

Categorizing and POS Tagging with NLTK Python
Natural language processing is a sub-area of computer science, information engineering, and artificial intelligence concerned with the interactions between computers and human (native) languages. This is nothing but how to program computers to process and analyze large amounts of natural language data.
NLP = Computer Science + AI + Computational Linguistics
In another way, Natural language processing is the capability of computer software to understand human language as it is spoken. NLP is one of the component of artificial intelligence (AI).
About NLTK :
- The Natural Language Toolkit, or more commonly NLTK, is a suite of libraries and programs for symbolic and statistical natural language processing (NLP) for English written in the Python programming language.
- It was developed by Steven Bird and Edward Loper in the Department of Computer and Information Science at the University of Pennsylvania.
- A software package for manipulating linguistic data and performing NLP tasks.
- NLTK is intended to support research and teaching in NLP or closely related areas, including empirical linguistics, cognitive science, artificial intelligence, information retrieval, and machine learning
- NLTK supports classification, tokenization, stemming, tagging, parsing, and semantic reasoning functionalities.
- NLTK includes more than 50 corpora and lexical sources such as the Penn Treebank Corpus, Open Multilingual Wordnet, Problem Report Corpus, and Lin?s Dependency Thesaurus.
The process of classifying words into their parts of speech and labelling them accordingly is known as part-of-speech tagging, POS-tagging, or simply tagging. Parts of speech are also known as word classes or lexical categories. The collection of tags used for a particular task is known as a tag set.
Using a Tagger

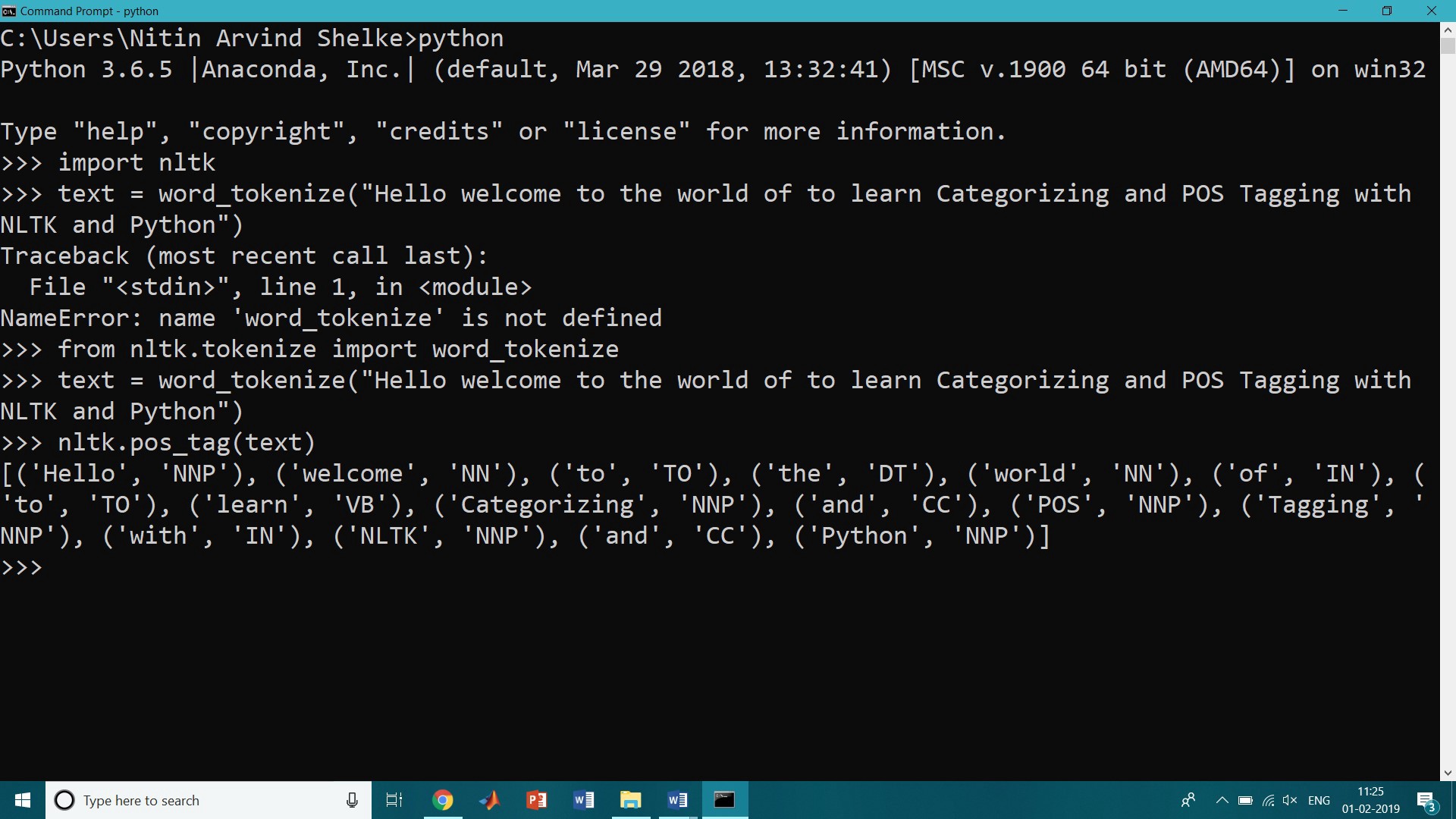
A part-of-speech tagger, or POS-tagger, processes a sequence of words and attaches a part of speech tag to each word. To do this first we have to use tokenization concept (Tokenization is the process by dividing the quantity of text into smaller parts called tokens.)
