In the last few years, there has been a revolution in machine translation. New translation systems built using deep learning have replaced older systems built by linguists using decades of research in statistics. Popular translation products like Google Translate have switched their internals out and replaced their old code with new deep learning models.
 Real output from the Spanish-to-English translation model that we?ll train
Real output from the Spanish-to-English translation model that we?ll train
This is great for everyone. The deep learning approach is not only more accurate, but it doesn?t require you to have a graduate degree in linguistics to understand. In theory, it?s simple enough that anyone with enough training data and computer power should be able to build their own language translation system. Despite this, it?s still been difficult to build a translation system on your own because the amount of data and computing power required was prohibitive for the average bedroom hobbyist.
But like everything else in machine learning, machine translation is rapidly maturing. The tools are getting easier to use, GPUs are getting more powerful and the training data is more plentiful that ever. You can now build a language translation system using off-the-shelf hardware and software that is good enough to use in real projects. And best of all, you won?t have to pay Google any API fees to use it.
So let?s do it! Let?s build a Spanish-to-English translation system that can translate text ?from the wild? with a high level of accuracy!
Translating Text With Neural Networks
At the core of our translation system will be a neural network that takes in one sentence and outputs the translation of that sentence. I?ve written before about the history of machine translation systems and how we use neural networks to translate text, but here?s the short version:
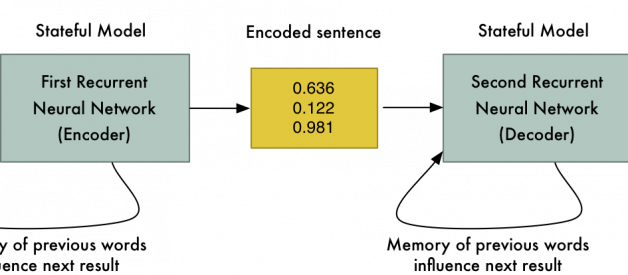
A neural translation system is really two neural networks hooked up to each other, end-to-end. The first neural network learns to encode sequences of words (i.e. sentences) into an array of numbers that represent their meaning. The second neural network learns to decode those numbers back into a sequence of words that mean the same thing. The trick is that the encoder takes in words in one language but the decoder outputs words in a different language. So in effect, the model learns a mapping from one human language to another via an intermediate numerical encoding:
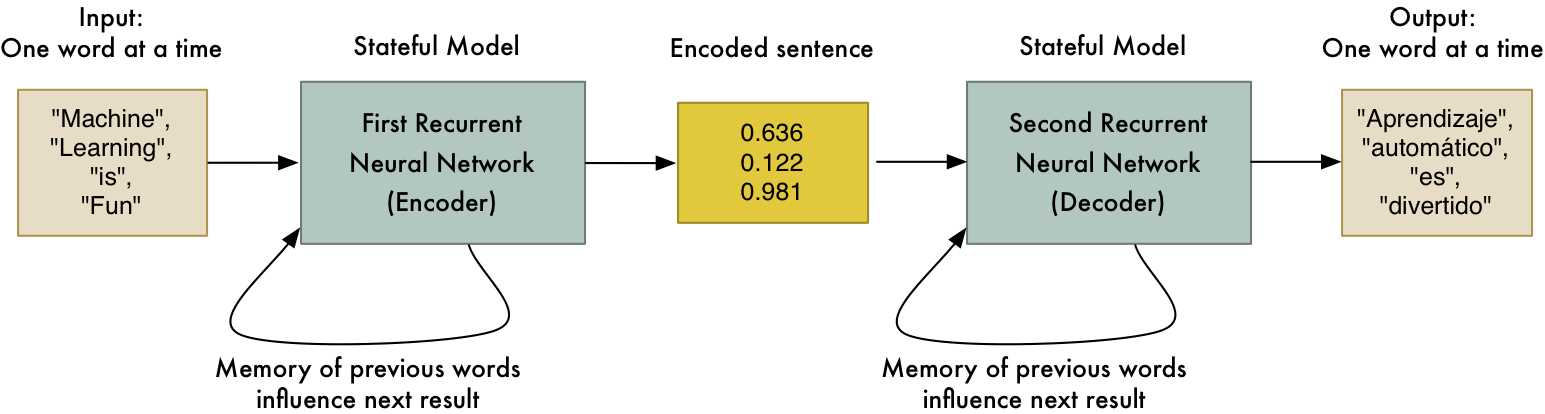
For encoding and decoding the meaning of a sentence, we?ll use a special type of neural network called a recurrent neural network. A standard neural network has no memory. If you give it the same inputs, it comes up with the same result every time. In contrast, recurrent neural networks are called recurrent because the last input influences the next prediction.
