
Explaining Key SQL Performance Improvement Concept & When To Create Which Index
Data scientists are constantly working with the data. Productivity is crucial for the data experts. Loading, manipulating and retrieving data is a daily task and occasionally improving its performance is overlooked. The read/write data operations can take a long time to perform which can badly impact the delivery. We can speed up the productivity by introducing indexes on the tables.
This article aims to illustrate what clustered and non clustered indexes are, including when to create them with the use of examples.
Article Aim
This article will focus on explaining following areas:
- What is a clustered index?
- What is a non clustered index?
- When to create a clustered index?
- When to create a non clustered index?
- How to create a clustered index?
- How to create a non clustered index?
- Issues with indexes
- Example
 Photo by Jan Antonin Kolar on Unsplash
Photo by Jan Antonin Kolar on Unsplash
What Is A Clustered Index?
A clustered index:
- Physically orders the data according to the columns of the index.
- Therefore, when we create a clustered index, we are essentially physically ordering the rows of the table. As a result, the clustered index contains all of the columns of a row.
- There can only be one clustered index on a table as the rows in the table will be sorted by the order specified in the clustered index.
- This means that whenever you insert or update a record, the clustered index ensures that the order is maintained. This process can be a hit on the performance of your application.
- For the tables without a clustered index, data is stored in an unordered heap. Heaps do not have an ordered structure, they do not have a natural order. This can get problematic as the table grows in size and data gets fragmented over time.
If you want fast performant read-only applications that require all of the columns of a table then implement a clustered index on the table
- Clustered indexes are stored as trees. With clustered index, the actual data is stored in the leaf nodes. This can speed up getting the data when a lookup is performed on the index. As a consequence, a lower number of IO operations are required.
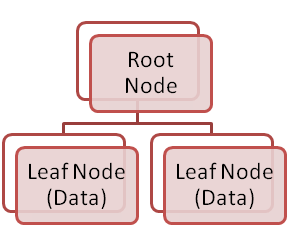 I have omitted the non-leaf intermediate nodes for the sake of simplicity
I have omitted the non-leaf intermediate nodes for the sake of simplicity
- Additionally the index can be reorganised and rebuilt without moving the data out into a new table.
- SQL Server automatically creates a Primary key constraint on a clustered index. Having said that, the primary key constraint can be removed. Primary key should uniquely identify a row.
Think of a clustered index as the actual table stored in your specified way
 Photo by Patrick Tomasso on Unsplash
Photo by Patrick Tomasso on Unsplash
What Is A Non-Clustered Index?
Non-Clustered Index is:
- Also known as B-Tree index.
- The data is ordered in a logical manner in a non-clustered index. The rows can be stored physically in a different order than the columns in a non-clustered index. Therefore, the index is created and the data in the index is ordered logically by the columns of the index.
- Non clustered indexes are created on top of the actual data.
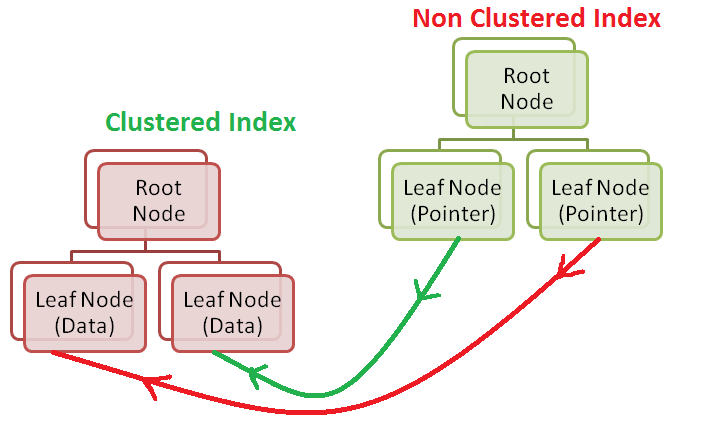
- Unlike clustered index, the leaf pages of the index do not contain the actual data. The leaf pages of the non clustered index contain the pointers.
 I have omitted the non-leaf intermediate nodes for the sake of simplicity
I have omitted the non-leaf intermediate nodes for the sake of simplicity
- These pointers point to the clustered index leaf nodes. They contain the address of the required row.
Pointers are like the page numbers in the Index page of a book.
- Remember the leaf nodes of a clustered index store the actual data.
- If a clustered index does not exist in a table then the leaf nodes of a non clustered index points to the heap page where the data is stored. Heap is essentially an unordered (randomly ordered) rows of data.
- Therefore when we query for data, first the non-clustered index is searched to get the address of the data and then the lookup is performed on the clustered index to get the data. Hence this makes the non-clustered index usually slower than the clustered index.
- There can be multiple non-clustered indexes in a table.
Although the rows in the table are physically ordered as specified by the order of the clustered index but the non-clustered index contains unique values of columns in the order that is specifiedfortheindex,andtheycontainpointerstotheactualdata. Think of non clustered index as a dictionary of a table.
 Photo by Kari Shea on Unsplash
Photo by Kari Shea on Unsplash
When Should We Create A Clustered Index?
Note, always execute your query and analyse the execution plan to understand where the performance bottle-necks are but it is wise to create clustered index when:
- Your query contains filters on specific columns such as WHERE clauses or on JOINS and you are required to query those columns over and over again. Additionally, the requirement is that these columns are not updated as frequently.
- When you are always required to return data in an ordered manner then you can create a clustered index with the required columns of the ORDER BY clause. As a consequence, all of the rows of the table are not required to be scanned.
- If your application performs a large number of reads on a table then the clustered index will make the operation extremely fast.
- Your queries SELECT all or most of the columns of a table then you can think of creating a clustered index.
