Quicksort is one of the efficient and most commonly used algorithms. Most of the languages used quicksort in their inbuild ?sort? method implementations. The name comes from the fact that it sorts data faster than any commonly available sorting algorithm and like Merge sort, it also follows the divide and conquer principle.
Quicksort, in particular, is an interesting one nevertheless it takes enough time to get your head around it. Quicksort breaks down the problem of sorting the complete array into smaller problems by breaking down the array into smaller subarray. This technique of splitting the bigger problem into smaller problems is called divide and conquer approach.
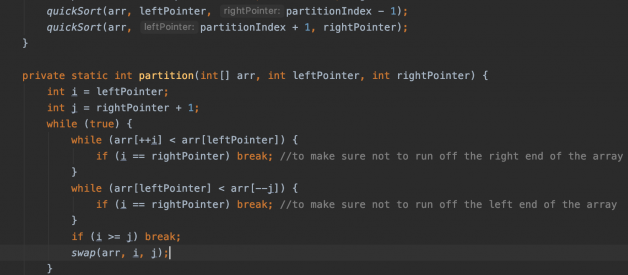
How Quicksort works:
Quicksort in simple is a sorting algorithm. It sorts the entire list of items by choosing a pivot element and then arranging the rest of the elements around the pivot such that all the elements less than the pivot is in the left side of the pivot and the elements greater than or equal to the pivot moved to the right of the pivot.
The sorting is continued on to the left and right side of the sub-arrays separately and that is how the bigger problem of sorting the entire list is broken down into smaller problems itself and solving them recursively.
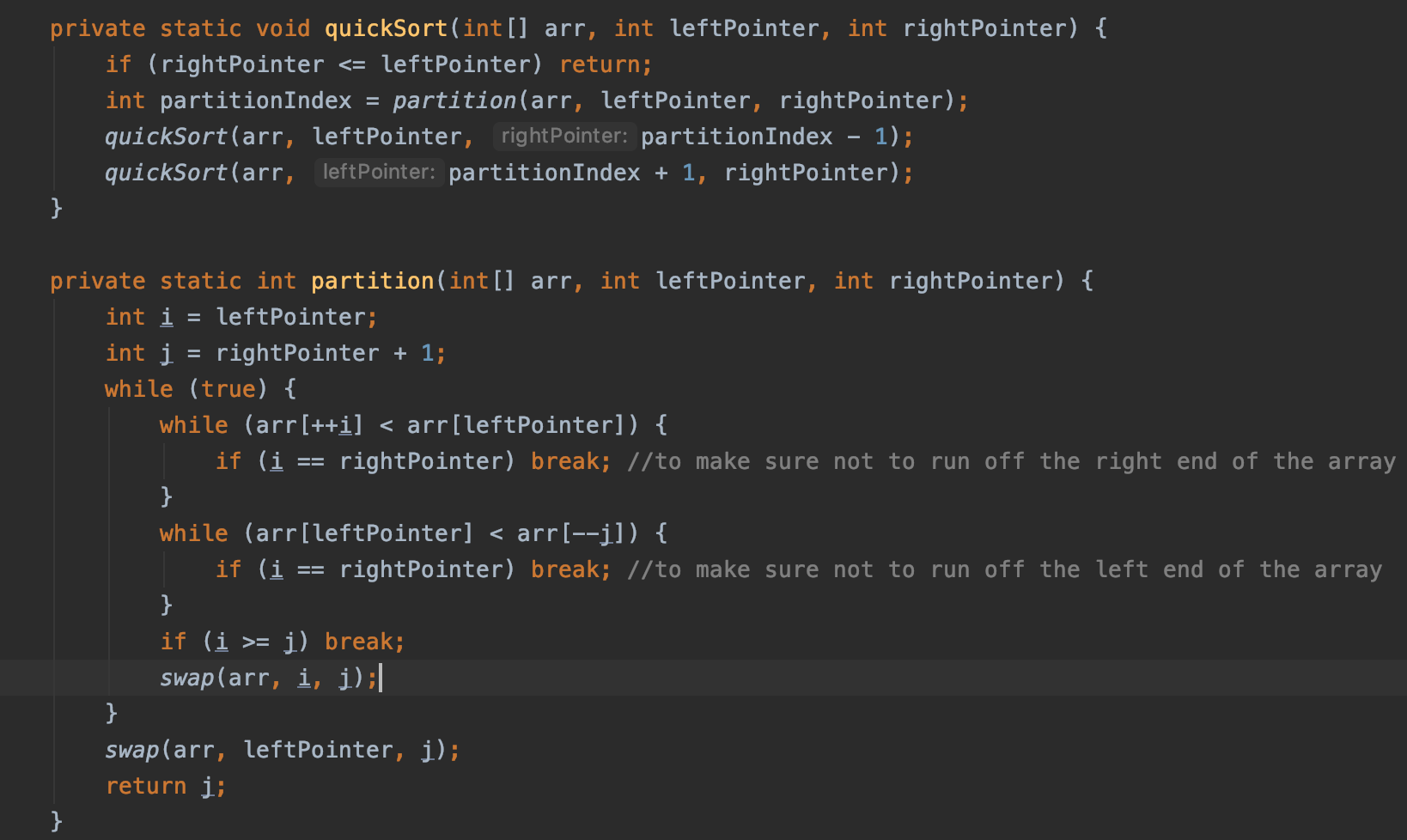 Quicksort implementation
Quicksort implementation
Characteristics of Quicksort:
Quicksort always go in synonymous with the ?most efficient algorithm?. There are two reasons why quicksort is so popular:
- Time complexity:
The performance of quicksort is in order of nlogn for most of the cases. If the list of elements is already in sorted order or nearly sorted order then it takes n comparisons to sort the array.