>>> import nltk>>>from nltk.tokenize import word_tokenize>>> text = word_tokenize(“Hello welcome to the world of to learn Categorizing and POS Tagging with NLTK and Python”)>>> nltk.pos_tag(text)
OUTPUT:
[(‘Hello’, ‘NNP’), (‘welcome’, ‘NN’), (‘to’, ‘TO’), (‘the’, ‘DT’), (‘world’, ‘NN’), (‘of’, ‘IN’), (‘to’, ‘TO’), (‘learn’, ‘VB’), (‘Categorizing’, ‘NNP’), (‘and’, ‘CC’), (‘POS’, ‘NNP’), (‘Tagging’, ‘NNP’), (‘with’, ‘IN’), (‘NLTK’, ‘NNP’), (‘and’, ‘CC’), (‘Python’, ‘NNP’)]
In the above output and is CC, coordinating conjunction;
Learn is VB or verbs;
for is IN, a preposition;
NLTK provides documentation for each tag, which can be queried using the tag,
>>> nltk.help.upenn_tagset(?RB?)
RB: adverb
occasionally unabatingly maddeningly adventurously professedly
stirringly prominently technologically magisterially predominately
swiftly fiscally pitilessly ?
>>> nltk.help.upenn_tagset(?RB?)
RB: adverb
occasionally unabatingly maddeningly adventurously professedly
stirringly prominently technologically magisterially predominately
swiftly fiscally pitilessly ?
>>> nltk.help.upenn_tagset(?NN?)
NN: noun, common, singular or mass
common-carrier cabbage knuckle-duster Casino afghan shed thermostat
investment slide humour falloff slick wind hyena override sub humanity
machinist ?
>>> nltk.help.upenn_tagset(?NNP?)
NNP: noun, proper, singular
Motown Venneboerger Czestochwa Ranzer Conchita Trumplane Christos
Oceanside Escobar Kreisler Sawyer Cougar Yvette Ervin ODI Darryl CTCA
Shannon A.K.C. Miltex Liverpool ?
>>> nltk.help.upenn_tagset(?CC?)
CC: conjunction, coordinating
& ?n and both but either et for less minus neither nor or plus so
therefore times v. versus vs. whether yet
>>> nltk.help.upenn_tagset(?DT?)
DT: determiner
all an another any both del each either every half la many much nary
neither no some such that them these this those
>>> nltk.help.upenn_tagset(?TO?)
TO: ?to? as preposition or infinitive marker
to
>>> nltk.help.upenn_tagset(?VB?)
VB: verb, the base form
ask assemble assess assign assume atone attention avoid bake balkanize
bank begin to behold believe bend benefit bevel beware bless boil bomb
boost brace break brings broil brush build ?
The POS tagger in the NLTK library outputs specific tags for certain words. The list of POS tags is as follows, with examples of what each POS stands for.
