

What is semi-supervised learning?
Every machine learning algorithm needs data to learn from. But even with tons of data in the world, including texts, images, time-series, and more, only a small fraction is actually labeled, whether algorithmically or by hand.
Most of the time, we need labeled data to do supervised machine learning. I particular, we use it to predict the label of each data point with the model. Since the data tells us what the label should be, we can calculate the difference between the prediction and the label, and then minimize that difference.
As you might know, another category of algorithms called unsupervised algorithms don?t need labels but can learn from unlabeled data. Unsupervised learning often works well to discover new patterns in a dataset and to cluster the data into several categories based on several features. Popular examples are K-Means and Latent Dirichlet Allocation (LDA) algorithms.
Now imagine you want to train a model to classify text documents but you want to give your algorithm a hint about how to construct the categories. You want to use only a very small portion of labeled text documents because every document is not labeled and at the same time you want your model to classify the unlabeled documents as accurately as possible based on the documents that are already labeled.
Thankfully, there is a class of algorithms called semi-supervised algorithms, which are able to learn from partially labeled data sets.
Text-documents are a particularly abundant form of unlabeled data, including volumes and volumes of scripts, books, blogs, etc., which are mostly unlabeled. We know that labelling a lot of data is expensive. (For example, imagine the time it would take for someone to read through ten-thousands articles just to attribute one special class to that text-document.)
What is adversarial training?
In April 2017, Miyato et al presented a new method that allows semi-supervised learning, namely: Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning. Their work is closely related to the work presented by Goodfellow et al in their paper Explaining and Harnessing Adversarial Examples.
In the following article, I?ll introduce the adversarial training method using example images and text. If you?re interested in learning more, check out the research papers linked above.
Goodfellow?s paper notes that we can easily perturb a neural image classifier by adding some noise to the input image. This ?noise? can be so small that we can?t detect it with the naked eye, though the neural classifier can. In fact, we can deliberately try to introduce noise that will maximize the ?failure? of the classifier, prompting it to incorrectly identify a given image.
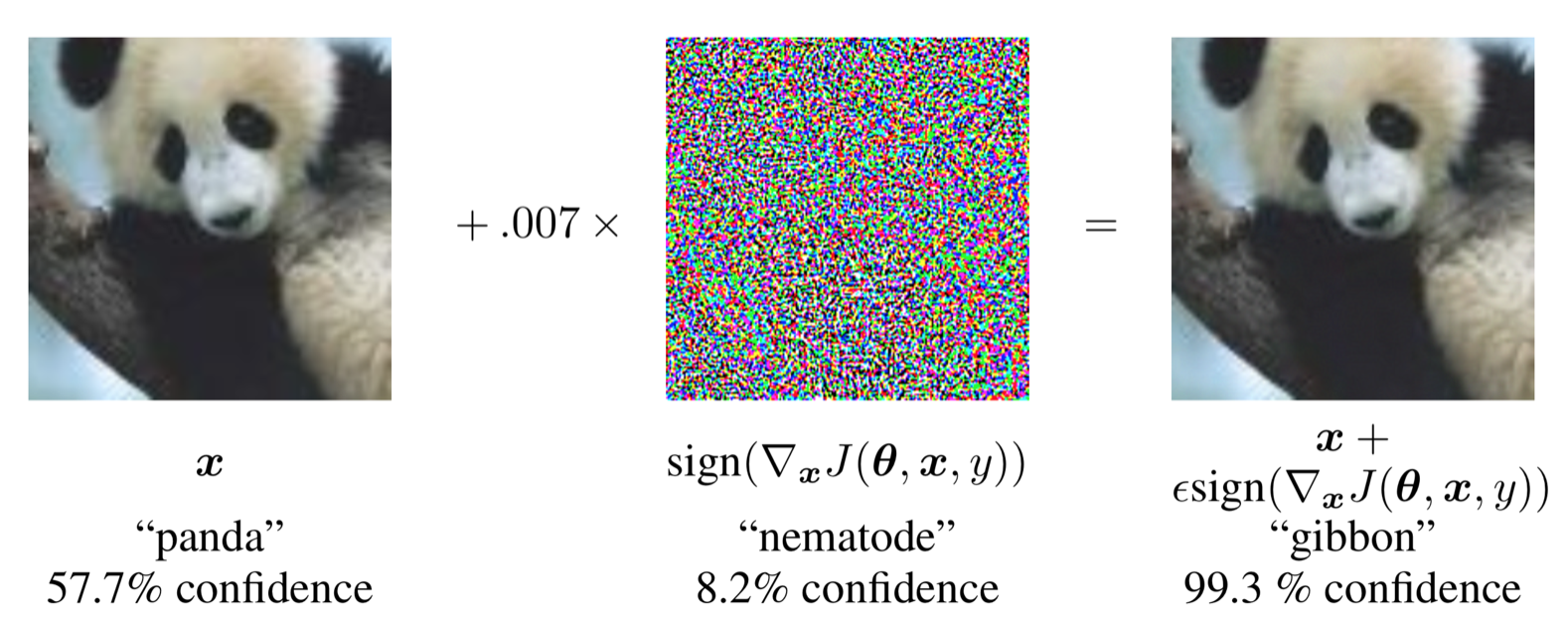 Figure 1. from Goodfellow et al, Explaining and Harnessing Adversarial Examples
Figure 1. from Goodfellow et al, Explaining and Harnessing Adversarial Examples
The introduction of this seemingly insignificant noise tweaks the image classifier into identifying the panda as a gibbon with over 99% confidence.
