If working with data is part of your daily job, you will likely run into situations where you realize you have to loop through a Pandas Dataframe and process each row. I recently find myself in this situation where I need to loop through each row of a large DataFrame, do some complex computation to each row, and recreate a new DataFrame base on the computation results. Savvy data scientists know immediately that this is one of the bad situations to be in, as looping through pandas DataFrame can be cumbersome and time consuming.
However, in the event where you have no option other than to loop through a DataFrame by rows, what is the most efficient way? Let?s look at the usual suspects:
- for loop with .iloc
- iterrows
- itertuple
- apply
- python zip
- pandas vectorization
- numpy vectorization
When I wrote my piece of code I had a vague sense that I should stay away from iloc, iterrows and try using pandas builtin functions or apply. But I ended up using itertuples because what I was trying to do is fairly complex and could not be written in the form that utilizes apply. It turned out that using itertuple did not satisfy my time constraint, so I Googled around and found the above list of candidates I could potentially try out. I decided to try each of them out and record my findings as well as the reason why some options are more efficient that others.
Experiment results with %timeit
To compair the performance of each approach fairly, I implemented each approach in a Jupyter notebook, and used the magic % timeit function to measure the efficiency of each on a randomly generated DataFrame. For simplicity, each approach is trying to compute the sum of all elements of two of the columns of the DataFrame.
First let?s generate a DataFrame large enough with random integers
import timeitimport pandas as pdimport numpy as npdf = pd.DataFrame(np.random.randint(0, 10, size=(100000, 4)), columns=list(‘ABCD’))
The DataFrame df has a shape of (100000, 4), where the first 5 rows look like
df.head()A B C D0 7 7 9 31 3 6 2 82 5 5 0 63 2 7 9 14 4 3 3 7
For the experiment I am using pandas 0.25.3.
Standard python for loop with iloc
A very basic way to achieve what we want to do is to use a standard for loop, and retrieve value using DataFrame?s iloc method
def loop_with_for(df): temp = 0 for index in range(len(df)): temp += df[‘A’].iloc[index] + df[‘B’].iloc[index] return temp
Check performance using timeit
%timeit loop_with_for(df)
2.01 s 14.7 ms per loop (mean std. dev. of 7 runs, 1 loop each)
Using Jupyter?s prune function we get a detailed analysis on number of function calls and time consumed on each step
%prun -l 4 loop_with_for(df)10200009 function calls (10000007 primitive calls) in 4.566 seconds Ordered by: internal time List reduced from 39 to 4 due to restriction <4> ncalls tottime percall cumtime percall filename:lineno(function) 200000 0.555 0.000 1.035 0.000 frame.py:2964(__getitem__) 200000 0.460 0.000 2.966 0.000 indexing.py:2135(_getitem_axis) 1200000 0.315 0.000 0.481 0.000 {built-in method builtins.isinstance} 1 0.272 0.272 4.565 4.565 <ipython-input-3-4b96483d67ee>:1(loop_with_for)
Seems like with the for loop + iloc approach, most of the time is spent on accessing values of each cell of the DataFrame, and checking data type with python?s isinstance function. Let’s see if we can get some speed up if we switch to using one of the functions pandas provides.
Using pandas iterrows function
The pandas iterrows function returns a pandas Series for each row, with the down side of not preserving dtypes across rows.
def loop_with_iterrows(df): temp = 0 for _, row in df.iterrows(): temp += row.A + row.B return temp
Check performance using timeit
%timeit loop_with_iterrows(df)
9.14 s 59.2 ms per loop (mean std. dev. of 7 runs, 1 loop each)
%prun -l 4 loop_with_iterrows(df)30000101 function calls (29500097 primitive calls) in 17.009 seconds Ordered by: internal time List reduced from 105 to 4 due to restriction <4> ncalls tottime percall cumtime percall filename:lineno(function) 4900013 1.627 0.000 2.911 0.000 {built-in method builtins.isinstance} 3100004 0.938 0.000 1.284 0.000 generic.py:7(_check) 100000 0.669 0.000 12.594 0.000 series.py:197(__init__) 4700006 0.649 0.000 0.975 0.000 {built-in method builtins.getattr}
Surprisingly, the iterrows approach is almost 5 times slow than using standard for loop! The reason, suggested by the above log, is that iterrows spends a lot of time creating pandas Series object, which is known to incur a fair amount of overhead. And yet, the Series it created does not preserve dtypes across rows, which is why it is always recommended to use itertuples over iterrows, if you have to choose between one of them.