This is useful because each word in a sentence doesn?t stand on its own. The meaning of each word depends on its context in the sentence. By letting each word in the sentence influence the value of the next word, it allows us to capture some of that context.
So if you show the neural network the words ?My?, ?name?, ?is? and then ask it to encode the meaning of the word ?Adam?, it will use the previous words to know to represent the meaning of the word ?Adam? as a name. If you want more details on how this works, check out my earlier article.
If you are well versed in machine learning, you might be yawning at the mention of recurrent neural networks. If that?s the case, skip down to the Linux shell commands below to start training your model. I get it, machine learning is a rapidly developing field and what was absolutely revolutionary just few years ago is ancient news now.
In fact, there?s an even newer approach to language translation using a new type of model called a Transformer. Transformer models go further in trying the capture the contextual meaning of each word in a sentence by modeling the cross-relationships between every single word instead of just considering the order of the words. I?ve written about Transformer models too, but we?ll use recurrent neural networks for this project to keep the training times reasonable. Don?t worry, the results will still be excellent!
The Full Translation Pipeline
Great, so we?ll use two recurrent neural networks to translate text. We?ll train the first one to encode sentences in Spanish and train the second one to decode them into English. And if you believe my reddit commenters, every high school student with a copy of Python already knows how to create a recurrent neural network, so time to get started, right?
Not so fast! We need a strategy for handling messy, real-world data. Humans are very good at pulling information out of messy data without any help. For example, you can probably read sentence this without any problems:
cOMPuTERs are BAd at UNderStandING Messy DAtA..
A neural network trained on perfectly-formatted text would have no idea what that said. Neural networks don?t have the ability to extrapolate beyond what they?ve seen in their training data. If the neural net has never seen the world ?cOMPuTERs? before, it won?t automatically know it means the same thing as ?computers?.
The solution is to normalize the text ? we want to remove as much formatting variation as possible. We?ll make sure that words always are capitalized the same way in the same context, we?ll fix any weird formatting around punctuation, we?ll clean up any weird curly quote marks that MS Word randomly added, and so. The whole idea is to make sure that the same sentence would always be fed in exactly the same way, no matter how the user typed it.
Here?s an example of text normalization:
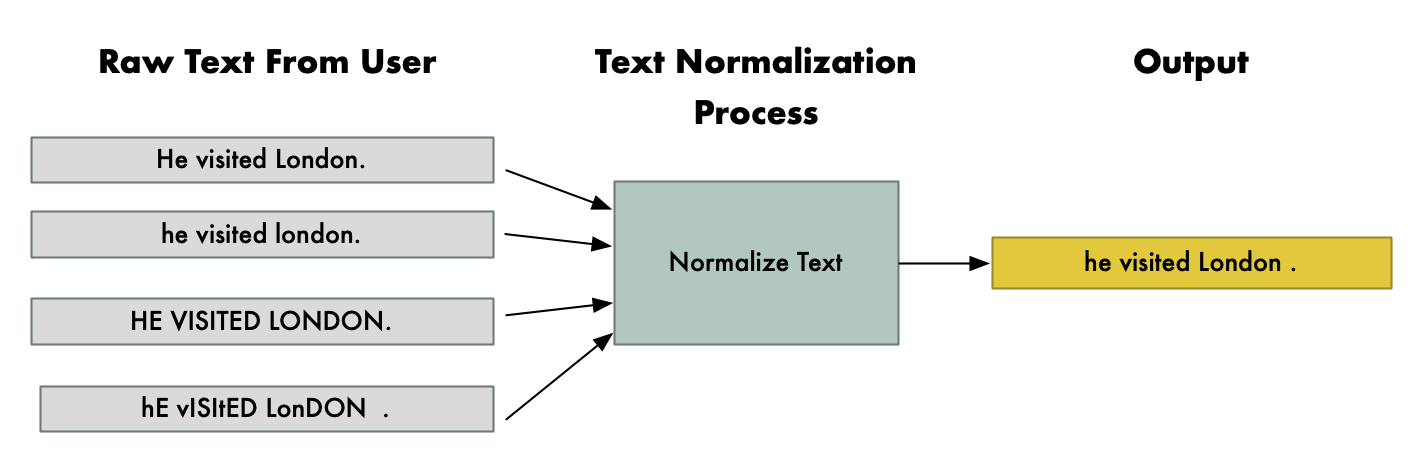
Notice how the sentence, ?He visited London? is normalized the same way no matter how badly the user?s Shift key works. And notice that London is always capitalized while the other words aren?t because it is normally used as a proper noun. Making sure the text is cleanly formatted like this will make the neural network?s job a lot easier.
