

Many Supervised and Unsupervised machine learning models such as K-NN and K-Means depend upon the distance between two data points to predict the output. Therefore, the metric we use to compute distances plays an important role in these models.
In this blog post, we are going to learn about some distance metrics used in machine learning models. They are:-
- Minkowski distance
- Manhattan distance
- Euclidean distance
- Hamming distance
- Cosine distance
Minkowski Distance
According to Wikipedia, ?A Normed vector space is a vector space on which a norm is defined.? Suppose A is a vector space then a norm on A is a real-valued function ||A||which satisfies below conditions –
- Zero Vector- Zero vector will have zero length.
- Scalar Factor- The direction of the vector doesn?t change when you multiply it with a positive number though its length will be changed.
- Triangle Inequality- If the distance is a norm then the calculated distance between two points will always be a straight line.
The distance can be calculated using the below formula:-
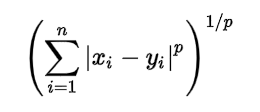
Minkowski distance is a generalized distance metric. We can manipulate the above formula by substituting ?p? to calculate the distance between two data points in different ways. Thus, Minkowski Distance is also known as Lp norm distance.
Some common values of ?p? are:-
- p = 1, Manhattan Distance
- p = 2, Euclidean Distance
- p = infinity, Chebychev Distance
We will discuss these distance metrics below in detail.
Manhattan Distance:
We use Manhattan distance, also known as city block distance, or taxicab geometry if we need to calculate the distance between two data points in a grid-like path. Manhattan distance metric can be understood with the help of a simple example.
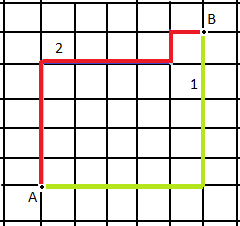
In the above picture, imagine each cell to be a building, and the grid lines to be roads. Now if I want to travel from Point A to Point B marked in the image and follow the red or the yellow path. We see that the path is not straight and there are turns. In this case, we use the Manhattan distance metric to calculate the distance walked.
We can get the equation for Manhattan distance by substituting p = 1 in the Minkowski distance formula. The formula is:-
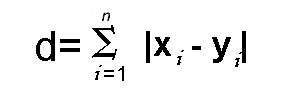
When is Manhattan distance metric preferred in ML?
Quoting from the paper, ?On the Surprising Behavior of Distance Metrics in High Dimensional Space?, by Charu C. Aggarwal, Alexander Hinneburg, and Daniel A. Kiem. ? for a given problem with a fixed (high) value of the dimensionality d, it may be preferable to use lower values of p. This means that the L1 distance metric (Manhattan Distance metric) is the most preferable for high dimensional applications.?
Thus, Manhattan Distance is preferred over the Euclidean distance metric as the dimension of the data increases. This occurs due to something known as the ?curse of dimensionality?. For further details, please visit this link.
Euclidean Distance:
Euclidean distance is the straight line distance between 2 data points in a plane.
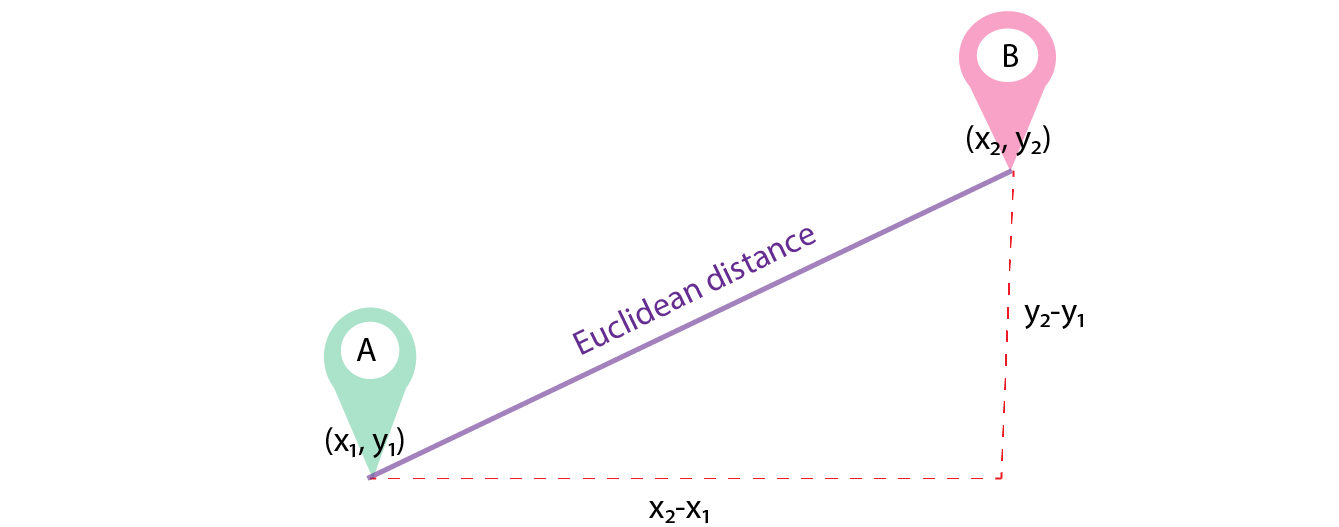
It is calculated using the Minkowski Distance formula by setting ?p? value to 2, thus, also known as the L2 norm distance metric. The formula is:-
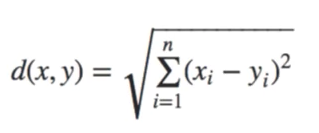
This formula is similar to the Pythagorean theorem formula, Thus it is also known as the Pythagorean Theorem.