So how can we improve the model?
One approach is to continue to train our model on our image set but during the training we will generate adversarial noise that we add to the image. Since we?re training our model, we still know all the labels of our images and we can train the model to classify the images according to the specific label even when the image contains particular noise.
This method of ?adversarial training? helps generalize the model and makes it more robust against noise that the images might include. It therefore makes the model less likely to make wrong predictions when images outside the training set contain perturbations.
Miyato and his team applied these ideas to do ?virtual adversarial training? for semi-supervised learning, which is a particularly great fit for models that have to contend with sparsely labeled data. With ?virtual adversarial training?, we don?t use the labels of our training set but rather the conditional probability that an image will have label X. In other words, when we input an image of a panda and our model predicts that we have 40% panda, 20% bird, 1 % car, and so on, that distribution itself becomes the label during adversarial training. This means that we add noise to the image with the adversarial method but we still tell our classifier that the correct label is: 40% panda, 20% bird, 1 % car, and so on.
This allows us to do semi-supervised learning. For images with labels, we can follow the previous adversarial example and tell the model that we know the label. And for unlabeled images, we let our model predict the labels (40% panda, 20% bird, 1 % car, and so on) and then we use that to perturb our images. As explained above, our adversarial method tries to makes the model fail the most and in this case the model tries to make perturbations to the image that maximize the divergence between the predicted label and the correct label distribution.
Let?s dive into the math for a moment.
We predicted P(Label|Features)for the unlabeled image and we are trying to find the perturbation that maximizes the divergence between that distribution and the distribution of the prediction with perturbation. In this example, we use the Kullback?Leibler divergence, denoted as KL:
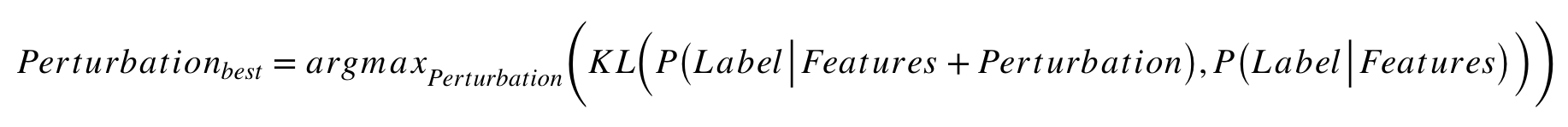
Given this best perturbation we try to minimize the loss function defined by:

This last function is the virtual adversarial loss function that we can add to any regular loss function to work as a regularization.
Examples of an Application for Semi-supervised Text Classifier
With that function in hand, we can work on a semi-supervised document classifier.
Preparation:Let?s start with our data. We will work with texts and we need to represent the texts numerically. Texts are can be represented in multiple ways but the most common is to take each word as a discrete feature of our text.
Consider two text documents. One says: ?I am hungry? and the other says ?I am sick?. To represent this as features, we know that in both texts we have 4 different words, namely: I, am, hungry and sick. Those words will now be our features. We can represent each word as a 1 or a 0 depending on whether or not it is present in the document.
This will give us the following one-hot encoded representation for both documents:
?I am hungry?: (1,1,0,1)
?I am sick?: (1,1,1,0)
As you can imagine, the more different words we have in our documents the more features we will have for our numerically represented texts! This can get ugly very quickly.
