

Random Forest Classifier is ensemble algorithm. In next one or two posts we shall explore such algorithms. Ensembled algorithms are those which combines more than one algorithms of same or different kind for classifying objects. For example, running prediction over Naive Bayes, SVM and Decision Tree and then taking vote for final consideration of class for test object.
 Machine Learning is a reason why data is important asset for company.
Machine Learning is a reason why data is important asset for company.
In this article, we shall see mathematics behind the Random Forest Classifier. Then we shall code a small example to classify emails into spam or ham. We shall check accuracy compared to previous classifiers.
If you haven?t read already about Decision Tree Classifier, I would suggest you to go through it once here as they are the underlying concept for Random Forest Classifier.
Random Forest Classifier
Random forest classifier creates a set of decision trees from randomly selected subset of training set. It then aggregates the votes from different decision trees to decide the final class of the test object.
In Laymen?s term,
Suppose training set is given as : [X1, X2, X3, X4] with corresponding labels as [L1, L2, L3, L4], random forest may create three decision trees taking input of subset for example,
- [X1, X2, X3]
- [X1, X2, X4]
- [X2, X3, X4]
So finally, it predicts based on the majority of votes from each of the decision trees made.
This works well because a single decision tree may be prone to a noise, but aggregate of many decision trees reduce the effect of noise giving more accurate results.
The subsets in different decision trees created may overlap
Alternative implementation for voting
Alternatively, the random forest can apply weight concept for considering the impact of result from any decision tree. Tree with high error rate are given low weight value and vise versa. This would increase the decision impact of trees with low error rate.
Basic Parameters
Basic parameters to Random Forest Classifier can be total number of trees to be generated and decision tree related parameters like minimum split, split criteria etc.
Sklearn in python has plenty of tuning parameters that you can explore here.
Don?t forget to click the heart(?) icon.
Random Forest and Sklearn in Python (Coding example).

Lets try out RandomForestClassifier on our previous code of classifying emails into spam or ham.
0. Download
I have created a git repository for the data set and the sample code. You can download it from here (Use chapter 5 folder). Its same data set discussed in this chapter. I would suggest you to follow through the discussion and do the coding yourself. In case it fails, you can use/refer my version to understand working.
1. Little bit about cleaning and extracting the features
You may skip this part if you have already gone through coding part of Naive Bayes.(this is for readers who have directly jumped here).
Before we can apply the sklearn classifiers, we must clean the data. Cleaning involves removal of stop words, extracting most common words from text etc. In the code example concerned we perform following steps:
To understand in detail, once again please refer to chapter 1 coding part here.
- Build dictionary of words from email documents from training set.
- Consider the most common 3000 words.
- For each document in training set, create a frequency matrix for these words in dictionary and corresponding labels. [spam email file names start with prefix ?spmsg?.
The code snippet below does this:def make_Dictionary(root_dir): all_words = emails = [os.path.join(root_dir,f) for f in os.listdir(root_dir)] for mail in emails: with open(mail) as m: for line in m: words = line.split() all_words += words dictionary = Counter(all_words)# if you have python version 3.x use commented version. # list_to_remove = list(dictionary) list_to_remove = dictionary.keys()for item in list_to_remove: # remove if numerical. if item.isalpha() == False: del dictionary[item] elif len(item) == 1: del dictionary[item] # consider only most 3000 common words in dictionary.dictionary = dictionary.most_common(3000)return dictionarydef extract_features(mail_dir): files = [os.path.join(mail_dir,fi) for fi in os.listdir(mail_dir)] features_matrix = np.zeros((len(files),3000)) train_labels = np.zeros(len(files)) count = 0; docID = 0; for fil in files: with open(fil) as fi: for i,line in enumerate(fi): if i == 2: words = line.split() for word in words: wordID = 0 for i,d in enumerate(dictionary): if d[0] == word: wordID = i features_matrix[docID,wordID] = words.count(word) train_labels[docID] = 0; filepathTokens = fil.split(‘/’) lastToken = filepathTokens[len(filepathTokens) – 1] if lastToken.startswith(“spmsg”): train_labels[docID] = 1; count = count + 1 docID = docID + 1 return features_matrix, train_labels
2. Using Random Forest Classifier
The code for using Random Forest Classifier is similar to previous classifiers.
- Import library
- Create model
- Train
- Predict
from sklearn.ensemble import RandomForestClassifierTRAIN_DIR = “../train-mails”TEST_DIR = “../test-mails”dictionary = make_Dictionary(TRAIN_DIR)print “reading and processing emails from file.”features_matrix, labels = extract_features(TRAIN_DIR)test_feature_matrix, test_labels = extract_features(TEST_DIR)model = RandomForestClassifier()print “Training model.”#train modelmodel.fit(features_matrix, labels)predicted_labels = model.predict(test_feature_matrix)print “FINISHED classifying. accuracy score : “print accuracy_score(test_labels, predicted_labels)
Try this out and check what is the accuracy? You will get accuracy around 95.7%. That?s pretty good compared to previous classifiers. Isn?t it?
3. Parameters
Lets understand and play with some of the tuning parameters.
n_estimators : Number of trees in forest. Default is 10.
criterion: ?gini? or ?entropy? same as decision tree classifier.
min_samples_split: minimum number of working set size at node required to split. Default is 2.
You can view full list of tunable parameters here
Play with these parameters by changing values individually and in combination and check if you can improve accuracy.
I tried following combination and obtained the accuracy as shown in image below.
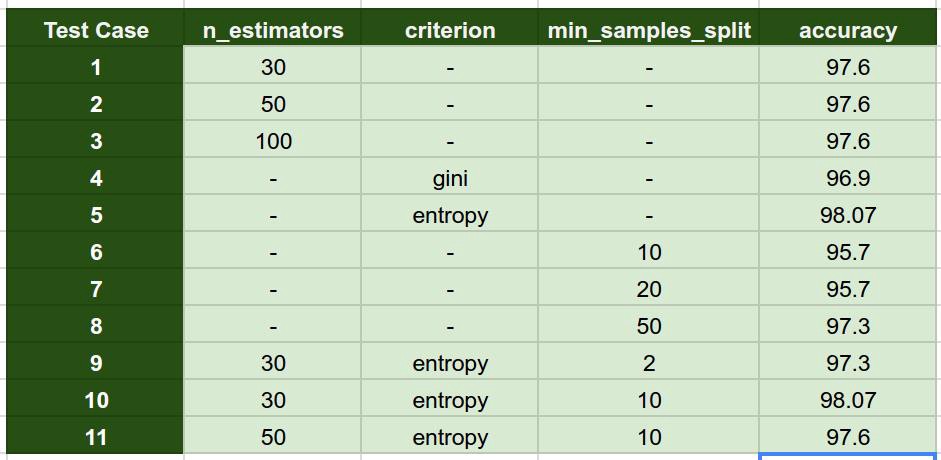
Final Thoughts
Random Forest Classifier being ensembled algorithm tends to give more accurate result. This is because it works on principle,
Number of weak estimators when combined forms strong estimator.
Even if one or few decision trees are prone to a noise, overall result would tend to be correct. Even with small number of estimators = 30 it gave us high accuracy as 97%.
If you liked this post, share with your interest group, friends and colleagues. Comment down your thoughts, opinions and feedback below. I would love to hear from you. Follow machine-learning-101 for regular updates. Don?t forget to click the heart(?) icon.
You can write to me at [email protected] . Peace.



{kind=link}
{kind=link}