Here?s what our full translation pipeline will look like, stating with the text we want to translate and ending with the translated version:

First, we need to split the text into sentences. Our neural network will only be able to translate one sentence at a time and it will produce poor results if we try to feed in an entire paragraph at once.
Splitting text into sentences might seem easy, but it is actually a tricky task because of all the different ways someone could nest punctuation and formatting. For this project, we?ll use a simple sentence splitter written in Python to reduce the amount of 3rd-party libraries you need to install. But NLP libraries (like spaCy) include sophisticated sentence splitting models that you can use if this doesn?t satisfy your needs.
Next, we?ll perform text normalization. This is the hardest part to get right and if you skimp on this step, the final results will be disappointing. And once we have normalized text, then we?ll feed it to the translation model.
Keep in mind that you also need to reverse the text normalization and sentence splitting steps to generate the final translation. So we?ll have a de-normalization step and then a step to recombine the text back into sentences.
Software and Hardware Requirements
Python 3
We?ll use Python 3 to write the glue code to normalize text, perform the translation, and output the results.
Marian NMT (Deep Learning Framework for Machine Translation)
You might have assumed that we?d use a general-purpose machine learning framework like TensorFlow or PyTorch to implement our translation model. Instead, we are going to use Marian NMT, a C++-based machine learning framework specially designed for machine translation, mainly developed by the Microsoft Translator team. It has several neural translation model architectures already built-in.
TensorFlow and PyTorch are great for experimentation and trying out new neural network designs. But once you figure out the model architecture and you are trying to scale up your design to handle real-world users, you don?t need a general purpose tool anymore.
Marian NMT is a specialized tool designed to make it easy and fast to build production-level translation systems. There?s no need to reinvent the wheel here. This is an example of how software is getting more mature as machine learning moves from research labs into daily use.
Desktop Computer with a GPU
To run Marian, we?ll need a computer running Linux. Any computer that is reasonably powerful should work. I?m using a desktop computer with Ubuntu Linux 18.04, an Intel i7 CPU and 32GB of RAM. For storing the training data, I?m using normal SSD hard drives.
The important part is that the computer has a good Nvidia GPU with sufficient video memory. The GPU is doing the bulk of the computing work, so that?s where you should invest your money. I?m using an Nvidia TITAN RTX with 24GB of memory. At a minimum, you?ll want a GPU with at least 8GB of video memory. Other good consumer-level GPU choices include the GTX 1080 Ti or GTX 2080 Ti. Server-class GPUs like the Nvidia TESLA or Quadro lines will also work.
You can use Marian with a single GPU or with multiple GPUs in parallel to speed things up, but each GPU needs to have enough memory to hold the model and training data on its own. In other words, two GPUs with 4GB of memory will not work in place of one GPU with 8GB of memory.
Preparing Your Computer
Install Ubuntu Linux 18.04 LTS
Despite being supported by Microsoft, Marian doesn?t yet run on Windows. Mac OS isn?t supported either. So just bite the bullet and either install Linux on your computer or consider renting a Linux machine in the cloud from your favorite Cloud provider.
I recommend installing Ubuntu Linux 18.04 LTS for this project. Even though Ubuntu Linux 20.04 LTS was recently released, it takes time for GPU drivers and deep learning libraries to be updated for new Ubuntu releases. Don?t try to use the latest version of Ubuntu unless you are willing to deal with extra headaches and solve your own installation problems.
Install Nvidia?s CUDA and cuDNN Libraries
Nvidia?s CUDA and cuDNN libraries are what allow Marian to take advantage of your GPU to accelerate the training process. So before we go any further, you?ll need to install CUDA and cuDNN if you haven?t already.
On Ubuntu Linux 18.04, I recommend installing CUDA /cuDNN version 10.1. Those versions will work great with Marian.
- Install CUDA 10.1
- Install the matching cuDNN version
If you install a different version, you?ll have to adapt the commands below to match. Nvidia is notorious for making slight changes in newer versions of CUDA that cause incompatibilities will older software, so again be prepared to do you own debugging if you veer off the standard path.
Install Marian and Training Scripts
Before you can compile Marian, you?ll need to install a newer version of CMake than is included with Ubuntu 18.04 by default. You?ll also need to install a few other prerequisites.
