
Powerful deep learning algorithm widely used in sequence modelling
 Photo by ian dooley on Unsplash
Photo by ian dooley on Unsplash
Take about 30 seconds to stare at the above picture. Now close your eyes and try to recall the items you saw in the picture. How many were you able to recall? If you were able to recall all the items then you have a pretty good working memory. Our brains store information like this in the working memory and forgets it after sometime. It is very unlikely that you will remember all these items till tomorrow. Working memory is also sometimes called short-term memory. You use this working memory in lot of daily tasks like organizing your desk, your work, driving, constructing sentences etc. Consider this sentence ? The bus, which went to Paris, was full. To construct this sentence correctly you need to remember that the subject which is the bus is a singular therefore towards the end of the sentence you have to use was. The same sentence with a plural subject becomes ? The buses, which went to Paris, were full. So in many cases you need to remember the context presented at the beginning of the sentence to complete the sentence correctly.
Similar things happen when machines are constructing sentences. We saw how Recurrent Neural Networks are good at sequence tasks like language modelling. RNNs can remember context in the short term well, for example ? There are clouds in the sky. We just need the context cloud in this sentence to complete it and the word clouds is just two steps away from sky. But in the sentence in the previous paragraph the context is farther away. This is where RNNs do not perform well. I will encourage you to read about vanishing and exploding gradients in RNNs to understand this better. In short, RNNs have a short-term memory.
 http://icecreamsoup.thecomicseries.com/comics/25/
http://icecreamsoup.thecomicseries.com/comics/25/
Long Short Term Memory
Long Short Term Memory networks ? usually just called LSTMs ? are a special kind of RNN, capable of learning long-term dependencies. They were introduced by Hochreiter & Schmidhuber (1997), and were refined and popularized by many people in following work. They work tremendously well on a large variety of sequence modelling problems, and are now widely used. LSTMs are explicitly designed to avoid the long-term dependency problem. Remembering information for long periods of time is their default behavior. Lets recall how an RNN looks
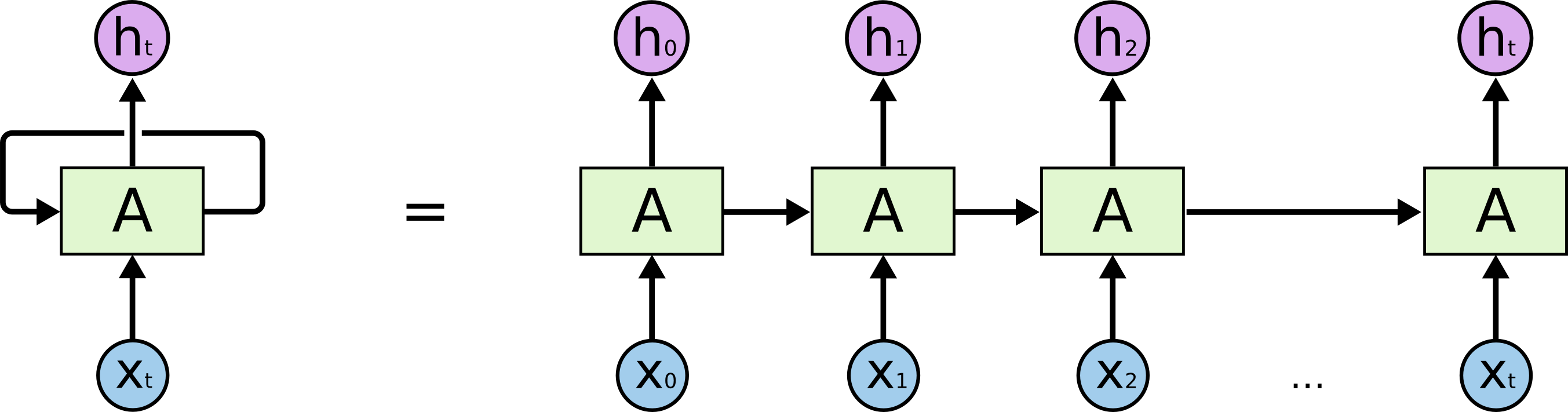
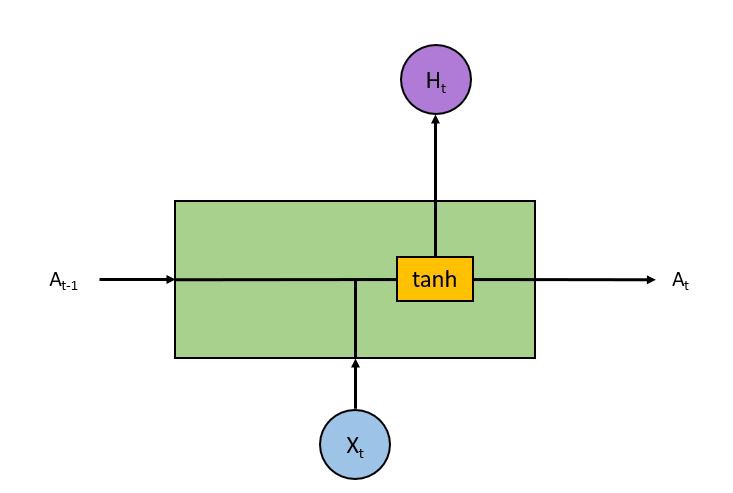
As we saw in the RNN article the RNN unit takes the current input (X) as well as the previous input (A) to produce output (H) and current state (A)
LSTMs also have a similar structure though the internals have different components as compared to a single tanh (activation) layer in the RNN. There are 4 layers inside an LSTM block which interact together.
