

Cloning a voice typically requires collecting hours of recorded speech to build a dataset then using the dataset to train a new voice model. But not anymore. A new Github project introduces a remarkable Real-Time Voice Cloning Toolbox that enables anyone to clone a voice from as little as five seconds of sample audio.
This Github repository was open sourced this June as an implementation of the paper Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS) with a vocoder that works in real-time. The project was developed by Corentin Jemine, who got his Masters in Data Science at the University of Lige and works as a machine learning engineer at Resemble AI in Toronto.
Users input a short voice sample and the model ? trained only during playback time ? can immediately deliver text-to-speech utterances in the style of the sampled voice. The project has received rave reviews and earned over 6,000 GitHub stars and 700 forks.
The initial interface of the SV2TTS toolbox is shown below. Users can play a voice audio file of about five seconds selected randomly from the dataset, or use their own audio clip.
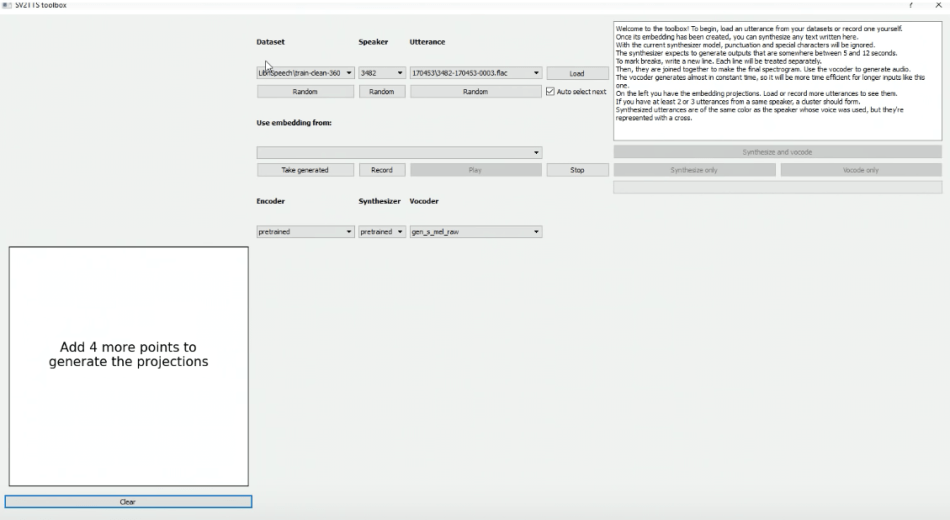
A mel spectrogram and its corresponding embeddings of the utterance will be generated after clicking the ?load? button.
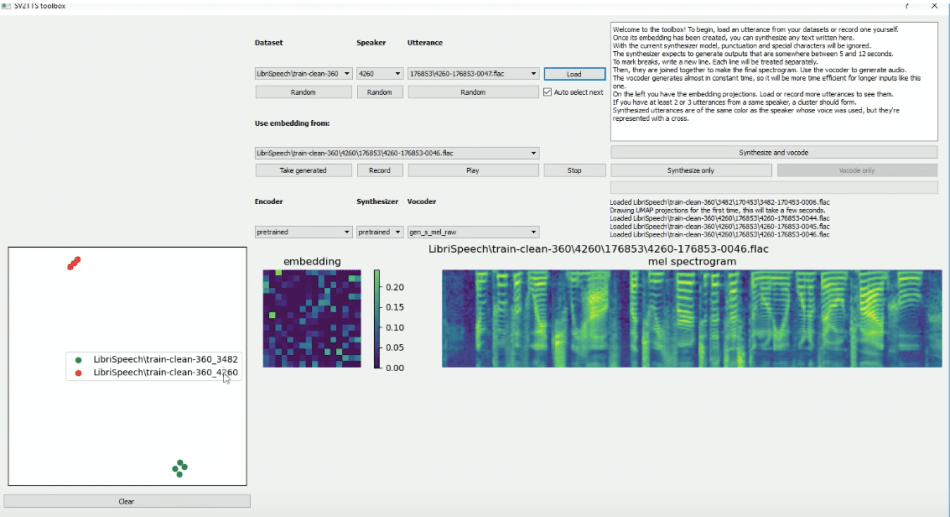
Although a single short sample produces an impressive cloned voice, the results quickly improve when training involves at least three utterances. As additional utterances from the same speaker are input they form a cluster of difference embeddings which users can observe via a mapping display in the interface.