Fortunately, as an alternative, we can represent those documents with a word embedding. A word embedding is basically a dense n-dimensional vector representation, as opposed to the sparse one-hot encoded representation. For our purpose, we represent the words in a 300-dimensional space. In addition to the numerical representations, the word embedding also ?learns? to regroup semantically close words inside that space. This means that words with a similar meaning, are often closely regrouped in that 300-dimensional space in contrast to the more ?primitive? one-hot encoded method. For more details about word-embeddings and how to generate them, check out this great article.
Model:Let?s look at the model presented by Miyato et al within Adversarial Training Methods for semi-supervised Text Classification, which relies on the virtual adversarial training mentioned earlier. As a help, the authors have also uploaded the model to a GitHub repository.
The presented model from the paper has the following structure:
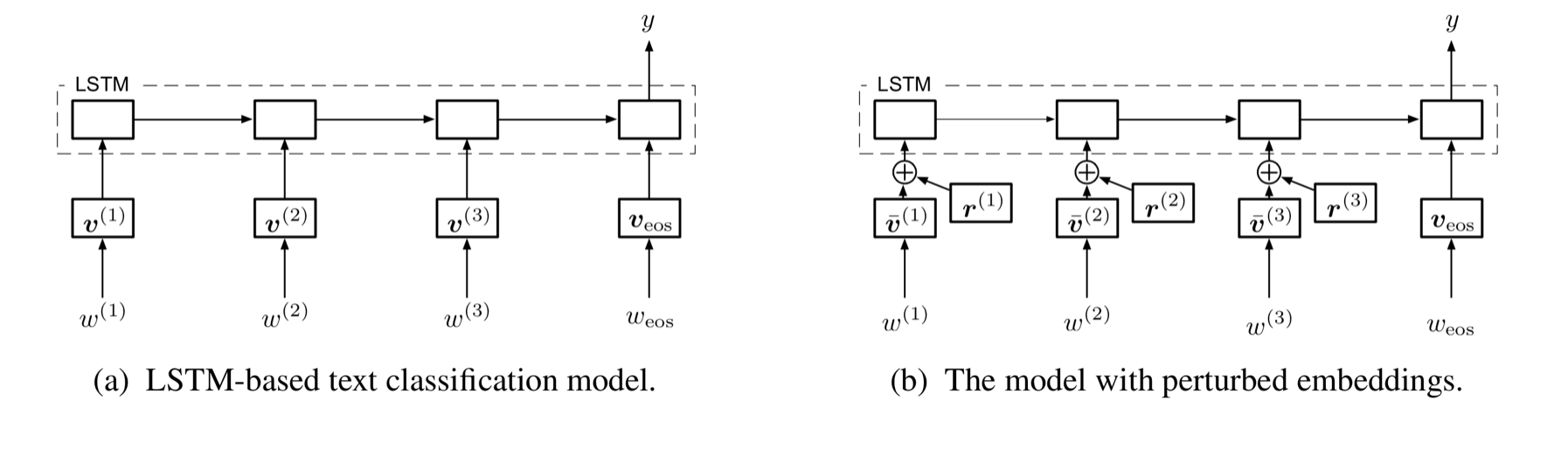 Figure 2. from Miyato et al, in Adversarial Training Methods for semi-supervised Text Classification
Figure 2. from Miyato et al, in Adversarial Training Methods for semi-supervised Text Classification
This structure shows the need for the word-embedding earlier. It makes little sense to perturb words with noise, and it?s not clear how you would do it. Replace words? Replace characters?
Instead we perturb our 300-dimensional vectors with our perturbation vector r of the same size. We use the same principle here as we did with the panda. Specifically, we try to perturb the word embedding such that our model makes the worst prediction possible. Since we have a dense vector, we can perturb each feature of that vector to a small degree to cause our model to fail on the classification task.
For the classification model, we use a simple LSTM that takes as input the words which have been embedded. It outputs our class Y. In Figure 2., Veos represents the end of the sentence token, which marks the end of our sentence and helps to improve the classification.
Training:As before, we train our model using virtual adversarial training, which means that we have labeled and unlabeled text documents. Based on those documents, our model tries to find the best perturbation r, which will make our model fail, and it learns from that. The process is identical to the one we have for our image classifier except that we perturb a word-embedding instead of the pixels of an image.
Effectively, the use of unlabeled data allows us to make the model more general than what it would be without this additional data.