But don?t worry, it?s no big deal. Just run these terminal commands:
# Install newer CMake via 3rd-party repowget -O – https://apt.kitware.com/keys/kitware-archive-latest.asc 2>/dev/null | sudo apt-key add -sudo apt-add-repository ‘deb https://apt.kitware.com/ubuntu/ bionic main’sudo apt-get install cmake git build-essential libboost-all-dev
Note that these commands pull packages from a 3rd-party package repository. So check what the commands are doing to make sure you are OK with that.
With those pre-requisites installed, run these commands to download and compile Marian (including the examples and helper tools, which are spread across separate git repos):
# Download and compile Mariancd ~git clone https://github.com/marian-nmt/mariancd marianmkdir buildcd buildcmake -DCOMPILE_SERVER=on -DCUDA_TOOLKIT_ROOT_DIR=/usr/local/cuda-10.1/ ..make -j4# Grab and compile the Marian model examples and helper toolscd ~/marian/git clone https://github.com/marian-nmt/marian-examples.gitcd marian-examples/cd tools/make
Finally, I?ve shared the scripts that we?ll use to train our Spanish-to-English model with Marian. These are based on the Romanian translation example included with Marian, but modified for Spanish-to-English and scaled up to a larger data set. Let?s grab those:
# Download the Spanish-to-English scripts for this articlecd ~/marian/marian-examplesgit clone https://github.com/ageitgey/spanish-to-english-translation# Install the Python modules we’ll use latercd spanish-to-english-translationsudo python3 -m pip install -r requirements.txt
You are free to tweak these scripts to work for any language pair that you want to translate. Latin-based languages like French or Italian would require very few changes while less similar languages like Mandarin would require a lot more work.
How to Find Training Data
To train a translation model, we need millions of pairs of sentences that are exactly the same except that they have been translated into two languages. This is called a parallel corpora:
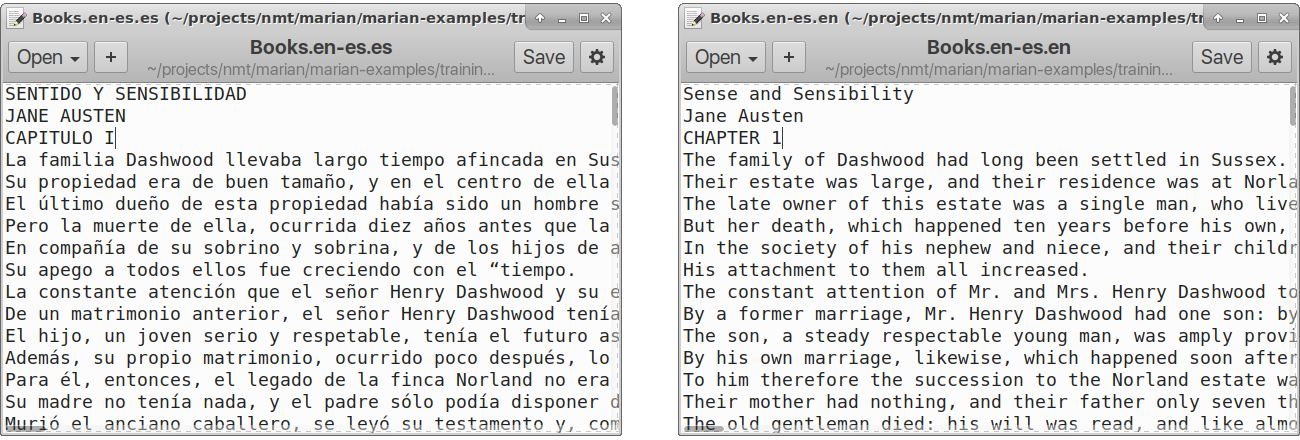 Each line is one sentence. The sentences in the two files match up.
Each line is one sentence. The sentences in the two files match up.
The more sentence pairs we have, the better our model will learn how to translate different kinds of text. To create an industrial-strength model, we?ll need tens of millions of training sentences or more. And most importantly, these sentences need to cover the whole range of human expression, from formal documents to slang and jokes.
The biggest difference between a bad translation system and something as powerful as Google Translate is the amount and variety of training data! Luckily in 2020, there are lots of places where we can find parallel data that was created by accident and can be turned into training sentence pairs with some clever tricks.
For formal and legal text, we have the gift of the European Union. They translate their legal documents into all the languages of their member states, including English and Spanish. Along the same lines, we can find cross-translated legal text from other international agencies, like the United Nations and the European Central Bank.