Hamming Distance:
Hamming distance is a metric for comparing two binary data strings. While comparing two binary strings of equal length, Hamming distance is the number of bit positions in which the two bits are different.
The Hamming distance between two strings, a and b is denoted as d(a,b).
In order to calculate the Hamming distance between two strings, and, we perform their XOR operation, (a? b), and then count the total number of 1s in the resultant string.
Suppose there are two strings 11011001 and 10011101.
11011001 ? 10011101 = 01000100. Since, this contains two 1s, the Hamming distance, d(11011001, 10011101) = 2.
Cosine Distance & Cosine Similarity:
Cosine distance & Cosine Similarity metric is mainly used to find similarities between two data points. As the cosine distance between the data points increases, the cosine similarity, or the amount of similarity decreases, and vice versa. Thus, Points closer to each other are more similar than points that are far away from each other. Cosine similarity is given by Cos ?, and cosine distance is 1- Cos ?. Example:-
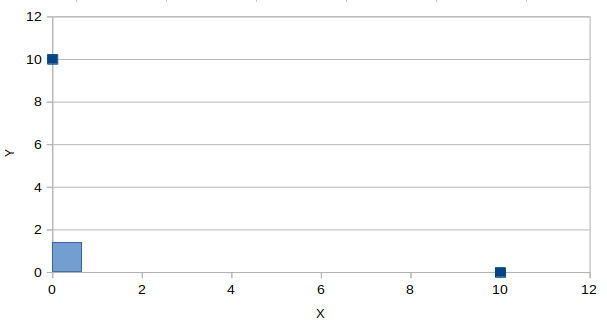 ? = 90
? = 90
In the above image, there are two data points shown in blue, the angle between these points is 90 degrees, and Cos 90 = 0. Therefore, the shown two points are not similar, and their cosine distance is 1 ? Cos 90 = 1.
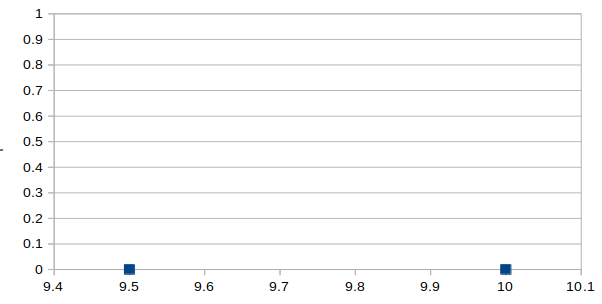 ? = 0
? = 0
Now if the angle between the two points is 0 degrees in the above figure, then the cosine similarity, Cos 0 = 1 and Cosine distance is 1- Cos 0 = 0. Then we can interpret that the two points are 100% similar to each other.
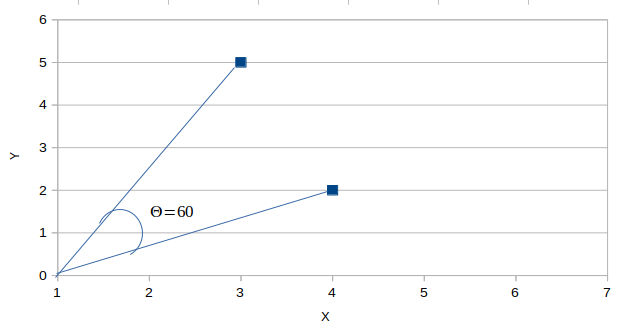
In the above figure, imagine the value of ? to be 60 degrees, then by cosine similarity formula, Cos 60 =0.5 and Cosine distance is 1- 0.5 = 0.5. Therefore the points are 50% similar to each other.
Where is it used?
Cosine metric is mainly used in Collaborative Filtering based recommendation systems to offer future recommendations to users.
Taking the example of a movie recommendation system, Suppose one user (User #1) has watched movies like The Fault in our Stars, and The Notebook, which are of romantic genres, and another user (User #2) has watched movies like The Proposal, and Notting Hill, which are also of romantic genres. So the recommendation system will use this data to recommend User #1 to see The Proposal, and Notting Hill as User #1 and User #2 both prefer the romantic genre and its likely that User #1 will like to watch another romantic genre movie and not a horror one.
Similarly, Suppose User #1 loves to watch movies based on horror, and User #2 loves the romance genre. In this case, User #2 won?t be suggested to watch a horror movie as there is no similarity between the romantic genre and the horror genre.
Conclusion
In this blog post, we read about the various distance metrics used in Machine Learning models. We studied about Minkowski, Euclidean, Manhattan, Hamming, and Cosine distance metrics and their use cases.
Manhattan distance is usually preferred over the more common Euclidean distance when there is high dimensionality in the data. Hamming distance is used to measure the distance between categorical variables, and the Cosine distance metric is mainly used to find the amount of similarity between two data points.


{kind=link}
{kind=link}