- CC coordinating conjunction
- CD cardinal digit
- DT determiner
- EX existential there (like: ?there is? ? think of it like ?there exists?)
- FW foreign word
- IN preposition/subordinating conjunction
- JJ adjective ?big?
- JJR adjective, comparative ?bigger?
- JJS adjective, superlative ?biggest?
- LS list marker 1)
- MD modal could, will
- NN noun, singular ?desk?
- NNS noun plural ?desks?
- NNP proper noun, singular ?Harrison?
- NNPS proper noun, plural ?Americans?
- PDT predeterminer ?all the kids?
- POS possessive ending parent?s
- PRP personal pronoun I, he, she
- PRP$ possessive pronoun my, his, hers
- RB adverb very, silently,
- RBR adverb, comparative better
- RBS adverb, superlative best
- RP particle give up
- TO, to go ?to? the store.
- UH interjection, errrrrrrrm
- VB verb, base form take
- VBD verb, past tense, took
- VBG verb, gerund/present participle taking
- VBN verb, past participle is taken
- VBP verb, sing. present, known-3d take
- VBZ verb, 3rd person sing. present takes
- WDT wh-determiner which
- WP wh-pronoun who, what
- WP$ possessive wh-pronoun whose
- WRB wh-adverb where, when
Tagged Corpora
Representing Tagged Tokens
A tagged token is represented using a tuple consisting of the token and the tag. We can create one of these special tuples from the standard string representation of a tagged token, using the function str2tuple():
>>> tagged_token = nltk.tag.str2tuple(‘Learn/VB’)>>> tagged_token(‘Learn’, ‘VB’)>>> tagged_token[0]’Learn’>>> tagged_token[1]’VB’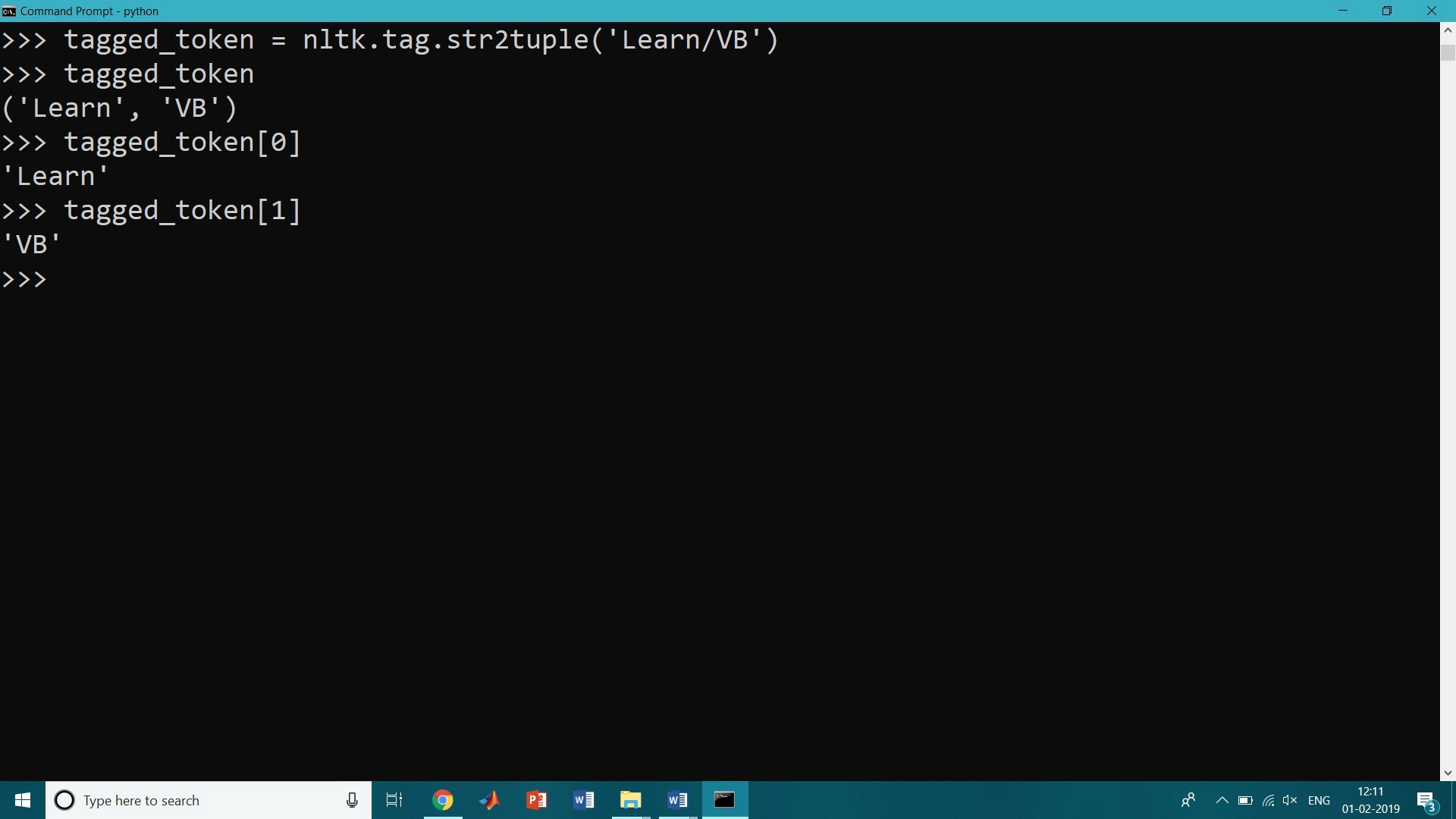
Reading Tagged Corpora
Several of the corpora included with NLTK have been tagged for their part-of-speech. Here?s an example of what you might see if you opened a file from the Brown Corpus with a text editor:
>>> nltk.corpus.brown.tagged_words()[(‘The’, ‘AT’), (‘Fulton’, ‘NP-TL’), …]>>> nltk.corpus.brown.tagged_words(tagset=’universal’)[(‘The’, ‘DET’), (‘Fulton’, ‘NOUN’), …]>>> [(‘The’, ‘DET’), (‘Fulton’, ‘NOUN’), …]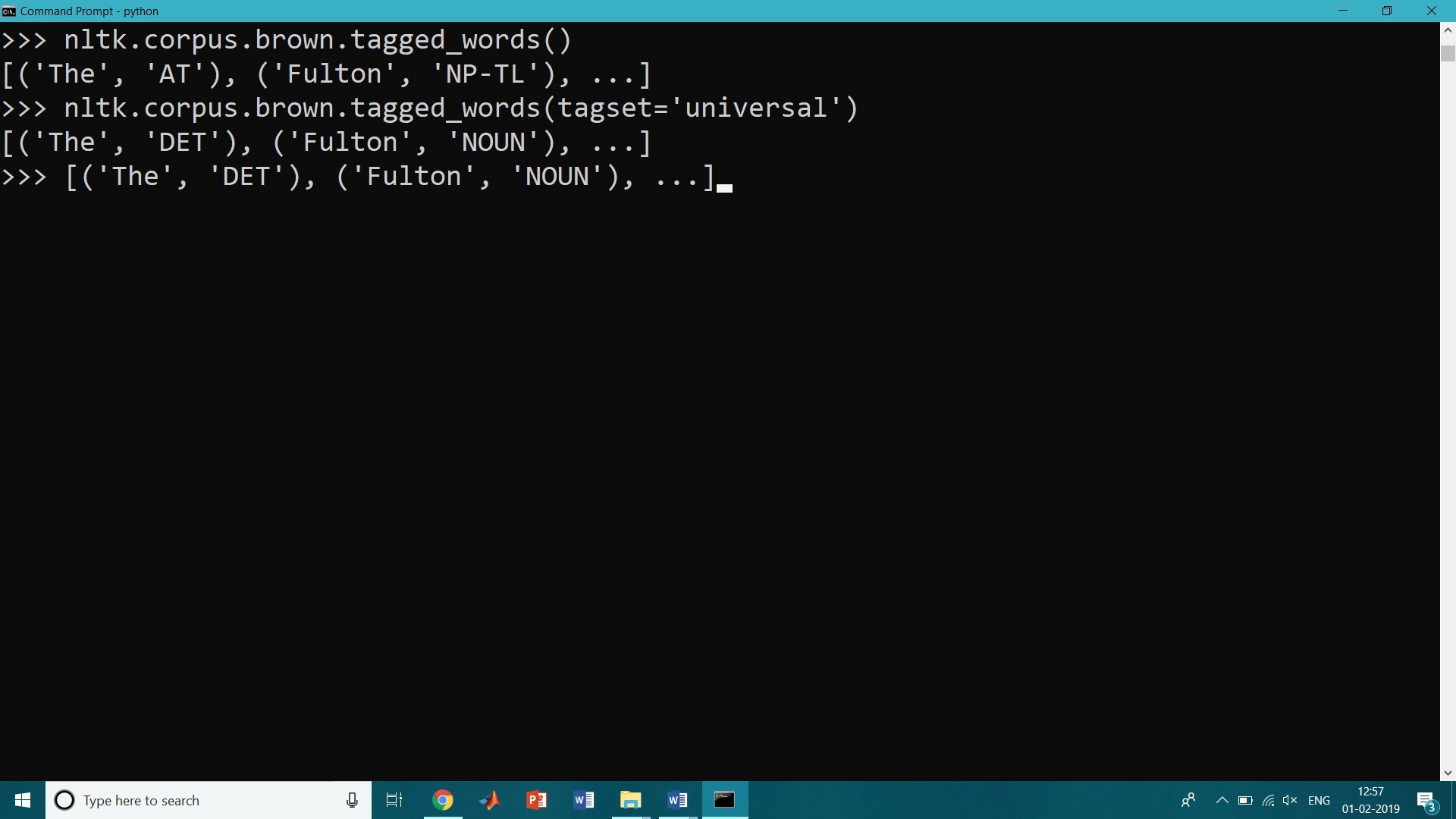
Part of Speech Tagset
Tagged corpora use many different conventions for tagging words.