For historical writing, we can source sentence pairs from classic books that have been translated into different languages. We can take books that are out of copyright and pair up different translations of those works to create pairs of sentences that we know say the same thing.
And for informal conversation, we have the gift of DVDs. Since the DVD format was launched in the late 1990s, almost all movies and TV shows have included machine-readable subtitles in several languages. We can pair up different translations of the same movies and TV shows to create parallel data. This same idea also works for newer content that has subtitles, like Blu-rays and YouTube videos.
Now we know where to find the data, but it is still a lot of work to clean and prepare it all. Luckily the amazing folks at OPUS (Open Parallel Corpus) have already done the work of collecting sentence pairs in numerous languages. You can browse and download all their parallel sentence data on their website. This will speed up our project enormously, so make sure to check out the citations of their work at the end of this article.
The training script that we?ll run later will automatically download these data sources from OPUS, giving us nearly 85 million translated sentence pairs with zero work. That?s awesome!
OPUS provides files by language pair. So if instead of Spanish-to-English you wanted to create, say, a Finnish-to-Italian translation model, you could do that by downloading the files for that language pair instead. Just keep in mind it will be harder to find sentence pairs for less widely-spoken languages. Also,keep in mind that some languages will need unique approaches to text normalization that aren?t covered in this example.
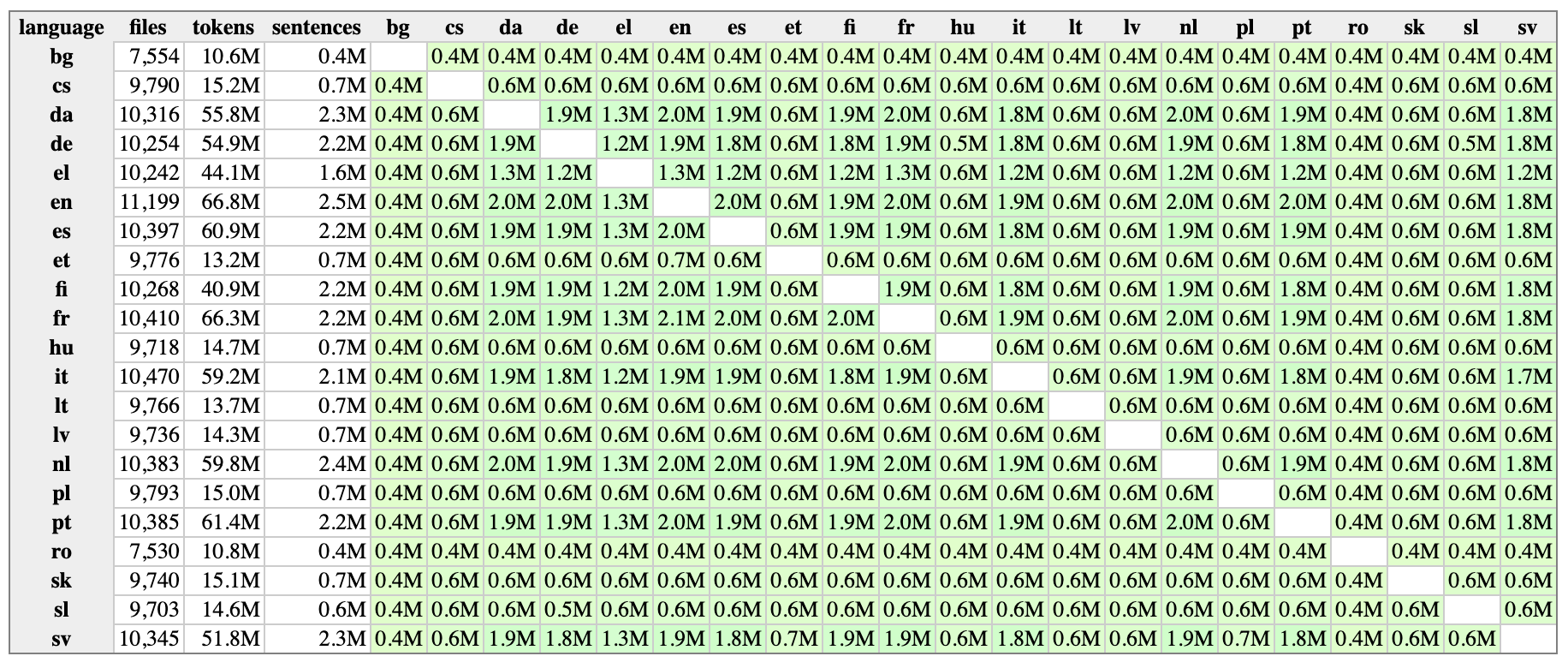 A table of available language pairs of European Parliament data from OPUS. Notice that less widely-spoken languages have smaller files with less data than more widely spoken languages like English.
