What is a neural network? Just like our brains are connected with thousands of neurons to process any information and respond to it automatically, an artificial neural network is somewhat like that.
? To put it in the coding world, a neural network is a series of algorithms that endeavors to recognize underlying relationships in a set of data through a process that mimics the way the human brain operates. Neural networks can adapt to changing input; so the network generates the best possible result without needing to redesign the output criteria.?
Let?s take a look at a question ? ?working love learning we on deep?, did this make any sense to you? Not really ? read this one ? ?We love working on deep learning?. Made perfect sense! A little jumble in the words made the sentence incoherent. Well, can we expect a neural network to make sense out of it? Not really! If the human brain was confused about what it meant I am sure a neural network is going to have a tough time deciphering such text. If we are trying to use such data for any reasonable output, we need a network which has access to some prior knowledge about the data to completely understand it. Recurrent neural networks thus come into play.
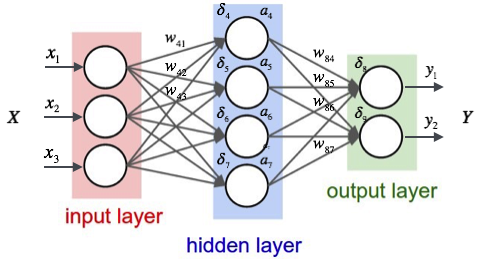
RNN- In traditional neural networks, all the inputs, and outputs are independent of each other, but in cases like when it is required to predict the next word of a sentence, the previous words are required and hence there is a need to remember the previous words(as the next word will depend on your previous input). Example you watch a movie and in between you stop to predict the ending, it will depend on how much you have seen it already and what context has come up yet. Similarly RNN remembers everything. It solves this problem of traditional neural network with a hidden layer.
 Output of first is the input for second
Output of first is the input for second
An RNN remembers each and every information through time. It is useful in time series prediction only because of the feature to remember previous inputs as well. This is called Long Short Term Memory.
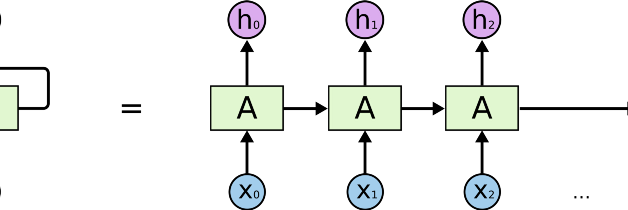
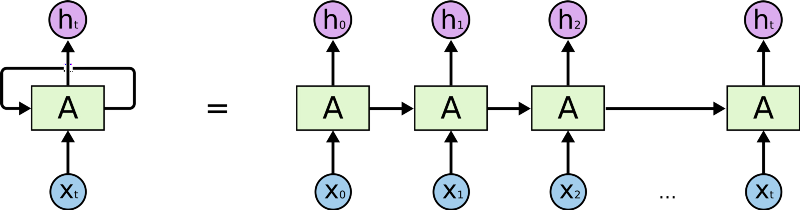
Working of RNN:RNN creates the networks with loops in them, which allows it to persist the information.This loop structure allows the neural network to take the sequence of input. If you see the unrolled version, you will understand it better.
- RNN converts the independent activations into dependent activations by providing the same weights and biases to all the layers, thus reducing the complexity of increasing parameters and memorizing each previous outputs by giving each output as input to the next hidden layer.
- Hence these three layers can be joined together such that the weights and bias of all the hidden layers is the same, into a single recurrent layer.
Formula for calculating current state:
![]() ht -> current stateht-1 -> previous statext -> input state
ht -> current stateht-1 -> previous statext -> input state
- Formula for applying Activation function(tanh):
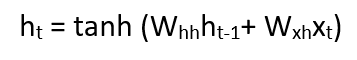 whh -> weight at recurrent neuronwxh -> weight at input neuron
whh -> weight at recurrent neuronwxh -> weight at input neuron
- Formula for calculating output:
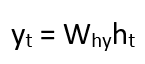 Yt -> outputWhy -> weight at output layer
Yt -> outputWhy -> weight at output layer
Bi-LSTM:(Bi-directional long short term memory):Bidirectional recurrent neural networks(RNN) are really just putting two independent RNNs together. This structure allows the networks to have both backward and forward information about the sequence at every time step
Using bidirectional will run your inputs in two ways, one from past to future and one from future to past and what differs this approach from unidirectional is that in the LSTM that runs backward you preserve information from the future and using the two hidden states combined you are able in any point in time to preserve information from both past and future.
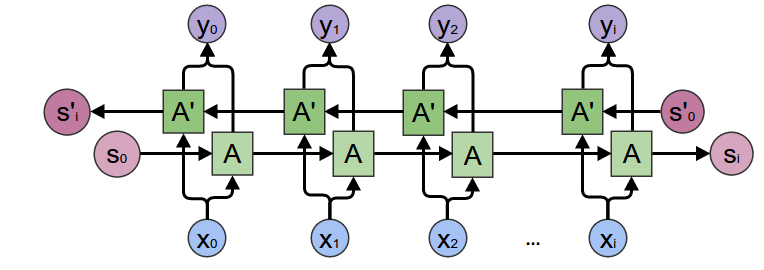
What they are suited for is a very complicated question but BiLSTMs show very good results as they can understand the context better, I will try to explain through an example.
Let’s say we try to predict the next word in a sentence, on a high level what a unidirectional LSTM will see is
?The boys went to ?.?
And will try to predict the next word only by this context, with bidirectional LSTM you will be able to see information further down the road for example
Forward LSTM:
?The boys went to ??
Backward LSTM:
?? and then they got out of the pool?
You can see that using the information from the future it could be easier for the network to understand what the next word is.
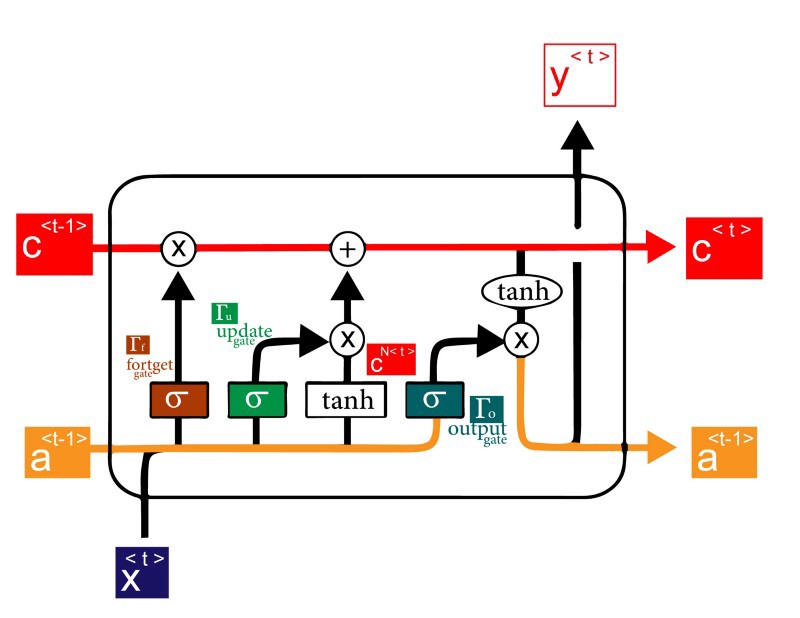
Here in LSTM ,
- we use activation values , not just C (candidate values ) ,
- we also have 2 outputs from the cell , a new activation , and a new candidate value
so to calculate the new candidate