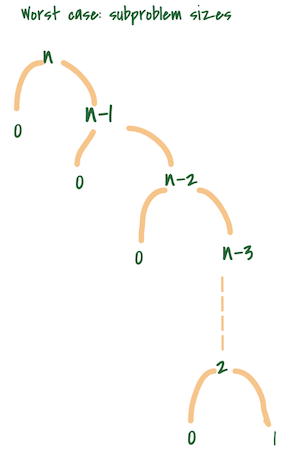
Yes, there are cases where Quicksort performs badly. If the list of elements is already in sorted order or nearly sorted then we might end up in an unbalanced sub-array, to an extent where there is no element on the left greater than the pivot, hence on the right.
Best case Average case Wrost case ————————————————————– O(nlogn) O(nlogn) O(n)
This article discusses the time complexity in detail. I would recommend reading this to get a better perspective.
Analysis of quicksort (article) | Quick sort | Khan Academy
If you’re seeing this message, it means we’re having trouble loading external resources on our website. If you’re?
www.khanacademy.org
Space complexity:
Quicksort has a space complexity of O(logn) even in the worst case when it is carefully implemented such that
- in-place partitioning is used. This requires O(1).
- After partitioning, the partition with the fewest elements is (recursively) sorted first, requiring at most O(logn) space. Then the other partition is sorted using tail-recursion or iteration.
The version of quicksort with in-place partitioning uses only constant additional space before making any recursive call. However, if it has made O(logn) nested recursive calls, it needs to store a constant amount of information from each of them. Since the best case makes at most O(logn) nested recursive calls, it uses O(logn) space. The worst-case makes O(n)nested recursive calls, and so needs O(n) space.
Best case Average case Wrost case ————————————————————– O(logn) O(logn) O(n)
In-place algorithm:
As we have seen above the Quicksort practically needs more than constant O(1) space. It needs memory in order of O(log n) this completely disqualifies quicksort as an in-place algorithm. However, quicksort is always considered to be in-place, it sorts the elements within the array with at most a constant amount of them outside the array at any given time.
Unstable:
Quicksort has one bigger difference with merge sort, and this ends up being a key point between these otherwise similar algorithms. This is the fact that quicksort is an unstable algorithm, meaning that it won?t be guaranteed to preserve the order of elements as it reorders; two elements that are exactly the same in the unsorted array could show up in a reversed order in the sorted one! Stability ends up being what causes people to choose merge sort over quicksort, and it?s the one area where merge sort appears as the obvious winner.
Improvisation to quicksort:
Shuffling the list before sorting:
Shuffling the items of the non-sorted list can give a better guarantee that the list is not nearly or already sorted which make the worst-case performance of the quicksort. Shuffling the item gives better randomness in elements position thereby helping the quicksort to perform better.
Median-of-three partitioning.
A second easy way to improve the performance of quicksort is to use the median of a small sample of items taken from the array as the partitioning item. Doing so will give a slightly better partition but at the cost of computing the median. It turns out that most of the available improvement comes from choosing a sample of size 3 (and then partitioning on the middle item).
Parallel Quicksort:
It is possible to optimize quicksort by running the recursive calls in parallel.
We end up in calling the quicksort on both the left and right partitions of a dataset. The most vital thing is that neither of these two partitions has to be compared to one another after the initial division of elements, we can run both recursive calls on both partitions in parallel.
When we run two quicksort calls in parallel, we are effectively spawning two different tasks in order to run them at the same time. We sort each partition of the array independently, using the same amount of space but only 1/2 the time we did before. This is often referred to as parallel quicksort.
Quicksort is widely approved if you look closer we can see the quick sort is builtin in most of the language?s own sort implementation. Java?s systems programmers have chosen to use quicksort (with 3-way partitioning) to implement the primitive-type methods.
Further Reading:

{kind=link}
{kind=link}