A table of available language pairs of European Parliament data from OPUS. Notice that less widely-spoken languages have smaller files with less data than more widely spoken languages like English.
Also keep in mind that this data was sourced from a variety of places and quality varies. There is certain to be some bad or duplicated data in these downloads. When you are working with huge data sets, data quality is never guaranteed and you often need to get your hands dirty to find and fix any glaring issues.
Combining and Prepping Training Data
The script I included to train the model will automatically download and prep the data for you, but it?s worth talking about the steps involved in case you want to build a translation model for a different language pair.
Each data source we download from OPUS will include two text files. One text file has a list of English sentences and the other has a matching list of Spanish sentences in the same order. So we?ll end up with numerous text files, like this:
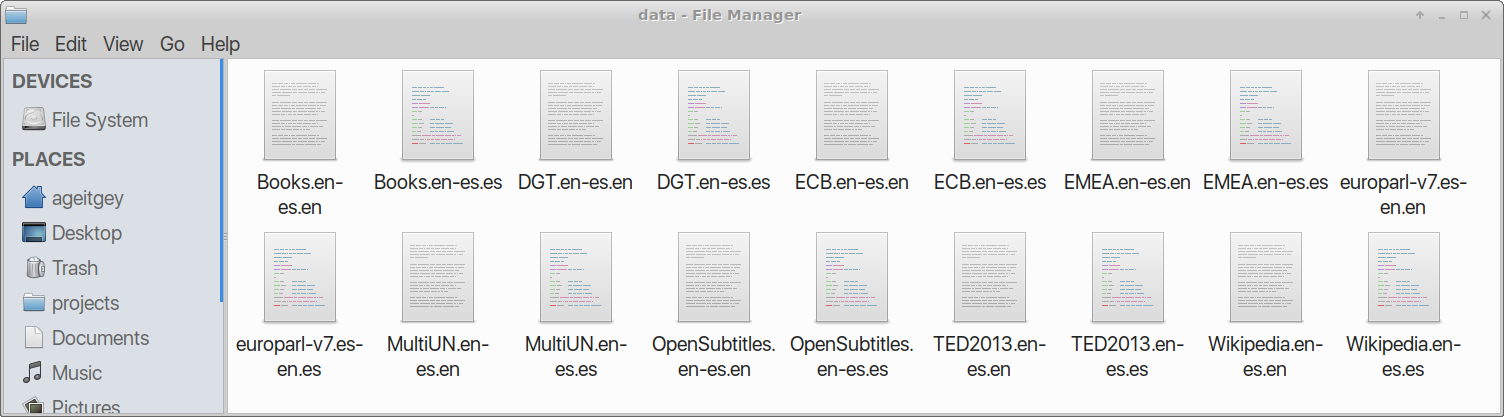
We need to go through several steps to prepare the training data:
- Combine: Combine all the English text files into a single, massive text file. Likewise, combine all the Spanish text files, making sure to keep all the sentences in order so that the English and Spanish files still match up.
- Shuffle: Randomize the order of the sentences in each file, while still keeping the sentences in the English and Spanish files in the same relative order. Mixing up training data from different sources will help the model learn to generalize across different types of text instead of first learning to translate formal data, then learning to translate informal data, and so on.
- Split: Split the master data files for each language into training, development and testing segments. We?ll train the model on the bulk of the training data but withhold some sentences to use to test the model and make sure that it is working. This ensures that we are testing the model using sentences that it never saw during training so we can be sure it didn?t just memorize the correct answers.
Handling Rare and Novel Words with Subword Segmentation
It is never possible to get training data that covers every possible word because people make up new words all the time. To help our translation system handle never-before-seen words, we are going to use an approach called subword segmentation.
Subword segmentation is where we divide words into smaller fragments and teach the model translate between each fragment of each word. The hope is that if the model sees a word it has never seen before, it can at least try to guess the meaning of the word by translating the subwords that make it up.
