What Is Database Architecture?
Database architecture uses programming languages to design a particular type of software for businesses or organizations.Database architecture focuses on the design, development, implementation and maintenance of computer programs that store and organize information for businesses, agencies and institutions. A database architect develops and implements software to meet the needs of users.
The design of a DBMS depends on its architecture. It can be centralized or decentralized or hierarchical. The architecture of a DBMS can be seen as either single tier or multi-tier. The tiers are classified as follows :
- 1-tier architecture
- 2-tier architecture
- 3-tier architecture
- n-tier architecture
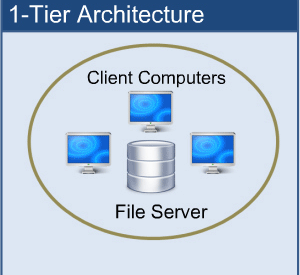
1-tier architecture:
One-tier architecture involves putting all of the required components for a software application or technology on a single server or platform.
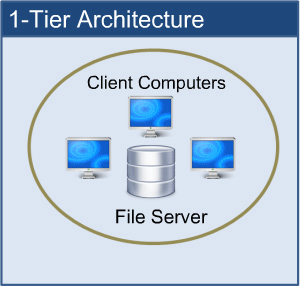 1-tier architecture
1-tier architecture
Basically, a one-tier architecture keeps all of the elements of an application, including the interface, Middleware and back-end data, in one place. Developers see these types of systems as the simplest and most direct way.
2-tier architecture:
The two-tier is based on Client Server architecture. The two-tier architecture is like client server application. The direct communication takes place between client and server. There is no intermediate between client and server.
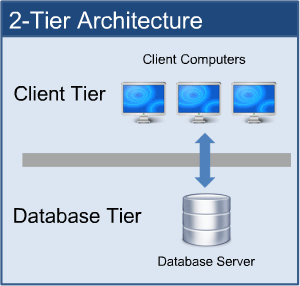 2-tier architecture
2-tier architecture
3-tier architecture:
A 3-tier architecture separates its tiers from each other based on the complexity of the users and how they use the data present in the database. It is the most widely used architecture to design a DBMS.
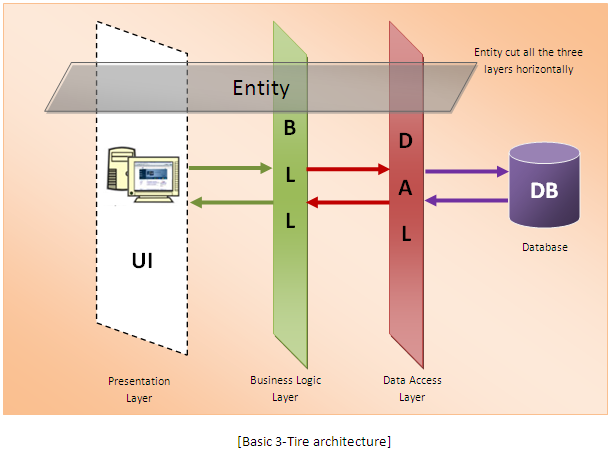 3-tier architecture
3-tier architecture
This architecture has different usages with different applications. It can be used in web applications and distributed applications. The strength in particular is when using this architecture over distributed systems.
- Database (Data) Tier ? At this tier, the database resides along with its query processing languages. We also have the relations that define the data and their constraints at this level.
- Application (Middle) Tier ? At this tier reside the application server and the programs that access the database. For a user, this application tier presents an abstracted view of the database. End-users are unaware of any existence of the database beyond the application. At the other end, the database tier is not aware of any other user beyond the application tier. Hence, the application layer sits in the middle and acts as a mediator between the end-user and the database.
- User (Presentation) Tier ? End-users operate on this tier and they know nothing about any existence of the database beyond this layer. At this layer, multiple views of the database can be provided by the application. All views are generated by applications that reside in the application tier.
n-tier architecture:
N-tier architecture would involve dividing an application into three different tiers. These would be the
- logic tier,
- the presentation tier, and
- the data tier.
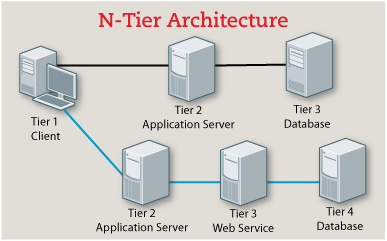 n-tier architecture
n-tier architecture
It is the physical separation of the different parts of the application as opposed to the usually conceptual or logical separation of the elements in the model-view-controller (MVC) framework. Another difference from the MVC framework is that n-tier layers are connected linearly, meaning all communication must go through the middle layer, which is the logic tier. In MVC, there is no actual middle layer because the interaction is triangular; the control layer has access to both the view and model layers and the model also accesses the view; the controller also creates a model based on the requirements and pushes this to the view. However, they are not mutually exclusive, as the MVC framework can be used in conjunction with the n-tier architecture, with the n-tier being the overall architecture used and MVC used as the framework for the presentation tier.
Normalization of Database:
Database Normalisation is a technique of organizing the data in the database. Normalization is a systematic approach of decomposing tables to eliminate data redundancy and undesirable characteristics like Insertion, Update and Deletion Anamolies. It is a multi-step process that puts data into tabular form by removing duplicated data from the relation tables.