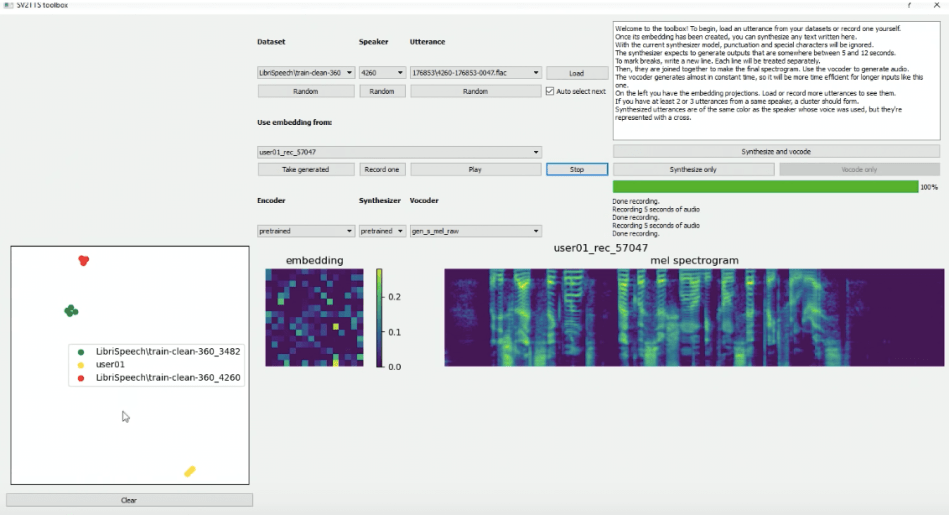
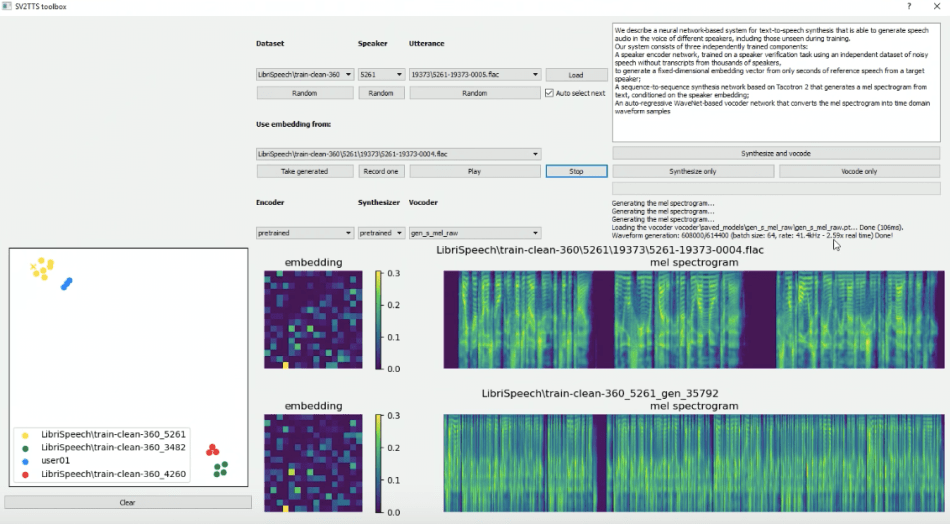
Each speaker?s embeddings can be applied to synthetically voice a random utterance, or users can input their own texts and the model will voice them.
Voice cloning technology is relatively accessible on the Internet today. Montreal-based AI startup Lyrebird provides an online platform that can mimic a person?s mimics speech when trained on 30 or more recordings. Baidu last year introduced a new neural voice cloning system that synthesizes a person?s voice from only a few audio samples.
Corentin Jemine?s novel repository provides a self-developed framework with a three-stage pipeline implemented from earlier research work, including SV2TTS, WaveRNN, Tacotron 2, and GE2E.
The GitHub repository includes related papers, updates, and a quick guide on how to set up the toolbox.
Author: Reina Qi Wan | Editor: Michael Sarazen
We know you don?t want to miss any stories. Subscribe to our popular Synced Global AI Weekly to get weekly AI updates.

Need a comprehensive review of the past, present and future of modern AI research development? Trends of AI Technology Development Report is out!
2018 Fortune Global 500 Public Company AI Adaptivity Report is out!Purchase a Kindle-formatted report on Amazon. Apply for Insight Partner Program to get a complimentary full PDF report



{kind=link}
{kind=link}