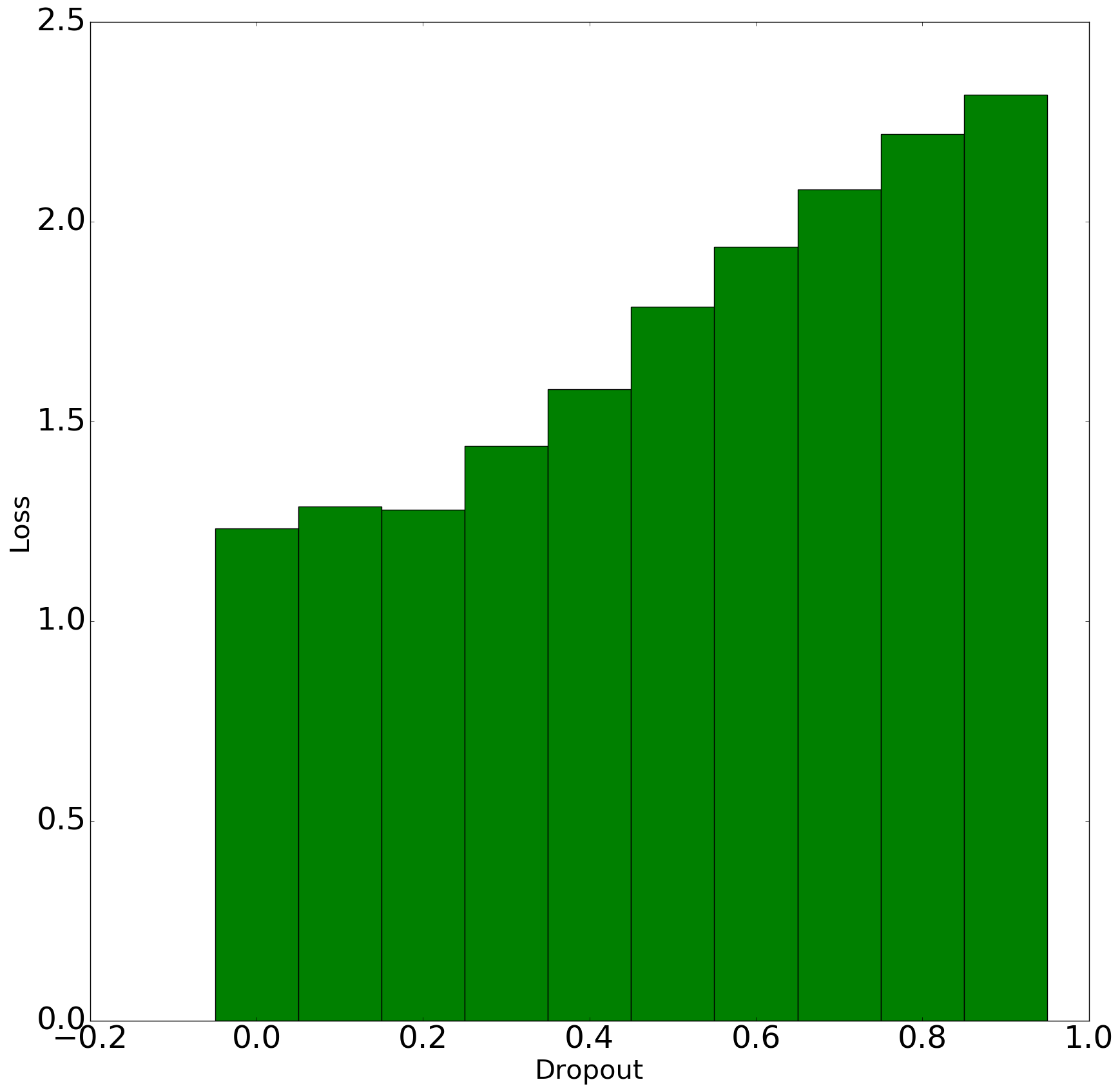 Accuracy vs Dropout (Left) and Loss vs Dropout
Accuracy vs Dropout (Left) and Loss vs Dropout
From the above graphs we can conclude that with increasing the dropout, there is some increase in validation accuracy and decrease in loss initially before the trend starts to go down. There could be two reasons for the trend to go down if dropout fraction is 0.2:
- 0.2 is actual minima for the this dataset, network and the set parameters used
- More epochs are needed to train the networks.
For the code on the Keras experiment, please refer to the jupyter notebook hosted on github.
If you would like to know more about me, please check my LinkedIn profile.
This story was featured on Intel?s blog: https://www.crowdcast.io/e/intel_virtual_lab/registerand on Data Science US -https://www.datascience.us/neural-net-dropout-dealing-overfitting/


 Machine learning){kind=link}
 Machine learning){kind=link}