Using pandas itertuples function
The pandas itertuples function is similar to iterrows, except it returns a namedtuple for each row, and preserves dtypes across rows.
def loop_with_itertuples(df): temp = 0 for row_tuple in df.itertuples(): temp += row_tuple.A + row_tuple.B return temp
Check performance using timeit
%timeit loop_with_itertuples(df)
110 ms 7.42 ms per loop (mean std. dev. of 7 runs, 10 loops each)
%prun -l 4 loop_with_itertuples(df)301143 function calls (301120 primitive calls) in 0.200 seconds Ordered by: internal time List reduced from 110 to 4 due to restriction <4> ncalls tottime percall cumtime percall filename:lineno(function) 1 0.126 0.126 0.200 0.200 <ipython-input-14-30ae2d632868>:13(loop_with_itertuples) 100000 0.037 0.000 0.072 0.000 __init__.py:403(_make) 100000 0.024 0.000 0.024 0.000 {built-in method __new__ of type object at 0x10919df70}100090/100068 0.011 0.000 0.011 0.000 {built-in method builtins.len}
It is exciting that we are finally getting into miliseconds per loop now! itertuples saves the overhead of creating Series each row by creating namedtuple instead. This is efficient, yet we are still paying for overhead for creating namedtuple.
Using python zip
There is another interesting way to loop through the DataFrame, which is to use the python zip function. The way it works is it takes a number of iterables, and makes an iterator that aggragates elements from each of the iterables. Since a column of a Pandas DataFrame is an iterable, we can utilize zip to produce a tuple for each row just like itertuples, without all the pandas overhead! Personally I find the approach using zip very clever and clean.
def loop_with_zip(df): temp = 0 for a, b in zip(df[‘A’], df[‘B’]): temp += a + b return temp
Check performance using timeit
%timeit loop_with_zip(df)
27.1 ms 2.81 ms per loop (mean std. dev. of 7 runs, 10 loops each)
%prun -l 4 loop_with_zip(df)146 function calls in 0.049 seconds Ordered by: internal time List reduced from 35 to 4 due to restriction <4> ncalls tottime percall cumtime percall filename:lineno(function) 1 0.049 0.049 0.049 0.049 <ipython-input-14-30ae2d632868>:19(loop_with_zip) 1 0.000 0.000 0.049 0.049 {built-in method builtins.exec} 2 0.000 0.000 0.000 0.000 frame.py:2964(__getitem__) 2 0.000 0.000 0.000 0.000 base.py:1185(__iter__)
Now we are talking! We just saved about 4 times by using zip. The efficiency depends on the fact that we are not creating namedtuple for every row. zip simply returns an iterator of tuples.
Using pandas apply function
Of course we can always use the well-known pandas apply function, which is commonly used to do complex operations on DataFrame rows and columns.
def using_apply(df): return df.apply(lambda x: x[‘A’] + x[‘B’], axis=1).sum()
Check performance using timeit
%timeit using_apply(df)
2.6 s 587 ms per loop (mean std. dev. of 7 runs, 1 loop each)
%prun -l 4 using_apply(df)8401975 function calls (8001949 primitive calls) in 4.559 seconds Ordered by: internal time List reduced from 215 to 4 due to restriction <4> ncalls tottime percall cumtime percall filename:lineno(function) 200000 0.506 0.000 2.942 0.000 base.py:4702(get_value) 1 0.342 0.342 4.556 4.556 {pandas._libs.reduction.reduce} 400002 0.306 0.000 0.811 0.000 {pandas._libs.lib.values_from_object} 200000 0.299 0.000 3.357 0.000 series.py:1068(__getitem__)
We are seeing about the same performance as using standard loops. According to this stack overflow post, apply is still doing row operations and creating Series, which explains why the function calls are mostly getting values from Series. This is surprising as I always thought apply is one of the more efficient functions if one needs to do row operations.