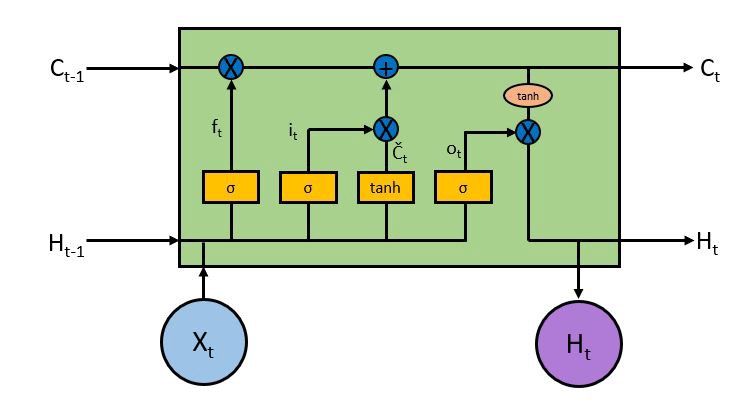
At first it looks pretty complicated and intimidating but lets try to break it down and understand what is the purpose of each layer and block. The key to the operation of LSTM is the top horizontal line running from left to right enclosed in the highlight below.
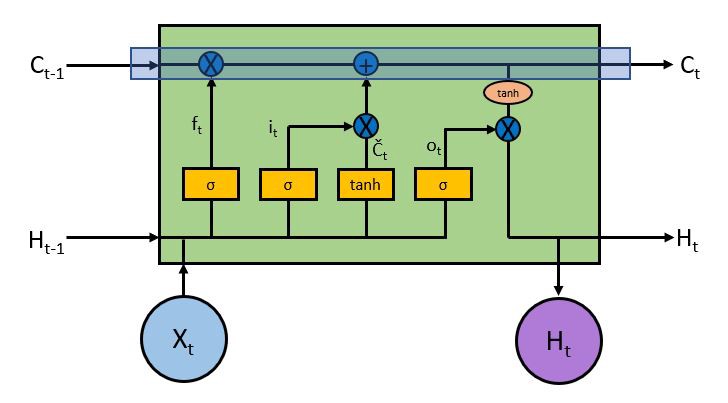
With some minor linear interactions along this line the cell state C allows information to flow through the entire LSTM unchanged which enables LSTM to remember context several time steps in the past. Into this line there are several inputs and outputs which allow us to add or remove information to the cell state. The addition or removal of information is controlled by gates. These are the sigmoid layers (Yellow boxes inside the RNN cell). They output numbers between zero and one, describing how much of each component should be let through. A value of zero means let nothing through, while a value of one means let everything through. An LSTM has three of these gates to control the cell state.
Forget Gate
Lets look at the first gate which is called the forget gate. This gate decides what information we?re going to throw away from the cell state. This is decided by the first sigmoid layer which looks at the previous output and the current input ?
![]() Equation for the forget gate
Equation for the forget gate
Consider a sentence of which we are trying to predict the next word ? Bob called Carla to ask her out. In this sentence the pronoun her is based on the subject Carla and not Bob so the machine while making prediction will have to forget the context Bob when it encounters a new subject Carla. This is what a forget gate accomplishes.
Now the next step involves what are we going to store in the cell state C.
Input Gate
The input gate is another sigmoid layer (Second yellow box from the left in the picture above) which outputs numbers between 0 and 1 and decides which values to update. The candidate values which will be used to update the cell state are calculated by a tanh layer (Third yellow box from the left) and these two are combined to create an update to the state.
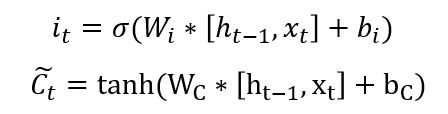
In the sentence example above, we?d want to add the gender of the new subject to the cell state, to replace the old one we?re forgetting.
It?s now time to update the old cell state into the new cell state. The previous steps already decided what to do, we just need to actually do it.
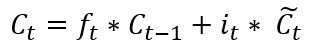
In the case of the language model, this is where we?d actually drop the information about the old subject?s gender and add the new information, as we decided in the previous steps.
Output Gate
Finally, we need to decide what we?re going to output. This output will be based on our cell state, but will be a filtered version. First, we run a sigmoid layer (The rightmost yellow box inside the cell) which decides what parts of the cell state we?re going to output. Then, we put the cell state through a tanh layer to push the values to be between -1 and 1 and multiply it by the output of the sigmoid gate, so that we only output the parts we decided to. Mathematically it looks like ?
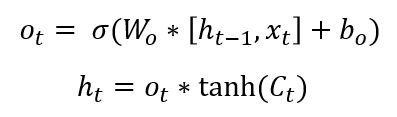
For the language model example, since it just saw a subject, it might want to output information relevant to a verb. For example, in our case Carla is singular so it might output information about singular or plural, so that we know what form a verb should be conjugated into.
Conclusion
LSTMs look pretty intimidating when you look at just the equations or the cell alone. Hopefully, walking through them step by step has made them a bit more easy to understand. The original paper was published in 1997 by Hochreiter & Schmidhuber the link to which is in this article. I found the paper to be very technical and hard to understand but luckily there are lot of resources available on the internet to help understand LSTMs. You can give the original paper a try or head to this beautiful blog written by Christopher Olah.
Understanding LSTM Networks
Posted on August 27, 2015 Humans don’t start their thinking from scratch every second. As you read this essay, you?
colah.github.io
LSTMs are widely used and are very powerful. Essentially when you hear that an RNN is being used in a certain application most likely it will be an LSTM. There is a lot of exciting research around LSTMs like attention, Grid LSTMs etc. So go ahead learn and build your own predictive language model!

X8 aims to organize and build a community for AI that not only is open source but also looks at the ethical and political aspects of it. More such simplified AI concepts will follow. If you liked this or have some feedback or follow-up questions please comment below.
Thanks for Reading!

{kind=link}
{kind=link}