 Photo by Dollar Gill on Unsplash
Photo by Dollar Gill on Unsplash
When Should We Create A Non-Clustered Index?
Note, always execute your query and analyse the execution plan to understand where the performance bottle-necks are but it is wise to create a non-clustered index when:
- Multiple queries are required to filter rows on a table and there are different set of columns which are used in the WHERE clause and JOINS. Additionally, these columns are updated frequently.
- Again, if you are constantly returning data in specific order then create a non-clustered index to speed up the performance. It will also reduce the memory footprint as you will not be required to perform an additional sorting.
- If certain columns are used more frequently in the queries then you can create a non clustered index on the tables. This is known as the Cover Non Clustered Index.
- If you want to create an index on only those rows that meet a specific criteria then you can add a WHERE clause in the non clustered index. This is known as a Filter Non Clustered Index.
- We can also INCLUDE the columns that we need in the SELECT statement to be added as leaf nodes in the non clustered index. It speeds up the retrieval time.
 Photo by Jonas Jacobsson on Unsplash
Photo by Jonas Jacobsson on Unsplash
How to create a clustered index
Creating a clustered index can be achieved in two ways:
- Create a primary key constraint, or
- Use the create index statement.
— Via primary key constraintALTER TABLE FinTechExplained.Trade ADD CONSTRAINT PK_Trade_TradeIdPRIMARY KEY CLUSTERED (TradeId ASC, TradeType ASC);– using create index statementCREATE CLUSTERED INDEX IX_Trade_TradeId ON FinTechExplained.Trade(TradeId ASC, TradeType ASC);
How to create a non-clustered index
You can create a non-clustered index in two ways:
- By using the NonClustered keyword
- Without using the NonClustered Index
— By using the non-clustered indexCREATE NONCLUSTERED INDEX IX_Trade_CreatedAtCreatedBy ON FinTechExplained.Trade(CreatedAt ASC,CreatedBy ASC);CREATE INDEX IX_Trade_CreatedAtCreatedBy ON FinTechExplained.Trade (CreatedAt ASC,CreatedBy ASC); Photo by Daria Nepriakhina on Unsplash
Photo by Daria Nepriakhina on Unsplash
Issues With Creating Indexes
Sometimes the existences of indexes can badly impact the performance.
- Indexes take space on disk and can impact the memory footprint of the SQL process. The clustered index does not take as much space as the non-clustered index does because the non clustered index are stored in a separate space on the disk.
- Clustered index are useful if you are performing a large number of reads but for every insert, the data needs to be shuffled and re-ordered. Hence they are not appropriate for tables that require fast inserts. Matter of fact, if you want fast inserts then remove all of the indexes.
- Clustered indexes are not useful if you need to perform ORDER BY on different set of columns than the columns of the clustered index.
- Non-clustered indexes need to be carefully designed because if you include only sub-set of the columns then the index will not be as useful than it would be if you were to include all of the required columns. Having said that, more the columns, larger the index and more the space it consumes on disk. If you create two non clustered indexes that contain a column then you will be duplicating the unique values of that column. This in turn will consume more space on the disk.
- Too many indexes can destroy the performance. Let?s assume you create two non-clustered indexes where the first non-clustered index is on columns A and B of a table and the second non clustered index is on columns B, C and D of a table. If you query for columns A, C and D then SQL will be using the two indexes to get the required pointers and then it will lookup for the data in the table. This will badly impact the performance of the queries.
- If you need to bulk import data into a staging table then it will very likely be better if you do not create indexes at all as indexes can impact the performance.
 Photo by NeONBRAND on Unsplash
Photo by NeONBRAND on Unsplash
Let?s Understand With An Example
Imagine Trades is a table in your database. The full name of the table is FinTechExplained.Trades.
The table contains a large number of columns but for the sake of simplicity, assume it contains following key columns:
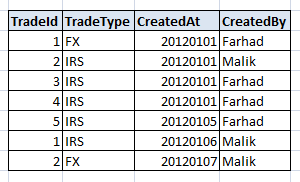
- Let?s also consider that the combination of TradeId and TradeType makes each row unique and most of the queries require us to get the trades based on the trade Id and Trade Type. Additionally the natural order of the trades is based on the TradeId and TradeType.
- Therefore we can create a Clustered Index on the TradeId and TradeType columns:
— using create index statementCREATE CLUSTERED INDEX IX_Trade_TradeId ON FinTechExplained.Trade(TradeId ASC, TradeType ASC);
- The clustered index IX_Trade_TradeId will store the trades in the leaf node of the index, ordered by the TradeId and TradeType columns. It implies that the rows of the Trade table will be physically ordered by TradeId and TradeType.
2. A large number of queries require us to return the Created at column of the trades. Additionally the queries occasionally pass in the required Created at and Created by values in the filter clause. Therefore we can create a non-clustered index:
CREATE INDEX IX_Trade_CreatedAtCreatedBy ON FinTechExplained.Trade (CreatedAt ASC,CreatedBy ASC) INCLUDE (CreatedAt)
- Because we have INCLUDE in our non clustered index, the leaf node will contain the values of the CreatedAt column.
- If a large number of queries require us to return the trades that were created by Farhad then we can create a filter non clustered index:
CREATE INDEX IX_Trade_FarhadCreatedBy ON FinTechExplained.Trade (CreatedAt ASC,CreatedBy ASC) where createdBy=’Farhad’
- The WHERE clause in the index will create a non clustered index for rows where CreatedBY meets the required criteria.
Summary
This article aimed to illustrate what clustered and non clustered indexes are. It also explained the details with the use of examples.
Additionally it explained when to create the indexes and the problems of creating the indexes. Always run the SQL execution plans to analyse the queries.
Hope it helps.


{kind=link}
{kind=link}