TagMeaningEnglish ExamplesADJadjectivenew, good, high, special, big, localADPadpositionon, of, at, with, by, into, underADVadverbreally, already, still, early, nowCONJconjunctionand, or, but, if, while, althoughDETdeterminer, articles, a, some, most, every, no, whichNOUNnounyear, home, costs, time, AfricaNUMnumeraltwenty-four, fourth, 1991, 14:24PRTparticleat, on, out, over per, that, up, withPRONpronounhe, their, her, its, my, I, usVERBverbis, say, told, given, playing, would. punctuation marks. ,;!Xotherersatz, esprit, dunno, gr8, university
>>> from nltk.corpus import brown>>> brown_news_tagged = brown.tagged_words(categories=’adventure’, tagset=’universal’)>>> tag_fd = nltk.FreqDist(tag for (word, tag) in brown_news_tagged)>>> tag_fd.most_common()
Output
[(‘NOUN’, 13354), (‘VERB’, 12274), (‘.’, 10929), (‘DET’, 8155), (‘ADP’, 7069), (‘PRON’, 5205), (‘ADV’, 3879), (‘ADJ’, 3364), (‘PRT’, 2436), (‘CONJ’, 2173), (‘NUM’, 466), (‘X’, 38)]
Nouns
Nouns generally refer to people, places, things, or concepts, for example.: woman, Scotland, book, intelligence. The simplified noun tags are N for common nouns like a book, and NP for proper nouns like Scotland.