Imagine that our training data contained the words low, lowest, newer, and wider. We could split the words into roots and suffixes:
- Roots: low, new, wid
- Suffixes: est, er
Now imagine that we are asked to translate the word widest. Even though that word was never in the training data, the model will know how to translate wid and est, so by putting those two subword translations together, it will be able to make a pretty good guess as to what widest means. This won?t always be perfect, but it will work well enough in a lot of cases and it will make the translation model more accurate overall.
The specific implementation of subword segmentation will we use is called BPE, or Byte Pair Encoding. You can read about how it works in the original research paper.
To take advantage of BPE, we?ll need to train a new BPE model to fit our training data set and then we?ll include an extra step in our text normalization process where we run the text through that BPE model. Likewise, we?ll need to add step during the de-normalization process to re-join any words in the final translation that were split into separate words by the BPE model.
Training the Full Translation Pipeline
The entire process of downloading the training data, preparing it, creating the BPE model and training the actual translation model with Marian is all in one script. To kick everything off, run this command:
cd ~/marian/marian-examples/spanish-to-english-translation/./run-me.sh
You can take a look at the run-me.sh script to see what happens at each step. It?s pretty straightforward ? it downloads the training data, combines it, normalizes it and then kicks off the Marian training process.
Feel free to replace this script with your own implementation if you are going to build a production-grade translation system. This script is just a guide to the steps that you need to perform.
After the data is prepared and the model starts to train, you?ll see output like this:
[2020-05-01 10:09:23] Ep. 1 : Up. 1000 : Sen. 154,871 : Cost 70.37619781 : Time 370.45s : 5024.86 words/s
Here?s a guide to the abbreviations:
- Ep. = Epoch (Number of passes over the entire set of training data)
- Up. = Updates
- Sen. = Sentences
This message is saying that we are currently on Epoch 1 (the first pass over the training data) and so far, the model has been updated 1000 times with 154,871 sentence pairs processed.
The Cost value of 70.3 tells you how far the model training process has gotten to finding an optimal solution. A cost of 0.0 would mean the model is perfect and always turns any Spanish sentence into the perfect match English translation in the training data. This will never happen because the model will never be perfect and there isn?t only one correct translation for every sentence. But the lower the Cost, the closer the training process is to being done.
Over time, the Cost value should come down and eventually training will end automatically. On my system, the training process took about a day but it might take a bit longer depending on your GPU and the amount of training data that you have collected.
The training process will occasionally pause to validate the model on a small set of sentences that have been kept separate from the training set. This is to make sure the model is working well on new data and not just memorizing the training data.
When training completes (after 1?2 days), all the model files will be saved in the /models/ subfolder. These files are what you need to use the translation model in another program to translate new text.
I Ain?t Got Time For That. Can I Download Your Pre-Trained Model Instead?
If you want to move on to the next step without waiting 1?2 days for training to finish, you can download my pre-trained Spanish-to-English model:
cd ~/marian/marian-examples/spanish-to-english-translation/wget https://github.com/ageitgey/spanish-to-english-translation/releases/download/0.1/model-spanish-to-english.tar.gztar -zxvf model-spanish-to-english.tar.gz
Using the Model to Translate New Text
Now for the fun part ? let?s try out our new translation system!
To translate text, we need to pass the text through the same text normalization steps as the training data, have the neural network translate the text, and then reverse the text normalization steps on the output.
Because the Marian model itself is fairly large, one of the slowest steps in translation is loading the model into memory. To avoid this delay, Marian can run in ?server mode? where it stays in memory and lets you send translation individual requests to it. We?ll use server mode.
To start the Marian server, run these commands in a Terminal window:
cd ~/marian/marian-examples/spanish-to-english-translation/../../build/marian-server –port 8080 -c model/model.npz.best-translation.npz.decoder.yml -d 0 -b 12 -n1 –mini-batch 64 –maxi-batch 10 –maxi-batch-sort src
This is telling the server to listen for connections on port 8080 and to use the model file described in the file model.npz.best-translation.npz.decoder.yml.
Remember that the Marian server only handles the translation step in our pipeline ? it doesn?t do any text normalization. Whatever you do, don?t make the mistake of sending raw, unnormalized text directly to the Marian server. You?ll get terrible results if you do that! The new text we translate needs to exactly match the format of the training data. That means we need to apply the same text normalization steps on any new text we translate.
Let?s run the a Python script I made that translates some example text. With the Marian server already running, open up a new Terminal window and run this:
python3 translate_sentences_example.py
For now, I?ve made the Python code call out to the same Perl scripts included with Marian to normalize the training data. This isn?t super clean, but it works. If you are feeling adventurous and want to deploy this as part of a production system, feel free to re-write those Perl scripts in pure Python to avoid those shell calls and speed up the process.