Using pandas builtin add function
If what we are actually doing is just adding two columns and computing total sum, using the pandas built-in add and sum function would have been the obvious way. Unfortunately many computations we do does not have a simple built-in operation in Pandas. But this approach gives us a good indicator of how efficient these Pandas built-in functions are in practice.
def using_pandas_builtin(df): return (df[‘A’] + df[‘B’]).sum()
Check performance using timeit
%timeit using_pandas_builtin(df)
567 s 81.4 s per loop (mean std. dev. of 7 runs, 1000 loops each)
%prun -l 4 using_pandas_builtin(df)645 function calls (642 primitive calls) in 0.002 seconds Ordered by: internal time List reduced from 141 to 4 due to restriction <4> ncalls tottime percall cumtime percall filename:lineno(function) 1 0.000 0.000 0.000 0.000 {built-in method _operator.add} 2 0.000 0.000 0.000 0.000 {method ‘reduce’ of ‘numpy.ufunc’ objects} 105 0.000 0.000 0.000 0.000 {built-in method builtins.isinstance} 51 0.000 0.000 0.000 0.000 generic.py:7(_check)
Since pandas functions are highly optimized, it is expected to be very efficient. This also shows that if your complex operation can be broken down to a series of pandas builtin functions, then it might make more sense to go that route than trying to jam all the operations in a lambda function then use apply.
Using numpy builtin function
And eventually, if you are really looking for efficiency and speed, always go to numpy. Here we convert each column into a numpy array, and does all the heavy lifting utilizing numpy?s builtin functionalities. It?s known to be more efficient than Pandas Dataframe operations.
def using_numpy_builtin(df): return (df[‘A’].values + df[‘B’].values).sum()
Check performance using timeit
%timeit using_numpy_builtin(df)
272 s 41.5 s per loop (mean std. dev. of 7 runs, 1000 loops each)
%prun -l 4 using_numpy_builtin(df)37 function calls in 0.001 seconds Ordered by: internal time List reduced from 21 to 4 due to restriction <4> ncalls tottime percall cumtime percall filename:lineno(function) 1 0.000 0.000 0.001 0.001 <ipython-input-14-30ae2d632868>:31(using_numpy_builtin) 1 0.000 0.000 0.000 0.000 {method ‘reduce’ of ‘numpy.ufunc’ objects} 1 0.000 0.000 0.001 0.001 {built-in method builtins.exec} 2 0.000 0.000 0.000 0.000 frame.py:2964(__getitem__)
And of course, the clear winner of this contest is the approach using numpy.
What about DataFrame with different size
Now we have a good understanding of the efficiency of each approach, a natural question to ask is: how large the DataFrame needs to be for us to start considering trying a more efficient approach? To answer that question, I ran an experiment on DataFrames with different sizes, from 1000 rows to 40000 rows. The results are summarized in the plot below.
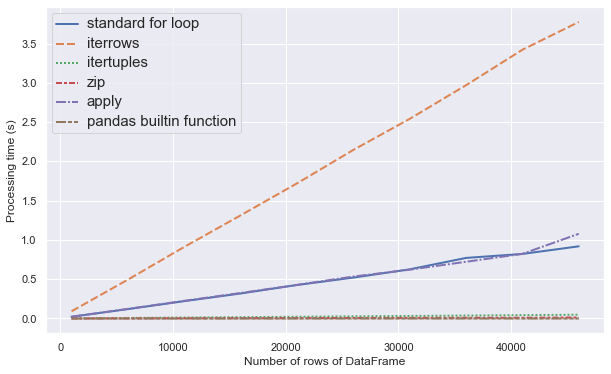
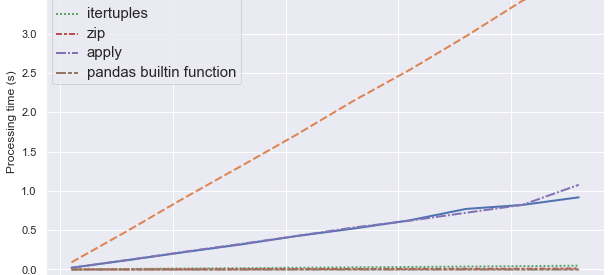
From the plot we can see that iterrows is the least efficient and computation time grows the fastest. Then on second tier we have the apply function and standard for loop, which have almost same performance. Then the most efficient approaches are pandas and numpy built-in functions, the performance of which are very consistent despite increasing number of rows. Close seconds are zip and itertuples, with zip approach slightly faster than itertuples. (numpy approach is not drawn on the plot due to its running time being miniscule.)