here in LSTM we control the memory cell through 3 different gates
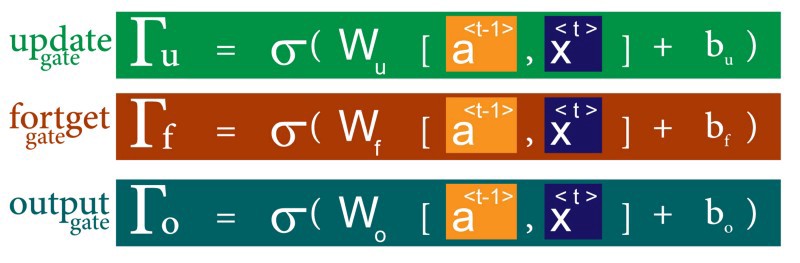
as we said before we have 2 outputs from LSTM , the new candidate and a new activation , in them we would use the previous gates

To combine all of these together
In Bi-LSTM:
As in NLP , sometimes to understand a word we need not just to the previous word , but also to the coming word , like in this example

Here for the word ?Teddy? , we can?t just say whether the next word is gonna be ?Bears? or ?Roosevelt?, it will depend on the context of the sentence.Bi-lstm is general architecture that can use any RNN model
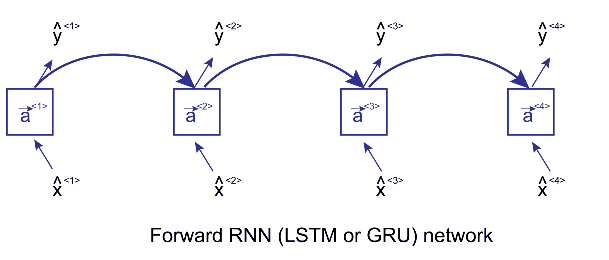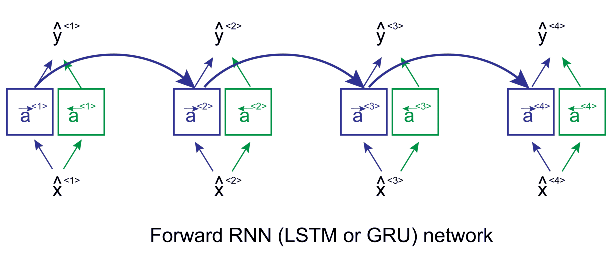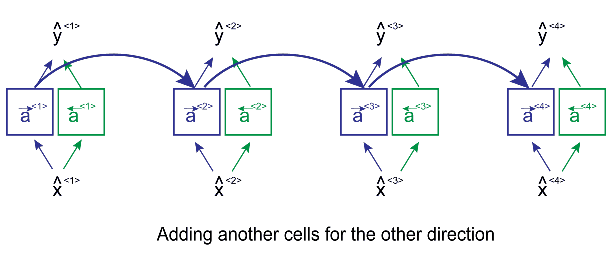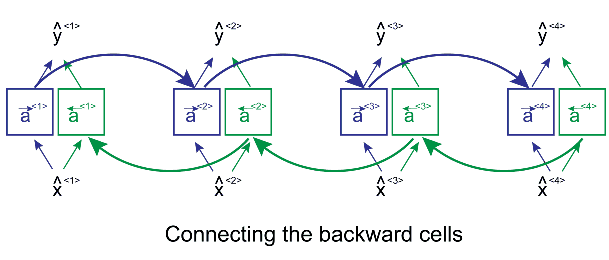
Here we apply forward propagation 2 times , one for the forward cells and one for the backward cells
Both activations(forward , backward) would be considered to calculate the output y^ at time t



{kind=link}
{kind=link}