The example text in the Python script is the first paragraph of the Spanish edition of the first Harry Potter novel. You should get output that looks like this:
Input:El nio que vivi.El seor y la seora Dursley, que vivan en el nmero 4 de Privet Drive, estaban orgullosos de decir que eran muy normales, afortunadamente.Output:The boy who lived.Mr. and Mrs. Dursley, who lived at number 4 on Privet Drive, were proud to say they were very normal, fortunately.They were the last people who would expect to find themselves related to something strange or mysterious, because they weren’t for such nonsense.
Note: If you get a ?Connection Refused? error, make sure you started the Marian server up and that it?s still running in another Terminal window.
Here?s how our translation of Harry Potter compares to the original book in English:

Pretty good! While our translation doesn?t exactly match the English version of the book, it captures the same meaning. And if you read Spanish, you?ll see that our translation more closely matches the Spanish text anyway.
You can replace the example text in the script with anything you want to translate! Now that you have a translation model that you can call from Python, the world is your oyster. Feel free to include it in any other program that you create. Here are some (bad) ideas:
- Use the feedparser library to grab the RSS feed from your favorite Spanish newspaper and automatically translate all the stories.
- Write a program to translate all the posts on https://www.meneame.net/ so you can keep up to date on all the hottest Spanish memes.
- Write a program to do your Spanish homework.
Have fun!
Citations
Thanks to the many people who built the tools and data resources that make it possible to quickly build a translation system in your bedroom!
- Marian: Fast Neural Machine Translation in C++: Junczys-Dowmunt, Marcin and Grundkiewicz, Roman and Dwojak, Tomasz and Hoang, Hieu and Heafield, Kenneth and Neckermann, Tom and Seide, Frank and Germann, Ulrich and Fikri Aji, Alham and Bogoychev, Nikolay and Martins, Andre F. T. and Birch, Alexandra, Proceedings of ACL 2018, System Demonstrations, http://www.aclweb.org/anthology/P18-4020
- OPUS (Open Parallel Corpus): Jrg Tiedemann, 2012,Parallel Data, Tools and Interfaces in OPUS. [pdf] In Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC?2012)
- United Nations Corpus: Ziemski, M., Junczys-Dowmunt, M., and Pouliquen, B., (2016), The United Nations Parallel Corpus, Language Resources and Evaluation (LREC?16), Portoro?, Slovenia, May 2016.
- EMEA (European Medicines Agency) Corpus: http://www.emea.europa.eu/ / J. Tiedemann, 2012, Parallel Data, Tools and Interfaces in OPUS. In Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC 2012)
- ECB (European Central Bank) Corpus: Alberto Simoes / J. Tiedemann, 2012, Parallel Data, Tools and Interfaces in OPUS. In Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC 2012)
- OpenSubtitles Corpus: P. Lison and J. Tiedemann, 2016, OpenSubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles. In Proceedings of the 10th International Conference on Language Resources and Evaluation (LREC 2016)
- DGT (European Commission?s Directorate-General) Corpus: JRC / J. Tiedemann, 2012, Parallel Data, Tools and Interfaces in OPUS. In Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC 2012)
- MultiUN Corpus: MultiUN: A Multilingual corpus from United Nation Documents, Andreas Eisele and Yu Chen, LREC 2010 /J. Tiedemann, 2012, Parallel Data, Tools and Interfaces in OPUS. In Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC 2012)
- Copyright-Free Books Corpus: http://farkastranslations.com/bilingual_books.php /J. Tiedemann, 2012, Parallel Data, Tools and Interfaces in OPUS. In Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC 2012)
- TED2013 Corpus: CASMACAT / J. Tiedemann, 2012, Parallel Data, Tools and Interfaces in OPUS. In Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC 2012)
- Wikipedia Parallel Corpus: Building Subject-aligned Comparable Corpora and Mining it for Truly Parallel Sentence Pairs., Procedia Technology, 18, Elsevier, p.126?132, 2014 / J. Tiedemann, 2012, Parallel Data, Tools and Interfaces in OPUS. In Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC 2012)
If you liked this article, consider signing up for my Machine Learning is Fun! Newsletter:
I?ve written also written a book on ML! It not only expands on my articles, but it has tons of brand new content and lots of hands-on coding projects. Check it out now.
You can also follow me on Twitter at @ageitgey, email me directly or find me on linkedin. I?d love to hear from you if I can help you or your team with machine learning.

{kind=link}
{kind=link}