To integrate this into our model, we add an additional term to our loss function. I explained the additional loss term previously, so we can reuse this:

A handy way to explain this: the model wants to minimize the loss function by classifying the labelled data as well as possible using categorical cross-entropy. However, with the additional virtual loss, the model gets penalized if it grows too sure about (or overfits) the decisions it makes. The virtual loss will show the model that once we introduce an example with specific noise, the model can fail and the model should take that into account as well. This makes the model learn from the labelled data to be as precise as possible but it also learns that similar data points with small perturbations (adversarial perturbations) should be correctly classified. Remember the example of the panda image? Our brain didn?t consider the noise and for us this is still clearly a panda. That is exactly what we want the model to achieve for our training examples.
Some Results:In the course of this work, I played around with the DBpedia Data-Set (14 classes with around 560,000 training files and 70,000 test files).
Some results:
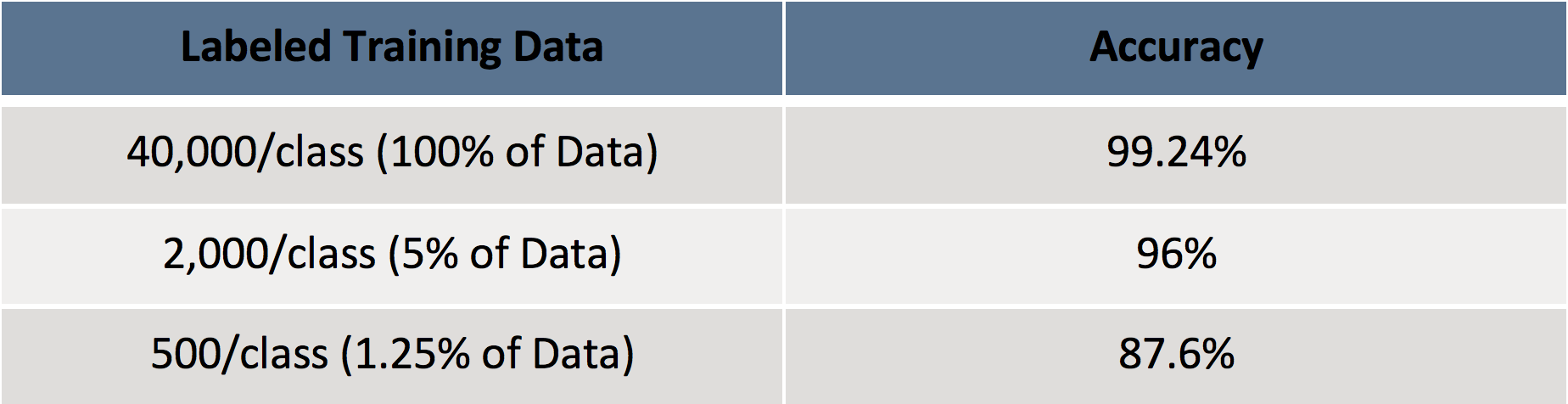
I didn?t compare my model to a regular classifier without supervised learning since this was specifically an exploratory project, but it would definitely be helpful to compare this to a classifier that has not used all the data. Then again, the results might change drastically depending on what data we take as labelled data.
However, I wanted to show that by using only a fraction of labelled data it?s possible to get acceptable results with this regularization. Plus, the model is better prepared for adversarial attacks ? though admittedly being prepared in that way might not be as useful for text classifiers as it is for other models.
Final thoughts
This method is extremely powerful when doing semi-supervised learning. It allows us to leverage unlabeled data, which is crucial in most business cases since in a lot of cases we don?t have enough labelled data. When we do have some labeled data, we might still have a big chunk of data with missing labels that we want to leverage to improve the model.
Although it wasn?t the focus of this post, it?s worth mentioning how robust these methods are against adversarial attacks. Imagine people that want to make your model fail on purpose by feeding it adversarial examples. In most cases the effects are harmless but imagine an adversarial attack on a self-driving car. The car could be tricked into changing lanes or even making wrong turns simply with adversarial stickers on some signs.
This is a huge topic and if we want to go into the direction of trusting AI, we need to make sure that models can ?defend? themselves against such attacks. IBM?s Research Team has published ?ART? (Adversarial Robustness Toolbox), an open source Python library to make models robust against adversarial attacks by training them in similar ways to those described above. If you want an easy library to improve the model, I suggest checking it out!
Thanks for reading. To learn more about Deep Learning, check out my other article about the Transformer.
Happy Learning!

{kind=link}
{kind=link}