>>> word_tag_pairs = nltk.bigrams(brown_news_tagged)>>> noun_preceders = [a[1] for (a, b) in word_tag_pairs if b[1] == ‘NOUN’]>>> fdist = nltk.FreqDist(noun_preceders)>>> [tag for (tag, _) in fdist.most_common()][‘DET’, ‘ADJ’, ‘NOUN’, ‘ADP’, ‘.’, ‘VERB’, ‘CONJ’, ‘NUM’, ‘ADV’, ‘PRON’, ‘PRT’, ‘X’]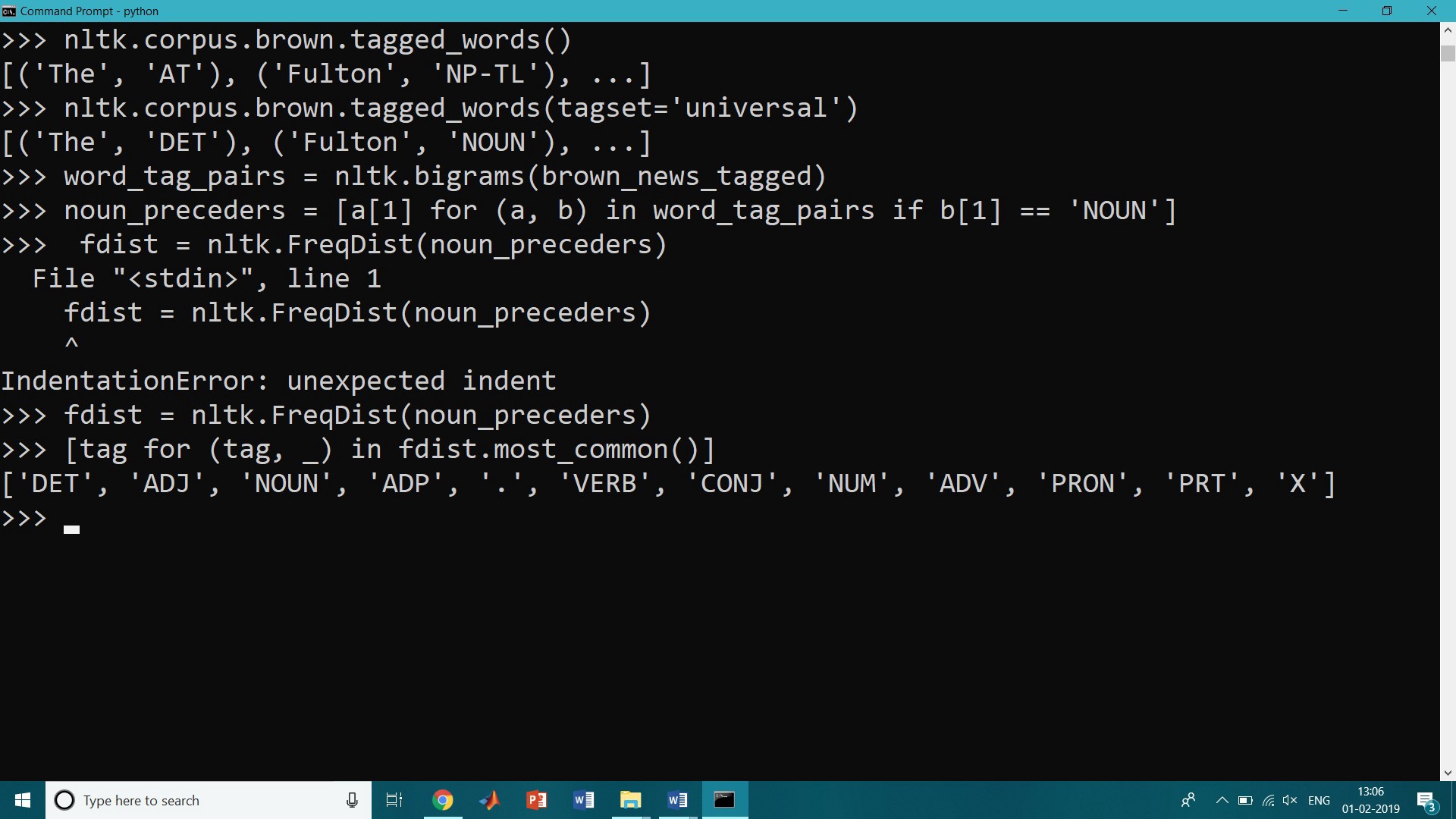
Verbs
Looking for verbs in the news text and sorting by frequency
>>> wsj = nltk.corpus.treebank.tagged_words(tagset=’universal’)>>> brown_news_tagged = brown.tagged_words(categories=’adventure’, tagset=’universal’)>>> wsj = nltk.corpus.treebank.tagged_words(tagset=’universal’)>>> [wt[0] for (wt, _) in word_tag_fd.most_common(200) if wt[1] == ‘VERB’][‘is’, ‘said’, ‘was’, ‘are’, ‘be’, ‘has’, ‘have’, ‘will’, ‘says’, ‘would’, ‘were’, ‘had’, ‘been’, ‘could’, “‘s”, ‘can’, ‘do’, ‘say’, ‘make’, ‘may’, ‘did’, ‘rose’, ‘made’, ‘does’, ‘expected’, ‘buy’, ‘take’, ‘get’]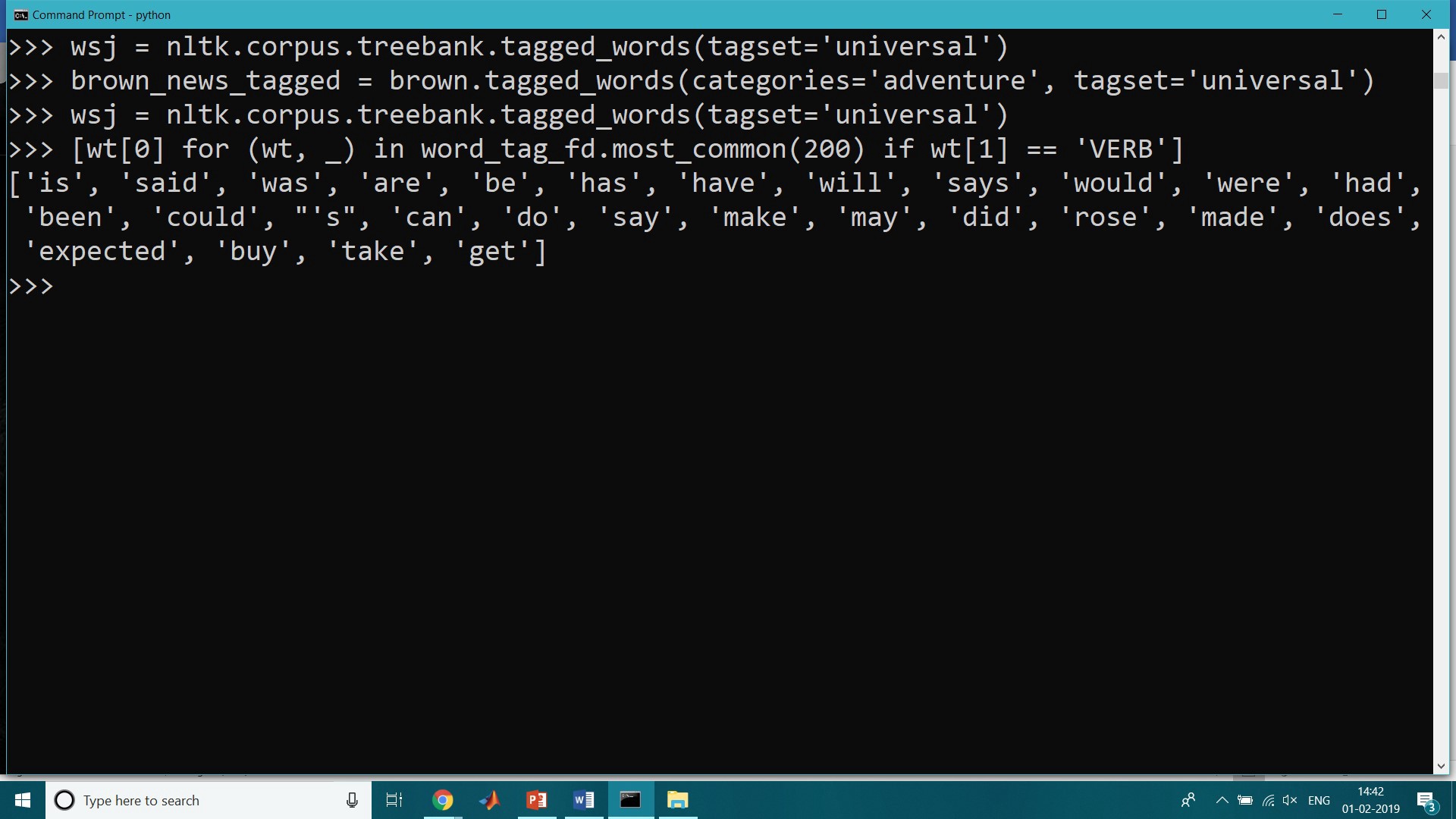
SOURCE: https://www.learntek.org/blog/categorizing-pos-tagging-nltk-python/

{kind=link}
{kind=link}