Here is a table with the performance details of the experiment.
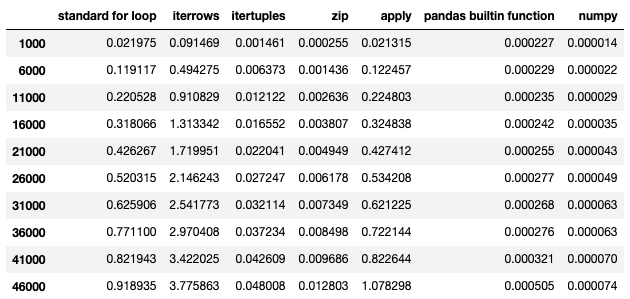
For simple operations like what we do here (adding two columns), the difference in performance starts to show once we get to 10000 rows-ish. For more complicated operations, it seems reasonable to start thinking efficiency once you get to about 5000 rows.
Additional Insights
how to use apply
I noticed that there are different ways one can use the apply function in our context, and how we use them actually makes a difference in terms of performance. Let?s take a look.
For the sake of illustration, I modified the using_apply function from above to compute sum of all columns instead of just columns ‘A’ and ‘B’.
def using_apply(df): return df.apply(lambda x: x[‘A’] + x[‘B’] + x[‘C’] + x[‘D’], axis=1).sum()def using_apply_unpack(df): return df[[‘A’, ‘B’, ‘C’, ‘D’]].apply(lambda x: sum([*x]), axis=1).sum()
The main difference between the above two function is the way we access each column value. In using_apply, we does apply on each row, then access each column value separately, whereas in the other function, we only pass in the relevant columns, and unpack the row to get all columns at the same time. On first look, I did not think this would make a difference, and boy I was wrong. Running both function on a DataFrame of size (100000, 4) yields the following results.
%timeit using_apply(df)
4.05 s 502 ms per loop (mean std. dev. of 7 runs, 1 loop each)
%timeit using_apply_unpack(df)
1.81 s 27.3 ms per loop (mean std. dev. of 7 runs, 1 loop each)
The difference it more than 2 times! We get some savings of accessing all columns by unpacking rather than accessing one by one. If you need to use apply, then bear in mind that these little details could give you a fair amount of efficiency boost!
source code comparison
Sometimes, to figure out what is going on, it is helpful to look at the source codes. I included some of the source codes of the functions here for readers who are interested.
iterrows
For readers who are interested, this is the iterrows source code for iterrows
columns = self.columnsklass = self._constructor_slicedfor k, v in zip(self.index, self.values): s = klass(v, index=columns, name=k) yield k, s
The klass object here is actually the Series class. And it is interesting to see that iterrows also uses zip, except it is using it to create Series by zipping index and values together. This partly explains why zip beats iterrows by so much.
itertuples
For readers who are interested, this is the itertuples source code for itertuples
arrays = fields = list(self.columns)if index: arrays.append(self.index) fields.insert(0, “Index”)# use integer indexing because of possible duplicate column namesarrays.extend(self.iloc[:, k] for k in range(len(self.columns)))# Python 3 supports at most 255 arguments to constructorif name is not None and len(self.columns) + index < 256: itertuple = collections.namedtuple(name, fields, rename=True) return map(itertuple._make, zip(*arrays))# fallback to regular tuplesreturn zip(*arrays)
zip
For readers who are interested, this is the zip source code for python?s zip function
def zip(*iterables): # zip(‘ABCD’, ‘xy’) –> Ax By sentinel = object() iterators = [iter(it) for it in iterables] while iterators: result = for it in iterators: elem = next(it, sentinel) if elem is sentinel: return result.append(elem) yield tuple(result)
References
- https://pandas.pydata.org/pandas-docs/stable/user_guide/enhancingperf.html
- https://stackoverflow.com/questions/52673285/performance-of-pandas-apply-vs-np-vectorize-to-create-new-column-from-existing-c
- https://towardsdatascience.com/how-to-make-your-pandas-loop-71-803-times-faster-805030df4f06


{kind=link}
{kind=link}