Normalization is used for mainly two purpose,
- Eliminating reduntant(useless) data.
- Ensuring data dependencies make sense i.e data is logically stored.
Problem Without Normalization:
Without Normalization, it becomes difficult to handle and update the database, without facing data loss. Insertion, Updation and Deletion Anamolies are very frequent if Database is not Normalized.
Normalization Rule:
Normalization rule are divided into following normal form.
- First Normal Form
- Second Normal Form
- Third Normal Form
- BCNF
First Normal Form:
A database is in first normal form if it satisfies the following conditions:
- Contains only atomic values
- There are no repeating groups
An atomic value is a value that cannot be divided. For example, in the table shown below, the values in the [Color] column in the first row can be divided into ?red? and ?green?, hence [TABLE_PRODUCT] is not in 1NF.
A repeating group means that a table contains two or more columns that are closely related. For example, a table that records data on a book and its author(s) with the following columns: [Book ID], [Author 1], [Author 2], [Author 3] is not in 1NF because [Author 1], [Author 2], and [Author 3] are all repeating the same attribute.
1st Normal Form Example
How do we bring an unnormalized table into first normal form? Consider the following example:
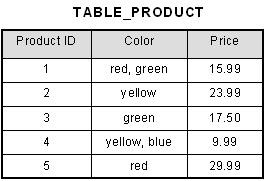
This table is not in first normal form because the [Color] column can contain multiple values. For example, the first row includes values ?red? and ?green.?
To bring this table to first normal form, we split the table into two tables and now we have the resulting tables:
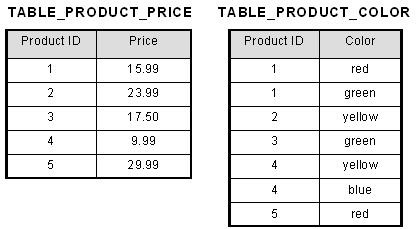
Now first normal form is satisfied, as the columns on each table all hold just one value.
Second Normal Form:
A database is in second normal form if it satisfies the following conditions:
- It is in first normal form
- All non-key attributes are fully functional dependent on the primary key
In a table, if attribute B is functionally dependent on A, but is not functionally dependent on a proper subset of A, then B is considered fully functional dependent on A. Hence, in a 2NF table, all non-key attributes cannot be dependent on a subset of the primary key. Note that if the primary key is not a composite key, all non-key attributes are always fully functional dependent on the primary key. A table that is in 1st normal form and contains only a single key as the primary key is automatically in 2nd normal form.
2nd Normal Form Example
Consider the following example:
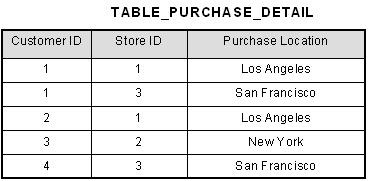
This table has a composite primary key [Customer ID, Store ID]. The non-key attribute is [Purchase Location]. In this case, [Purchase Location] only depends on [Store ID], which is only part of the primary key. Therefore, this table does not satisfy second normal form.
To bring this table to second normal form, we break the table into two tables, and now we have the following:
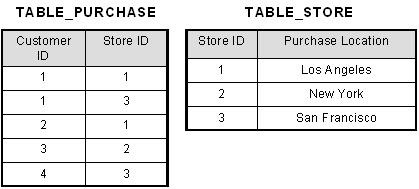
What we have done is to remove the partial functional dependency that we initially had. Now, in the table [TABLE_STORE], the column [Purchase Location] is fully dependent on the primary key of that table, which is [Store ID].
Third Normal Form:
A relation is in third normal form if it is in 2NF and no non key attribute is transitively dependent on the primary key.
A bank uses the following relation:
Vendor(ID, Name, Account_No, Bank_Code_No, Bank)
The attribute ID is the identification key. All attributes are single valued (1NF). The table is also in 2NF.
The following dependencies exist:
1. Name, Account_No, Bank_Code_No are functionally dependent on ID (ID ? Name, Account_No, Bank_Code_No)
2. Bank is functionally dependent on Bank_Code_No (Bank_Code_No ? Bank)
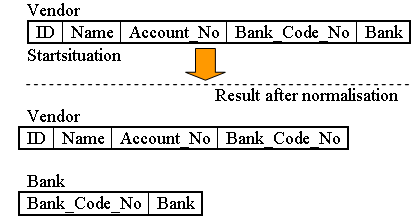
The table in this example is in 1NF and in 2NF. But there is a transitive dependency between Bank_Code_No and Bank, because Bank_Code_No is not the primary key of this relation. To get to the third normal form (3NF), we have to put the bank name in a separate table together with the clearing number to identify it.
BCNF:
BCNF was developed by Raymond Boyce and E.F. Codd; the latter is widely considered the father of relational database design.
BCNF is really an extension of 3rd Normal Form (3NF). For this reason it is frequently termed 3.5NF. 3NF states that all data in a table must depend only on that table?s primary key, and not on any other field in the table. At first glance it would seem that BCNF and 3NF are the same thing. However, in some rare cases it does happen that a 3NF table is not BCNF-compliant. This may happen in tables with two or more overlapping composite candidate keys.

{kind=link}
{kind=link}